Пройти тестирование по этим заданиям
Вернуться к каталогу заданий
Версия для печати и копирования в MS Word
1
Какой минимальный объём памяти (в Кбайт) нужно зарезервировать, чтобы можно было сохранить любое растровое изображение размером 128×128 пикселей при условии, что в изображении могут использоваться 256 различных цветов? В ответе запишите только целое число, единицу измерения писать не нужно.
2
Какой минимальный объём памяти (в Кбайт) нужно зарезервировать, чтобы можно было сохранить любое растровое изображение размером 128×128 пикселей при условии, что в изображении могут использоваться 128 различных цветов? В ответе запишите только целое число, единицу измерения писать не нужно.
3
Какой минимальный объём памяти (в Кбайт) нужно зарезервировать, чтобы можно было сохранить любое растровое изображение размером 512×512 пикселей при условии, что в изображении могут использоваться 256 различных цветов? В ответе запишите только целое число, единицу измерения писать не нужно.
4
Какой минимальный объём памяти (в Кбайт) нужно зарезервировать, чтобы можно было сохранить любое растровое изображение размером 1024×1024 пикселей при условии, что в изображении могут использоваться 16 различных цветов? В ответе запишите только целое число, единицу измерения писать не нужно.
5
Какой минимальный объём памяти (в Кбайт) нужно зарезервировать, чтобы можно было сохранить любое растровое изображение размером 320×640 пикселей при условии, что в изображении могут использоваться 256 различных цветов? В ответе запишите только целое число, единицу измерения писать не нужно.
Источник: ЕГЭ по информатике 23.03.2016. Досрочная волна
Пройти тестирование по этим заданиям
На уроке рассматривается разбор 8 задания ЕГЭ по информатике про измерение количества информации
8-е задание: «Измерение количества информации»
Уровень сложности
— базовый,
Требуется использование специализированного программного обеспечения
— нет,
Максимальный балл
— 1,
Примерное время выполнения
— 4 минуты.
Проверяемые элементы содержания: Знание о методах измерения количества информации
До ЕГЭ 2021 года — это было задание № 10 ЕГЭ
Типичные ошибки и рекомендации по их предотвращению:
«При использовании способа решения со системой счисления с основанием N следует помнить, что слова в списке нумеруются с единицы, поэтому числу 0 будет соответствовать первое слово»
ФГБНУ «Федеральный институт педагогических измерений»
Содержание:
- Объяснение темы
- Измерение количества информации
- Двоичное кодирование сообщений (равновероятностные события)
- Количество различных сообщений в алфавите разной мощности
- Количество сообщений при различном вхождении (встречаемости) букв
- Дополнительные формулы
- Тренировочные задания 8 ЕГЭ по информатике и их решение
- Сколько вариантов шифра или кодовых слов
- Перестановка букв в слове (каждая буква 1 раз)
- Сколько существует n-значных чисел, записанных в m-ной системе счисления
- Список в алфавитном порядке
- Вероятность событий
Объяснение темы
Рассмотрим кратко необходимые для решения 8 задания ЕГЭ понятия и формулы.
Измерение количества информации
- Кодирование — это представление информации в форме, удобной для её хранения, передачи и обработки. Правило преобразования информации к такому представлению называется кодом.
- 1 бит – это количество информации, которое можно передать с помощью одного знака в двоичном коде (0 или 1).
- Алфавит — это набор знаков, используемый в том или ином языке.
- Мощность алфавита — это количество используемых в алфавите знаков.
- Сообщение — это любая последовательность символов какого-либо алфавита.
1 байт (bytе) = 8 бит
1 Кб (килобайт) = 1024 байта
1 Мб (мегабайт) = 1024 Кб
1 Гб (гигабайт) = 1024 Мб
1 Тб (терабайт) = 1024 Гб
1 Пб (петабайт) = 1024 Тб
8 = 23
1024 = 210
Рассмотрим еще несколько определений:

Мощность алфавита
Для вычисления количества информации применяются несколько различных формул в зависимости от ситуации:
Двоичное кодирование сообщений (равновероятностные события)
При вычислении количества информации в сообщении для равновероятностных событий, общее количество которых равно N, используется формула:
N = 2L
* следует иметь в виду, что также приняты следующие обозначения: Q = 2k
Пример 2: Зашифруем буквы А, Б, В, Г при помощи двоичного кодирования равномерным кодом и посчитаем количество возможных сообщений:

Решение:
Таким образом, мы получили равномерный код, т.к. длина каждого кодового слова одинакова для всех кодовых слов (L = 2).
Количество сообщений длиной L битов:
N = 2L
Т.е. количество сообщений длиной 2 бита, как в примере с нашими буквами, будет равно N = 22 = 4
Ответ: 4
Количество различных сообщений в алфавите разной мощности
Рассмотрим вариант с 5 буквами (мощность алфавита = 5), которые надо разместить в сообщении длиной 2 символа:

Найдем формулу для нахождения количества различных сообщений в алфавите различной мощности:
Если мощность некоторого алфавита составляет N, то количество различных сообщений длиной L знаков:

- N – мощность алфавита
- L – длина сообщения
- Q – количество различных сообщений
Пример: Сколько существует всевозможных трехбуквенных слов в английском языке?
Решение:
В английском алфавите 26 букв. Значит, мощность алфавита = 26. Длина сообщения = 3. Найдем по формуле количество трехбуквенных слов:
Q = 263
или
26
*
26
*
26
= 17576
Ответ: 17576
N = n1 * n2 * … * nL
Количество сообщений при различном вхождении (встречаемости) букв
В таком случае можно использовать формулу для вычисления числа перестановок с повторениями; для двух разных символов она выглядит так:
[ P = frac{na+n*!}{na!n*!} ]
na – количество букв a n* — количество звёздочек или кол-во вариантов
Иногда в заданиях 8 можно использовать формулу комбинаторики для проверки полученных результатов перебора. Число сочетаний из n элементов по k элементов:
[ C{binom{k}{n}}= frac{n!}{k!(n-k)!} ]
n! = 1 * 2 * 3 * … * n
Пример: Сколько существует всевозможных четырехбуквенных слов в алфавите из 4 букв: А, Б, В, Г, если известно, что буква А встречается ровно два раза?
Решение:
- Длина сообщения = 4. Мощность алфавита = 4. Но мешает условие: буква А встречается ровно два раза.
- В таких заданиях можно использовать способ перебора всевозможных вариантов:
два раза буква А, на остальных местах - одна из трех оставшихся букв: А А 3 3 = 3 * 3 = 32 = 9 А 3 А 3 = 9 А 3 3 А = 9 3 А А 3 = 9 3 А 3 А = 9 3 3 А А = 9
Число сочетаний из n элементов по k элементов:
[ C{binom{k}{n}}= frac{n!}{k!(n-k)!} ]
[ C{binom{2}{4}}= frac{4!}{2!(4-2)!} = frac{24}{2*2} = 6 ]
* Факториал числа n! = 1 * 2 * 3 *..* n
6 * 9 = 54
Дополнительные формулы
Количество информации и равновероятные события
При определении количества информации для равновероятностных событий могут понадобиться две формулы:
x = log2(1/p)
p(A) = m / n
Количество информации и неравновероятные события
При использовании неравновероятного события, вероятность которого равна p, для вычисления количества информации используется формула:
i = -[log2p]
*квадратные скобки означают ближайшее целое, меньшее или равное значению выражения в скобках
Формула Хартли:

Формула Хартли
Алфавитный подход:
Информационный объем сообщения длиной L:

Алфавитный подход
Плейлист видеоразборов задания на YouTube: 
Задание демонстрационного варианта 2022 года ФИПИ
Сколько вариантов шифра или кодовых слов
Cartesian(n) — метод расширения последовательности, возвращающий декартову степень множества символов |
Когда применяется: Если требуется полный перебор вариантов букв для каждой позиции (каждая буква может встречаться в кодовом слове любое количество раз) |
||||||
|---|---|---|---|---|---|---|---|
| Пример: Сравним полный перебор букв слова «школа», размещенных на две позиции: |
|||||||
| Pascal | PascalABC.NET | ||||||
|
|
||||||
| Результат: | |||||||
|
[ш,ш] [ш,к] [ш,о] [ш,л] [ш,а] [к,ш] [к,к] [к,о] Итого 25 штук (5*5) |
[ш,ш] [ш,к] [ш,о] [ш,л] [ш,а] [к,ш] [к,к] [к,о] [к,л] [к,а] [о,ш] [о,к] [о,о] [о,л] [о,а] [л,ш] [л,к] [л,о] [л,л] [л,а] [а,ш] [а,к] [а,о] [а,л] [а,а] |
||||||
Permutations — метод возвращает все перестановки множества элементов, заданного массивом или последовательностью |
Когда применяется: Если требуется перестановка букв в слове. То есть количество каждой буквы в словах сохраняется, и каждая буква встречается только 1 раз |
||||||
| Пример: Сравним перестановку букв слова «мимикрия»: |
|||||||
| Pascal | PascalABC.NET | ||||||
|
|
|
||||||
| Результат: | |||||||
|
[М,И,М,И,К,Р,И,Я] [М,И,М,И,К,Р,Я,И] [М,И,М,И,К,И,Р,Я] [М,И,М,И,К,И,Я,Р] [М,И,М,И,К,Я,Р,И] [М,И,М,И,К,Я,И,Р] [М,И,М,И,Р,К,И,Я] [М,И,М,И,Р,К,Я,И] … |
Используются также следующие запросы и методы LINQ:
Фильтрация последовательностей (Where)
Метод Count([Type -> boolean]) Вычисление скаляра
Метод CountOf(s: Type) — Возвращает количество элементов, равных указанному значению
Метод First() — Возвращает первый элемент последовательности.
Метод Last() — Возвращает последний элемент последовательности.
Метод Pairwise(Self: sequence of T; func: (T,T)->Res) — Превращает последовательность в последовательность пар соседних элементов, применяет func к каждой паре полученных элементов и получает новую последовательность
8_1:
Шифр кодового замка представляет собой последовательность из пяти символов, каждый из которых является цифрой от 1 до 6.
Сколько различных вариантов шифра можно задать, если известно, что цифра 1 должна встречаться в коде ровно 1 раз, а каждая из других допустимых цифр может встречаться в шифре любое количество раз или не встречаться совсем?
Типовые задания для тренировки
✍ Решение:
✎ Решение теоретическое:
- Формула нахождения количества различных сообщений:
- Итак, что у нас дано из этой формулы:
- Длина сообщения (L) = 5 символов
- Мощность алфавита (N) = 6 (цифры от 1 до 6).
- Но так как цифра 1 встречается по условию ровно один раз, а остальные 5 цифр — любое количество раз, то будем считать, что N = 5 (цифры от 2 до 6, исключая 1). Т.е. возьмем вариант, когда 1 стоит на первом месте, а остальные 5 цифр размещаем на 4 позиции:
Q = NL
1 5 5 5 5 - 1 * Q = 54 = 625
✎ 1 способ. Найдем количество вариантов методом перебора:
1 5 5 5 5 -1 * Q=54= 625 5 1 5 5 5 -1 * Q=54= 625 5 5 1 5 5 -1 * Q=54= 625 5 5 5 1 5 -1 * Q=54= 625 5 5 5 5 1 -1 * Q=54= 625
✎ 2 способ. Найдем количество вариантов при помощи формулы комбинаторики:
[ C{binom{4}{5}}= frac{5!}{4!(5-4)!} = 5 ]
625 * 5 = 3125
Результат: 3125
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
|
С++:
|
Детальный теоретический разбор задания 8 ЕГЭ по информатике предлагаем посмотреть в видеоуроке:
📹 YouTube здесьздесь (теоретическое решение)
8_2:
Шифр кодового замка представляет собой последовательность из пяти символов, каждый из которых является либо буквой (A или B) или цифрой (1, 2 или 3).
Сколько различных вариантов шифра можно задать, если известно, что в коде присутствует ровно одна буква, а все другие символы являются цифрами?
✍ Решение:
-
✎ Решение теоретическое:
- Формула нахождения количества различных сообщений:
- Посчитаем количество возможных шифров для одного из вариантов (например, когда буквы находятся на первой позиции). Так как цифры (1, 2, 3) могут занимать 4 позиции из пяти, а две буквы (А и В) одну из позиций, значит:
Q = NL
Q = 2 * 34 = 162
AB 123 123 123 123 = 162
"2" означает одна из двух букв: А или B, "3" - одна из трех цифр: 2 3 3 3 3 -> Q = 2 * 34 = 162 3 2 3 3 3 -> Q = 2 * 34 = 162 3 3 2 3 3 -> Q = 2 * 34 = 162 3 3 3 2 3 -> Q = 2 * 34 = 162 3 3 3 3 2 -> Q = 2 * 34 = 162
5 * 162 = 810
Результат: 810
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
Cartesian(5) — метод расширения последовательности, возвращающий декартову степень множества символов, т.е. в нашем случае перебор 5-знаковых слов из заданных символов * LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
| С++: |
Подробное теоретическое решение данного задания предлагаем посмотреть на видео:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_3:
Олег составляет таблицу кодовых слов для передачи сообщений, каждому сообщению соответствует своё кодовое слово. В качестве кодовых слов Олег использует 4-буквенные слова, в которых есть только буквы A, Б, В, Г, Д и Е, причём буква Г появляется ровно 1 раз и только на первом или последнем месте. Каждая из других допустимых букв может встречаться в кодовом слове любое количество раз или не встречаться совсем.
Сколько различных кодовых слов может использовать Олег?
✍ Решение:
-
✎ Решение теоретическое:
- Вспомним формулу получения количества возможных вариантов слов:
- где n1 — количество вариантов выбора первой буквы, n2 — количество вариантов выбора второй буквы и т.п.
- Рассмотрим варианты, когда буква Г встречается на первом или последнем месте:
N = n1 * n2 * n3 * … * nL = nL
Г ? ? ? = 1 * 5 * 5 * 5 = 53 = 125 ? ? ? Г = 5 * 5 * 5 * 1 = 53 = 125
125 + 125 = 250
Результат: 250
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
Cartesian(4) — метод расширения последовательности, возвращающий декартову степень множества символов, т.е. в нашем случае перебор 4-знаковых слов из заданных символов * LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
| С++: |
Видеоразбор данного задания (теоретический способ):
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_4:
Шифр кодового замка представляет собой последовательность из пяти символов, каждый из которых является одной из букв X, Y или Z.
Сколько различных вариантов шифра можно задать, если известно, что буква X должна встречаться в коде ровно 2 раза, а каждая из других допустимых букв может встречаться в шифре любое количество раз или не встречаться совсем?
Типовые задания для тренировки
✍ Решение:
-
✎ Решение теоретическое:
- Формула нахождения количества различных сообщений:
- Итак, что у нас дано из этой формулы:
- Начальная мощность алфавита (N) = 3 (буквы X, Y, Z). Но так как буква X встречается ровно два раза, то мы ее рассмотрим отдельно, а остальные 2 буквы — встречаются любое количество раз, значит, будем считать, что:
Q = NL
N = 3 - 1 = 2 (Y и Z)
(L) = 5 - 2 = 3 символа (остальные два символа отведем на размещение X)
X X ? ? ? -> 12 * Q = 23 = 8
✎1 способ. Перебор всех вариантов:
X X ? ? ? - 12 * Q = 23 = 8 X ? X ? ? - 12 * Q = 23 = 8 X ? ? X ? - 12 * Q = 23 = 8 X ? ? ? X - 12 * Q = 23 = 8 ? X X ? ? - 12 * Q = 23 = 8 ? X ? X ? - 12 * Q = 23 = 8 ? X ? ? X - 12 * Q = 23 = 8 ? ? X X ? - 12 * Q = 23 = 8 ? ? X ? X - 12 * Q = 23 = 8 ? ? ? X X - 12 * Q = 23 = 8
✎ 2 способ. При помощи формулы поиска числа сочетаний:
[ C{binom{k}{n}}= frac{n!}{k!(n-k)!} ]
Число сочетаний из n элементов по k элементов:
[ C{binom{2}{5}}= frac{5!}{2!(5-2)!} = frac{120}{12} = 10 ]
* Факториал числа: n! = 1 * 2 * 3 * .. * n
8 * 10 = 80
* задание достаточно решить одним из способов!
Результат: 80
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
Cartesian(5) — метод расширения последовательности, возвращающий декартову степень множества символов, т.е. в нашем случае перебор 5-знаковых слов из заданных символов * LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
| С++: |
Детальный теоретический разбор задания 8 ЕГЭ по информатике теоретическим способом предлагаем посмотреть в видеоуроке:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_5:
Сколько слов длины 5, начинающихся с согласной буквы и заканчивающихся гласной буквой, можно составить из букв ОСЕНЬ? Каждая буква может входить в слово несколько раз. Слова не обязательно должны быть осмысленными словами русского языка.
Типовые задания для тренировки
✍ Решение:
-
✎ Решение теоретическое:
- Из букв слова ОСЕНЬ имеем 2 гласных буквы (О, Е) и 2 согласных буквы (С, Н). Буква мягкий знак «нейтральна».
- Подсчитаем количество букв на каждой из 5 позиций:
2 5 5 5 2 СН все все все ОЕ
N = n1 * n2 * n3 * … * nL = nL
N = 2 * 5 * 5 * 5 * 2 = 500
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
| С++: |
Результат: 500
Разбор можно также посмотреть на видео (теоретическое решение):
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_6:
Вася составляет 4-буквенные слова, в которых есть только буквы Л, Е, Т, О, причём буква Е используется в каждом слове хотя бы 1 раз. Каждая из других допустимых букв может встречаться в слове любое количество раз или не встречаться совсем.
✍ Решение:
-
✎ Решение теоретическое:
- Количество вариантов различных слов вычислим по формуле:
- n1 — количество вариантов выбора первой буквы и т.п.
- Рассмотрим все варианты расположения буквы Е:
✎ 1 способ:
N = n1 * n2 * n3 * …
где
1. Е ? ? ? или 2. ? Е ? ? или 3. ? ? Е ? или 4. ? ? ? Е Где вопросительный знак означает любую букву из Л, Е, Т, О.
Е ? ? ? = 1 * 4 * 4 * 4 = 64 т.е. на первой позиции - только 1 буква - Е, на каждой последующей - одна из четырех букв Л, Е, Т, О.
? Е ? ? = 3 * 1 * 4 * 4 = 48
? ? Е ? = 3 * 3 * 1 * 4 = 36
? ? ? Е = 3 * 3 * 3 * 1 = 27
64 + 48 + 36 + 27 = 175
Результат: 175
✎ 2 способ:
- Так как по условию буква Е встретится хотя бы 1 раз, значит, можно утверждать, что не может быть такого, чтобы буква Е не встретилась бы ни одного раза.
- Таким образом, рассчитаем случай, когда буква Е встречается все 4 раза (т.е. все случаи) и отнимем от результата невозможный случай: когда буква Е не встретится ни одного раза:
1. Буква Е используется 4 раза (т.е. на всех позициях): 4 * 4 * 4 * 4 = 256 2. Буква Е не используется совсем (т.е. только 3 буквы): 3 * 3 * 3 * 3 = 81
256 - 81 = 175
Результат: 175
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
Cartesian(4) — метод расширения последовательности, возвращающий декартову степень множества символов, т.е. в нашем случае перебор 4-знаковых слов из заданных символов * LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
| С++: |
Теоретическое решение задания 8 смотрите в видеоуроке:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_7:
Вася составляет 4-буквенные слова, в которых есть только буквы К, А, Т, Е, Р, причём буква Р используется в каждом слове хотя бы 2 раза. Каждая из других допустимых букв может встречаться в слове любое количество раз или не встречаться совсем.
✍ Решение:
-
✎ Решение теоретическое:
- Количество возможных вариантов слов вычислим по формуле:
- где n1 — количество вариантов выбора первой буквы, n2 — количество вариантов выбора второй буквы и т.п.
- Сначала по формуле получим все варианты для всех пяти букв, включая букву Р:
N = n1 * n2 * n3 * … * nL = nL
5 * 5 * 5 * 5 = 54 = 625
4 * 4 * 4 * 4 = 44 = 256
р ? ? ? = 1 * 4 * 4 * 4 = 43 ? р ? ? = 4 * 1 * 4 * 4 = 43 ? ? р ? = 4 * 4 * 1 * 4 = 43 ? ? ? р = 4 * 4 * 4 * 1 = 43 Получим 43 * 4 = 256
625 - 256 - 256 = 113
✎ Решение с использованием программирования:
PascalABC.net (традиционный):
|
||
PascalABC.net (LINQ):
|
||
Python:
|
||
| С++: |
Результат: 113
Теоретическое решение 8 задания предлагаем посмотреть в видеоуроке:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_8:
Олег составляет таблицу кодовых слов для передачи сообщений, каждому сообщению соответствует своё кодовое слово. В качестве кодовых слов Олег использует 5-буквенные слова, в которых есть только буквы A, Б, В, и Г, причём буква Г появляется не более одного раза и только на последнем месте. Каждая из других допустимых букв может встречаться в кодовом слове любое количество раз или не встречаться совсем.
Сколько различных кодовых слов может использовать Олег?
✍ Решение:
-
✎ Решение теоретическое:
- Вспомним формулу получения количества возможных вариантов слов:
- где n1 — количество вариантов выбора первой буквы,
- n2 — количество вариантов выбора второй буквы и т.п.
- Так как буква Г появляется не более одного раза и только на последнем месте, значит, она может либо появиться 1 раз на последнем месте, либо не появиться совсем.
- Рассмотрим варианты, когда буква Г встречается 1 раз на последнем месте и встречается 0 раз:
N = n1 * n2 * n3 * … * nL = nL
1 раз: ? ? ? ? Г = 3 * 3 * 3 * 3 * 1 = 34 = 81 0 раз: ? ? ? ? ? = 3 * 3 * 3 * 3 * 3 = 35 = 243
81 + 243 = 324
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
Cartesian(5) — метод расширения последовательности, возвращающий декартову степень множества символов, т.е. в нашем случае перебор 5-знаковых слов из заданных символов * LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Результат: 324
8_9:
Вася составляет 4-буквенные слова, в которых есть только буквы К, О, М, А, Р, причём буква А используется в них не более 3-х раз. Каждая из других допустимых букв может встречаться в слове любое количество раз или не встречаться совсем. Словом считается любая допустимая последовательность букв, необязательно осмысленная.
✍ Решение:
-
✎ Решение теоретическое:
- Вспомним формулу получения количества возможных вариантов слов:
- где n1 — количество вариантов выбора первой буквы,
- n2 — количество вариантов выбора второй буквы и т.п.
- Так как буква А по условию используется не более 3-х раз, это значит, что она используется либо 3 раза, либо 2 раза, либо 1 раз, либо не используется совсем. Рассмотрим все эти варианты отдельно.
- 1. Буква А используется 3 раза:
N = n1 * n2 * n3 * … * nL = nL
А А А _ -> 1 * 1 * 1 * 4 = 4 А А _ А -> 1 * 1 * 4 * А = 4 А _ А А -> 1 * 4 * 1 * 1 = 4 _ А А А -> 4 * 1 * 1 * 1 = 4
_ может быть любая из 4 букв: К О М Р. Значит, имеем:4 * 4 = 16 вариантов
А А _ _ -> 1 * 1 * 4 * 4 = 16 А _ А _ -> 1 * 4 * 1 * 4 = 16 А _ _ А -> 1 * 4 * 4 * 1 = 16 _ А А _ -> 4 * 1 * 1 * 4 = 16 _ А _ А -> 4 * 1 * 4 * 1 = 16 _ _ А А -> 4 * 4 * 1 * 1 = 16
_ может быть любая из 4 букв: К О М Р. Значит имеем:16 * 6 = 96 вариантов
А _ _ _ -> 1 * 4 * 4 * 4 = 64 _ А _ _ -> = 64 _ _ А _ -> = 64 _ _ _ А -> = 64
64 * 4 = 256 вариантов
_ _ _ _ -> 44 = 256
16 + 96 + 256 + 256 = 624
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
Cartesian(4) — метод расширения последовательности, возвращающий декартову степень множества символов, т.е. в нашем случае перебор 4-знаковых слов из заданных символов * LINQ (Language Integrated Query) — язык интегрированных запросов |
||
Python:
|
||
| С++: |
Результат: 624
Теоретическое решение смотрите также на видео:
📹 YouTube здесьздесь (теоретическое решение)
8_10:
Сколько существует различных символьных последовательностей длины 3 в четырёхбуквенном алфавите {A,B,C,D}, если известно, что одним из соседей A обязательно является D, а буквы B и C никогда не соседствуют друг с другом?
✍ Решение:
✎ Решение теоретическое:
- Вспомним формулу получения количества возможных вариантов слов:
- где n1 — количество вариантов выбора первой буквы,
- n2 — количество вариантов выбора второй буквы и т.п.
- Будем рассматривать варианты, расставляя каждую букву последовательно по алфавиту, начиная с первой буквы. При этом будем учитывать указанные ограничения для букв А, B и С:
N = n1 * n2 * n3 * … * nL = nL
Начинаем с A: A D 4ABCD = 1 * 1 * 4 = 4 Начинаем с B: B A D, B B 2BD, B D 4ABCD = 7 Начинаем с C: C A D, C C 2CD, C D 4ABCD = 7 Начинаем с D: D A 3BCD, D B 2BD, D C 2CD, D D 4ABCD = 11
4 + 7 + 7 + 11 = 29
Результат: 29
Видеоурок демонстрирует подробное теоретическое решение задания:
📹 YouTube здесьздесь (теоретическое решение)
8_22:
Лена составляет 5-буквенные слова из букв Я, С, Н, О, В, И, Д, Е, Ц, причём слово должно начинаться с согласной и заканчиваться гласной. Первая и последняя буквы слова встречаются в нем только один раз; остальные буквы могут повторяться.
Сколько слов может составить Лена?
✍ Решение:
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
|
||
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
| Python: | ||
| С++: |
Результат: 6860
Использование метода Pairwise()
8_11:
Из букв С, Р, Е, Д, А составляются трехбуквенные комбинации по следующему правилу – в комбинации не может быть подряд идущих гласных и одинаковых букв.
Например, комбинации ААР или ЕСС не являются допустимыми.
Сколько всего комбинаций можно составить, используя это правило?
✍ Решение:
-
✎ Решение теоретическое:
- Рассмотрим два варианта: когда слово начинается с гласной буквы, и когда оно начинается с согласной.
1. С гласной:
1.1 2 3 2 = 2 * 3 * 2 = 12 гл с с 1.2 2 3 2 = 2 * 3 * 2 = 12 гл с гл
2. С согласной:
2.1 3 2 2 = 3 * 2 * 2 = 12 с с с 2.2 3 2 3 = 3 * 2 * 3 = 18 с гл с 2.3 3 2 2 = 3 * 2 * 2 = 12 с с гл
12 + 12 + 12 + 18 + 12 = 66
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
|
||
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
Python:
|
||
| С++: |
Результат: 66
Перестановка букв в слове (каждая буква 1 раз)
8_12:
Дано слово КОРАБЛИКИ. Таня решила составлять новые 5-буквенные слова из букв этого слова по следующим правилам:
1) слово начинается с гласной буквы;
2) гласные и согласные буквы в слове должны чередоваться;
3) буквы в слове не должны повторяться.
✍ Решение:
-
✎ Решение теоретическое:
- Учтем, что в слове КОРАБЛИКИ две буквы К и две И.
- Всего в слове 4 гласных, но поскольку две буквы
И, то необходимо считать только 3 гласных. - Всего в слове 5 согласных, однако две из них — буквы
К, поэтому считать следует 4 согласных. - Посчитаем количество согласных и гласных для каждой из 5 позиций слова, учитывая, что с каждой последующей буквой количество используемых гласных/согласных уменьшается. Под позициями приведем пример букв:
гл с гл с гл 3 4 2 3 1 оаи крбл оа крб и
3 * 4 * 2 * 3 * 1 = 72
Результат: 72
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
|
||
| Python: | ||
| С++: |
Результат: 72
8_21:
Ксюша составляет слова, меняя местами буквы в слове МИМИКРИЯ.
Сколько различных слов, включая исходное, может составить Ксюша?
✍ Решение:
-
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
Смысл решения в использовании типа множества ( |
||
PascalABC.net (использование LINQ, быстрое решение):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Ответ: 3360
Подробное решение программным способом смотрите на видео:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (программное решение)
8_19:
Петя составляет шестибуквенные слова
перестановкой букв
слова АДЖИКА. При этом он избегает слов с двумя подряд одинаковыми буквами. Сколько всего различных слов может составить Петя?
Типовые задания для тренировки
✍ Решение:
-
✎ Решение теоретическое:
- Посчитаем количество слов без двух подряд одинаковых букв. Будем считать относительно буквы А, которых две в заданном слове АДЖИКА. Буквы не могут повторяться, поэтому их кол-во в каждом варианте будет уменьшается:
А*А*** = 4*3*2*1 = 24 слова с данным расположением буквы А. А**А** = 4*3*2*1 = 24 А***А* = 4*3*2*1 А****А = ... *А*А** *А**А* *А***А **А*А* **А**А ***А*А
10 * 24 = 240
✎ Решение с использованием программирования:
PascalABC.net (приближенный к традиционному, долгое решение):
Смысл решения в использовании типа — множества ( |
||
PascalABC.net (использование LINQ, быстрое решение):
|
||
| Python: | ||
| С++: |
Ответ: 240
8_20:
Маша составляет 7-буквенные коды из букв В, Е, Н, Т, И, Л, Ь. Каждую букву нужно использовать
ровно 1 раз
, при этом код буква Ь не может стоять на последнем месте и между гласными. Сколько различных кодов может составить Маша?
Типовые задания для тренировки
✍ Решение:
-
✎ Решение теоретическое:
- Выполним задание следующим образом: 1. посчитаем общее количество слов, не учитывая никакие ограничения. 2. Затем посчитаем случаи, которые необходимо исключить. 3. Вычтем из результата пункта 1 результат пункта 2.
- Общее количество независимо от ограничений (учтем, что буквы не должны повторяться):
7 6 5 4 3 2 1 - количество возможных вариантов букв на семи позициях ИТОГО: 7! = 5040 слов
6 5 4 3 2 1 Ь = 6! = 720
И Ь Е 4 3 2 1 = 24 варианта Так как буквы смещаются по всем позициям, то получим (4 И Ь Е 3 2 1, ...): 24 * 5 = 120 Е Ь И 4 3 2 1 = 24 варианта 24 * 5 = 120
5040 - 720 - 120 - 120 = 4080
✎ Решение с использованием программирования:
Стоит заметить, что теоретическое решение занимает меньше времени, чем программный способ!
PascalABC.net (приближенный к традиционному, долгое решение):
|
||
PascalABC.net (использование LINQ, быстрое решение):
|
||
| Python: | ||
| С++: |
Ответ: 4080
8_23:
Артур составляет 6-буквенные коды перестановкой букв слова ВОРОТА. При этом нельзя ставить рядом две гласные.
Сколько различных кодов может составить Артур?
✍ Решение:
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, спортивное прогр-е):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Ответ: 72
Сколько существует n-значных чисел, записанных в m-ной системе счисления
8_18: Объяснение 8 задания экзамена ЕГЭ 2020 г. (со слов учащегося):
Сколько существует восьмизначных чисел, записанных в восьмеричной системе счисления, в которых все цифры различны и рядом не могут стоять 2 чётные или 2 нечётные цифры?
Типовые задания для тренировки
✍ Решение:
-
✎ Решение теоретическое:
- Выпишем все четные и нечетные цифры, которые могут использоваться в 8-й с.с.:
четные: 0, 2, 4, 6 - итого 4 цифры нечетные: 1, 3, 5, 7 - итого 4 цифры
1) с четной цифры: 3 4 3 3 2 2 1 1 = 3*4*3*3*2*2*1*1 = 432 ч н ч н ч н ч н
Самый старший разряд не может быть равен 0 (поэтому 3 цифры из 4 возможных), так как разряд просто потеряется, и число станет семизначным). Каждый последующий разряд включает на одну цифру меньше, так как по заданию цифры не могут повторяться.
2) с нечетной цифры: 4 4 3 3 2 2 1 1 = 4*4*3*3*2*2*1*1 = 576 н ч н ч н ч н ч
Каждый последующий разряд включает на одну цифру меньше, так как по заданию цифры не могут повторяться.
432 + 576 = 1008
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Ответ: 1008
Список в алфавитном порядке
8_13:
Все 5-буквенные слова, составленные из букв А, О, У, записаны в алфавитном порядке. Ниже приведено начало списка:
1. ААААА
2. ААААО
3. ААААУ
4. АААОА
…
Запишите слово, которое стоит под номером 242 от начала списка.
✍ Решение:
-
✎ Решение теоретическое:
- Данное задание лучше решать следующим образом. Подставим вместо букв цифры (А -> 0, О -> 1, У -> 2):
1. 00000 2. 00001 3. 00002 4. 00010 ...
остатки 241 | 3 | 1 80 | 3 | 2 26 | 3 | 2 8 | 3 | 2 2 | |
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
Смотрим слова и находим по номеру нужное слово: … (241,[У,У,У,У,А]) (242,[У,У,У,У,О]) (243,[У,У,У,У,У])
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Результат: УУУУО
Подробное решение теоретическим способом смотрите на видео:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_14: 8 задание. Демоверсия ЕГЭ 2018 информатика:
Все 4-буквенные слова, составленные из букв Д, Е, К, О, Р, записаны в алфавитном порядке и пронумерованы, начиная с 1.
Ниже приведено начало списка.
1. ДДДД 2. ДДДЕ 3. ДДДК 4. ДДДО 5. ДДДР 6. ДДЕД …
Под каким номером в списке идёт первое слово, которое начинается с буквы K?
✍ Решение:
-
✎ Решение теоретическое:
- Подставим вместо букв цифры (Д -> 0, Е -> 1, К -> 2, О -> 3, Р -> 4):
1. 0000 2. 0001 3. 0002 4. 0003 5. 0004 6. 0010 ...
K -> 2 -> 2000
По формуле разложения числа по степеням основания: 20005 = 2 * 53 + 0 * 22 + 0 + 0 = 2 * 125 = 25010
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Результат: 251
Подробное решение 8 (10) задания демоверсии ЕГЭ 2018 года смотрите на видео:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_15:
Все 4-буквенные слова, составленные из букв П, Р, С, Т, записаны в алфавитном порядке.
Вот начало списка:
1. ПППП 2. ПППР 3. ПППС 4. ПППТ 5. ППРП ... ...
✍ Решение:
Результат: 65
Видеоразбор задания смотрите ниже:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
8_16:
Все четырёхбуквенные слова, составленные из букв В, Е, Г, А, Н записаны в алфавитном порядке и пронумерованы, начиная с 1. Начало списка выглядит так:
1. АААА 2. АААВ 3. АААГ 4. АААЕ 5. АААН 6. ААВА …
Под каким номером в списке идёт первое слово, в котором нет буквы А?
✍ Решение:
- ✎ Решение теоретическое:
- Пронумерованный список начинается со всех букв А. Представим, что А — 0, В — 1, Г — 2, Е — 3, Н — 4. Получим следующий список:
1. 0000 2. 0001 3. 0002 4. 0003 5. 0004 6. 0010
11115 = 1 * 53 + 1 * 52 + 1 * 51 + 1 * 50 = 156
156 + 1 = 157
✎ Решение с использованием программирования:
PascalABC.net (использование LINQ, быстрое решение):
* LINQ (Language Integrated Query) — язык интегрированных запросов |
||
| Python: | ||
| С++: |
Результат: 157
Видеорешение задания (теоретическое):
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
Вероятность событий
8_17:
За четверть Василий Пупкин получил 20 оценок. Сообщение о том, что он вчера получил четверку, несет 2 бита информации.
Сколько четверок получил Василий за четверть?
✍ Решение:
- Для решения данного задания необходимо вспомнить две формулы:
1. Формула Шеннона:
x = log2(1/p)
x - количество информации в сообщении о событии p - вероятность события
2. Формула вероятности случайного события:
p(A) = m/n
m - число случаев, способствующих событию А n - общее число равновозможных случаев
2 = log2(1/p);
=>
1/p = 4;
=>
p = 1/4
p = ?/20
1/4 = ?/20
? = 1/4 * 20 = 5
Результат: 5
Видеоразбор задания:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь (теоретическое решение)
Информация и ее кодирование
Различные подходы к определению понятия «информация». Виды информационных
процессов. Информационный аспект в деятельности человека
Информация (лат. informatio — разъяснение, изложение, набор сведений) — базовое понятие в информатике, которому нельзя дать строгого определения, а можно только пояснить:
- информация — это новые факты, новые знания;
- информация — это сведения об объектах и явлениях окружающей среды, которые повышают уровень осведомленности человека;
- информация — это сведения об объектах и явлениях окружающей среды, которые уменьшают степень неопределенности знаний об этих объектах или явлениях при принятии определенных решений.
Понятие «информация» является общенаучным, т. е. используется в различных науках: физике, биологии, кибернетике, информатике и др. При этом в каждой науке данное понятие связано с различными системами понятий. Так, в физике информация рассматривается как антиэнтропия (мера упорядоченности и сложности системы). В биологии понятие «информация» связывается с целесообразным поведением живых организмов, а также с исследованиями механизмов наследственности. В кибернетике понятие «информация» связано с процессами управления в сложных системах.
Основными социально значимыми свойствами информации являются:
- полезность;
- доступность (понятность);
- актуальность;
- полнота;
- достоверность;
- адекватность.
В человеческом обществе непрерывно протекают информационные процессы: люди воспринимают информацию из окружающего мира с помощью органов чувств, осмысливают ее и принимают определенные решения, которые, воплощаясь в реальные действия, воздействуют на окружающий мир.
Информационный процесс — это процесс сбора (приема), передачи (обмена), хранения, обработки (преобразования) информации.
Сбор информации — это процесс поиска и отбора необходимых сообщений из разных источников (работа со специальной литературой, справочниками; проведение экспериментов; наблюдения; опрос, анкетирование; поиск в информационно-справочных сетях и системах и т. д.).
Передача информации — это процесс перемещения сообщений от источника к приемнику по каналу передачи. Информация передается в форме сигналов — звуковых, световых, ультразвуковых, электрических, текстовых, графических и др. Каналами передачи могут быть воздушное пространство, электрические и оптоволоконные кабели, отдельные люди, нервные клетки человека и т. д.
Хранение информации — это процесс фиксирования сообщений на материальном носителе. Сейчас для хранения информации используются бумага, деревянные, тканевые, металлические и другие поверхности, кино- и фотопленки, магнитные ленты, магнитные и лазерные диски, флэш-карты и др.
Обработка информации — это процесс получения новых сообщений из имеющихся. Обработка информации является одним из основных способов увеличения ее количества. В результате обработки из сообщения одного вида можно получить сообщения других видов.
Защита информации — это процесс создания условий, которые не допускают случайной потери, повреждения, изменения информации или несанкционированного доступа к ней. Способами защиты информации являются создание ее резервных копий, хранение в защищенном помещении, предоставление пользователям соответствующих прав доступа к информации, шифрование сообщений и др.
Язык как способ представления и передачи информации
Для того чтобы сохранить информацию и передать ее, с давних времен использовались знаки.
В зависимости от способа восприятия знаки делятся на:
- зрительные (буквы и цифры, математические знаки, музыкальные ноты, дорожные знаки и др.);
- слуховые (устная речь, звонки, сирены, гудки и др.);
- осязательные (азбука Брайля для слепых, жесты-касания и др.);
- обонятельные;
- вкусовые.
Для долговременного хранения знаки записывают на носители информации.
Для передачи информации используются знаки в виде сигналов (световые сигналы светофора, звуковой сигнал школьного звонка и т. д.).
По способу связи между формой и значением знаки делятся на:
- иконические — их форма похожа на отображаемый объект (например, значок папки «Мой компьютер» на «Рабочем столе» компьютера);
- символы — связь между их формой и значением устанавливается по общепринятому соглашению (например, буквы, математические символы ∫, ≤, ⊆, ∞; символы химических элементов).
Для представления информации используются знаковые системы, которые называются языками. Основу любого языка составляет алфавит — набор символов, из которых формируется сообщение, и набор правил выполнения операций над символами.
Языки делятся на:
- естественные (разговорные) — русский, английский, немецкий и др.;
- формальные — встречающиеся в специальных областях человеческой деятельности (например, язык алгебры, языки программирования, электрических схем и др.)
Системы счисления также можно рассматривать как формальные языки. Так, десятичная система счисления — это язык, алфавит которого состоит из десяти цифр 0..9, двоичная система счисления — язык, алфавит которого состоит из двух цифр — 0 и 1.
Методы измерения количества информации: вероятностный и алфавитный
Единицей измерения количества информации является бит. 1 бит — это количество информации, содержащейся в сообщении, которое вдвое уменьшает неопределенность знаний о чем-либо.
Связь между количеством возможных событий N и количеством информации I определяется формулой Хартли:
N = 2I.
Например, пусть шарик находится в одной из четырех коробок. Таким образом, имеется четыре равновероятных события (N = 4). Тогда по формуле Хартли 4 = 2I. Отсюда I = 2. То есть сообщение о том, в какой именно коробке находится шарик, содержит 2 бита информации.
Алфавитный подход
При алфавитном подходе к определению количества информации отвлекаются от содержания (смысла) информации и рассматривают ее как последовательность знаков определенной знаковой системы. Набор символов языка (алфавит) можно рассматривать как различные возможные события. Тогда, если считать, что появление символов в сообщении равновероятно, по формуле Хартли можно рассчитать, какое количество информации несет каждый символ:
I = log2 N.
Например, в русском языке 32 буквы (буква ё обычно не используется), т. е. количество событий будет равно 32. Тогда информационный объем одного символа будет равен:
I = log2 32 = 5 битов.
Если N не является целой степенью 2, то число log2N не является целым числом, и для I надо выполнять округление в большую сторону. При решении задач в таком случае I можно найти как log2N’, где N′ — ближайшая к N степень двойки — такая, что N′ > N.
Например, в английском языке 26 букв. Информационный объем одного символа можно найти так:
N = 26; N’ = 32; I = log2N’ = log2(25) = 5 битов.
Если количество символов алфавита равно N, а количество символов в записи сообщения равно М, то информационный объем данного сообщения вычисляется по формуле:
I = M · log2N.
Примеры решения задач
Пример 1. Световое табло состоит из лампочек, каждая из которых может находиться в одном из двух состояний («включено» или «выключено»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 50 различных сигналов?
Решение. С помощью n лампочек, каждая из которых может находиться в одном из двух состояний, можно закодировать 2n сигналов. 25 < 50 < 26, поэтому пяти лампочек недостаточно, а шести хватит.
Ответ: 6.
Пример 2. Метеорологическая станция ведет наблюдения за влажностью воздуха. Результатом одного измерения является целое число от 0 до 100, которое записывается при помощи минимально возможного количества битов. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
Решение. В данном случае алфавитом является множество целых чисел от 0 до 100. Всего таких значений 101. Поэтому информационный объем результатов одного измерения I = log2101. Это значение не будет целочисленным. Заменим число 101 ближайшей к нему степенью двойки, большей 101. Это число 128 = 27. Принимаем для одного измерения I = log2128 = 7 битов. Для 80 измерений общий информационный объем равен:
80 · 7 = 560 битов = 70 байтов.
Ответ: 70 байтов.
Вероятностный подход
Вероятностный подход к измерению количества информации применяют, когда возможные события имеют различные вероятности реализации. В этом случае количество информации определяют по формуле Шеннона:
$I=-∑↙{i=1}↖{N}p_ilog_2p_i$,
где $I$ — количество информации;
$N$ — количество возможных событий;
$p_i$ — вероятность $i$-го события.
Например, пусть при бросании несимметричной четырехгранной пирамидки вероятности отдельных событий будут равны:
$p_1={1}/{2}, p_2={1}/{4}, p_3={1}/{8}, p_4={1}/{8}$.
Тогда количество информации, которое будет получено после реализации одного из них, можно вычислить по формуле Шеннона:
$I=-({1}/{2}·log_2{1}/{2}+{1}/{4}·log_2{1}/{4}+{1}/{8}·log_2{1}/{8}+{1}/{8}·log_2{1}/{8})={14}/{8}$ битов $= 1.75 $бита.
Единицы измерения количества информации
Наименьшей единицей информации является бит (англ. binary digit (bit) — двоичная единица информации).
Бит — это количество информации, необходимое для однозначного определения одного из двух равновероятных событий. Например, один бит информации получает человек, когда он узнает, опаздывает с прибытием нужный ему поезд или нет, был ночью мороз или нет, присутствует на лекции студент Иванов или нет и т. д.
В информатике принято рассматривать последовательности длиной 8 битов. Такая последовательность называется байтом.
Производные единицы измерения количества информации:
1 байт = 8 битов
1 килобайт (Кб) = 1024 байта = 210 байтов
1 мегабайт (Мб) = 1024 килобайта = 220 байтов
1 гигабайт (Гб) = 1024 мегабайта = 230 байтов
1 терабайт (Тб) = 1024 гигабайта = 240 байтов
Процесс передачи информации. Виды и свойства источников и приемников информации. Сигнал, кодирование и декодирование, причины искажения информации при передаче
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними.
В качестве источника информации может выступать живое существо или техническое устройство. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал.
Сигнал — это материально-энергетическая форма представления информации. Другими словами, сигнал — это переносчик информации, один или несколько параметров которого, изменяясь, отображают сообщение. Сигналы могут быть аналоговыми (непрерывными) или дискретными (импульсными).
Сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением.
Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Примеры решения задач
Пример 1. Для кодирования букв А, З, Р, О используются двухразрядные двоичные числа 00, 01, 10, 11 соответственно. Этим способом закодировали слово РОЗА и результат записали шестнадцатеричным кодом. Указать полученное число.
Решение. Запишем последовательность кодов для каждого символа слова РОЗА: 10 11 01 00. Если рассматривать полученную последовательность как двоичное число, то в шестнадцатеричном коде оно будет равно: 1011 01002 = В416.
Ответ: В416.
Скорость передачи информации и пропускная способность канала связи
Прием/передача информации может происходить с разной скоростью. Количество информации, передаваемое за единицу времени, есть скорость передачи информации, или скорость информационного потока.
Скорость выражается в битах в секунду (бит/с) и кратных им Кбит/с и Мбит/с, а также в байтах в секунду (байт/с) и кратных им Кбайт/с и Мбайт/с.
Максимальная скорость передачи информации по каналу связи называется пропускной способностью канала.
Примеры решения задач
Пример 1. Скорость передачи данных через ADSL-соединение равна 256000 бит/с. Передача файла через данное соединение заняла 3 мин. Определите размер файла в килобайтах.
Решение. Размер файла можно вычислить, если умножить скорость передачи информации на время передачи. Выразим время в секундах: 3 мин = 3 ⋅ 60 = 180 с. Выразим скорость в килобайтах в секунду: 256000 бит/с = 256000 : 8 : 1024 Кбайт/с. При вычислении размера файла для упрощения расчетов выделим степени двойки:
Размер файла = (256000 : 8 : 1024) ⋅ (3 ⋅ 60) = (28 ⋅ 103 : 23 : 210) ⋅ (3 ⋅ 15 ⋅ 22) = (28 ⋅ 125 ⋅ 23 : 23 : 210) ⋅ (3 ⋅ 15 ⋅ 22) = 125 ⋅ 45 = 5625 Кбайт.
Ответ: 5625 Кбайт.
Представление числовой информации. Сложение и умножение в разных системах счисления
Представление числовой информации с помощью систем счисления
Для представления информации в компьютере используется двоичный код, алфавит которого состоит из двух цифр — 0 и 1. Каждая цифра машинного двоичного кода несет количество информации, равное одному биту.
Система счисления — это система записи чисел с помощью определенного набора цифр.
Система счисления называется позиционной, если одна и та же цифра имеет различное значение, которое определяется ее местом в числе.
Позиционной является десятичная система счисления. Например, в числе 999 цифра «9» в зависимости от позиции означает 9, 90, 900.
Римская система счисления является непозиционной. Например, значение цифры Х в числе ХХІ остается неизменным при вариации ее положения в числе.
Позиция цифры в числе называется разрядом. Разряд числа возрастает справа налево, от младших разрядов к старшим.
Количество различных цифр, употребляемых в позиционной системе счисления, называется ее основанием.
Развернутая форма числа — это запись, которая представляет собой сумму произведений цифр числа на значение позиций.
Например: 8527 = 8 ⋅ 103 + 5 ⋅ 102 + 2 ⋅ 101 + 7 ⋅ 100.
Развернутая форма записи чисел произвольной системы счисления имеет вид
$∑↙{i=n-1}↖{-m}a_iq^i$,
где $X$ — число;
$a$ — цифры численной записи, соответствующие разрядам;
$i$ — индекс;
$m$ — количество разрядов числа дробной части;
$n$ — количество разрядов числа целой части;
$q$ — основание системы счисления.
Например, запишем развернутую форму десятичного числа $327.46$:
$n=3, m=2, q=10.$
$X=∑↙{i=2}↖{-2}a_iq^i=a_2·10^2+a_1·10^1+a_0·10^0+a_{-1}·10^{-1}+a_{-2}·10^{-2}=3·10^2+2·10^1+7·10^0+4·10^{-1}+6·10^{-2}$
Если основание используемой системы счисления больше десяти, то для цифр вводят условное обозначение со скобкой вверху или буквенное обозначение: В — двоичная система, О — восмеричная, Н — шестнадцатиричная.
Например, если в двенадцатеричной системе счисления 10 = А, а 11 = В, то число 7А,5В12 можно расписать так:
7А,5В12 = В ⋅ 12-2 + 5 ⋅ 2-1 + А ⋅ 120 + 7 ⋅ 121.
В шестнадцатеричной системе счисления 16 цифр, обозначаемых 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F, что соответствует следующим числам десятеричной системы счисления: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15. Примеры чисел: 17D,ECH; F12AH.
Перевод чисел в позиционных системах счисления
Перевод чисел из произвольной системы счисления в десятичную
Для перевода числа из любой позиционной системы счисления в десятичную необходимо использовать развернутую форму числа, заменяя, если это необходимо, буквенные обозначения соответствующими цифрами. Например:
11012 = 1 ⋅ 23 + 1 ⋅ 22 + 0 ⋅ 21 + 1 ⋅ 20 = 1310;
17D,ECH = 12 ⋅ 16–2 + 14 ⋅ 16–1 + 13 ⋅ 160 + 7 ⋅ 161 + 1 ⋅ 162 = 381,921875.
Перевод чисел из десятичной системы счисления в заданную
Для преобразования целого числа десятичной системы счисления в число любой другой системы счисления последовательно выполняют деление нацело на основание системы счисления, пока не получат нуль. Числа, которые возникают как остаток от деления на основание системы, представляют собой последовательную запись разрядов числа в выбранной системе счисления от младшего разряда к старшему. Поэтому для записи самого числа остатки от деления записывают в обратном порядке.
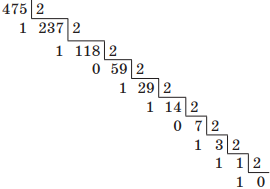
Например, переведем десятичное число 475 в двоичную систему счисления. Для этого будем последовательно выполнять деление нацело на основание новой системы счисления, т. е. на 2:
Читая остатки от деления снизу вверх, получим 111011011.
Проверка:
1 ⋅ 28 + 1 ⋅ 27 + 1 ⋅ 26 + 0 ⋅ 25 + 1 ⋅ 24 + 1 ⋅ 23 + 0 ⋅ 22 + 1 ⋅ 21 + 1 ⋅ 20 = 1 + 2 + 8 + 16 + 64 + 128 + 256 = 47510.
Для преобразования десятичных дробей в число любой системы счисления последовательно выполняют умножение на основание системы счисления, пока дробная часть произведения не будет равна нулю. Полученные целые части являются разрядами числа в новой системе, и их необходимо представлять цифрами этой новой системы счисления. Целые части в дальнейшем отбрасываются.
Например, переведем десятичную дробь 0,37510 в двоичную систему счисления:

Полученный результат — 0,0112.
Не каждое число может быть точно выражено в новой системе счисления, поэтому иногда вычисляют только требуемое количество разрядов дробной части.
Перевод чисел из двоичной системы счисления в восьмеричную и шестнадцатеричную и обратно
Для записи восьмеричных чисел используются восемь цифр, т. е. в каждом разряде числа возможны 8 вариантов записи. Каждый разряд восьмеричного числа содержит 3 бита информации (8 = 2І; І = 3).
Таким образом, чтобы из восьмеричной системы счисления перевести число в двоичный код, необходимо каждую цифру этого числа представить триадой двоичных символов. Лишние нули в старших разрядах отбрасываются.
Например:
1234,7778 = 001 010 011 100,111 111 1112 = 1 010 011 100,111 111 1112;
12345678 = 001 010 011 100 101 110 1112 = 1 010 011 100 101 110 1112.
При переводе двоичного числа в восьмеричную систему счисления нужно каждую триаду двоичных цифр заменить восьмеричной цифрой. При этом, если необходимо, число выравнивается путем дописывания нулей перед целой частью или после дробной.
Например:
11001112 = 001 100 1112 = 1478;
11,10012 = 011,100 1002 = 3,448;
110,01112 = 110,011 1002 = 6,348.
Для записи шестнадцатеричных чисел используются шестнадцать цифр, т. е. для каждого разряда числа возможны 16 вариантов записи. Каждый разряд шестнадцатеричного числа содержит 4 бита информации (16 = 2І; І = 4).
Таким образом, для перевода двоичного числа в шестнадцатеричное его нужно разбить на группы по четыре цифры и преобразовать каждую группу в шестнадцатеричную цифру.
Например:
11001112 = 0110 01112 = 6716;
11,10012 = 0011,10012 = 3,916;
110,01110012 = 0110,0111 00102 = 65,7216.
Для перевода шестнадцатеричного числа в двоичный код необходимо каждую цифру этого числа представить четверкой двоичных цифр.
Например:
1234,AB7716 = 0001 0010 0011 0100,1010 1011 0111 01112 = 1 0010 0011 0100,1010 1011 0111 01112;
CE456716 = 1100 1110 0100 0101 0110 01112.
При переводе числа из одной произвольной системы счисления в другую нужно выполнить промежуточное преобразование в десятичное число. При переходе из восьмеричного счисления в шестнадцатеричное и обратно используется вспомогательный двоичный код числа.
Например, переведем троичное число 2113 в семеричную систему счисления. Для этого сначала преобразуем число 2113 в десятичное, записав его развернутую форму:
2113 = 2 ⋅ 32 + 1 ⋅ 31 + 1 ⋅ 30 = 18 + 3 + 1 = 2210.
Затем переведем десятичное число 2210 в семеричную систему счисления делением нацело на основание новой системы счисления, т. е. на 7:
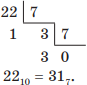
Итак, 2113 = 317.
Примеры решения задач
Пример 1. В системе счисления с некоторым основанием число 12 записывается в виде 110. Указать это основание.
Решение. Обозначим искомое основание п. По правилу записи чисел в позиционных системах счисления 1210 = 110n = 0 ·n0 + 1 · n1 + 1 · n2. Составим уравнение: n2 + n = 12 . Найдем натуральный корень уравнения (отрицательный корень не подходит, т. к. основание системы счисления, по определению, натуральное число большее единицы): n = 3 . Проверим полученный ответ: 1103 = 0· 30 + 1 · 31 + 1 · 32 = 0 + 3 + 9 = 12 .
Ответ: 3.
Пример 2. Указать через запятую в порядке возрастания все основания систем счисления, в которых запись числа 22 оканчивается на 4.
Решение. Последняя цифра в записи числа представляет собой остаток от деления числа на основание системы счисления. 22 — 4 = 18. Найдем делители числа 18. Это числа 2, 3, 6, 9, 18. Числа 2 и 3 не подходят, т. к. в системах счисления с основаниями 2 и 3 нет цифры 4. Значит, искомыми основаниями являются числа 6, 9 и 18. Проверим полученный результат, записав число 22 в указанных системах счисления: 2210 = 346 = 249 = 1418.
Ответ: 6, 9, 18.
Пример 3. Указать через запятую в порядке возрастания все числа, не превосходящие 25, запись которых в двоичной системе счисления оканчивается на 101. Ответ записать в десятичной системе счисления.
Решение. Для удобства воспользуемся восьмеричной системой счисления. 1012 = 58. Тогда число х можно представить как x = 5 · 80 + a1 · 81 + a2 · 82 + a3 · 83 + … , где a1, a2, a3, … — цифры восьмеричной системы. Искомые числа не должны превосходить 25, поэтому разложение нужно ограничить двумя первыми слагаемыми ( 82 > 25), т. е. такие числа должны иметь представление x = 5 + a1 · 8. Поскольку x ≤ 25 , допустимыми значениями a1 будут 0, 1, 2. Подставив эти значения в выражение для х, получим искомые числа:
a1 = 0; x = 5 + 0 · 8 = 5;.
a1=1; x = 5 + 1 · 8 = 13;.
a1 = 2; x = 5 + 2 · 8 = 21;.
Выполним проверку:
510 = 1012;
1310 = 11012;
2110 = 101012.
Ответ: 5, 13, 21.
Арифметические операции в позиционных системах счисления
Правила выполнения арифметических действий над двоичными числами задаются таблицами сложения, вычитания и умножения.
| Сложение | Вычитание | Умножение |
| 0 + 0 = 0 | 0 – 0 = 0 | 0 ⋅ 0 = 0 |
| 0 + 1 = 1 | 1 – 0 = 1 | 0 ⋅ 1 = 0 |
| 1 + 0 = 1 | 1 – 1 = 0 | 1 ⋅ 0 = 0 |
| 1 + 1 = 10 | 10 – 1 = 1 | 1 ⋅ 1 = 1 |
Правило выполнения операции сложения одинаково для всех систем счисления: если сумма складываемых цифр больше или равна основанию системы счисления, то единица переносится в следующий слева разряд. При вычитании, если необходимо, делают заем.
Пример выполнения сложения: сложим двоичные числа 111 и 101, 10101 и 1111:

Пример выполнения вычитания: вычтем двоичные числа 10001 – 101 и 11011 – 1101:

Пример выполнения умножения: умножим двоичные числа 110 и 11, 111 и 101:
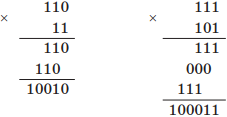
Аналогично выполняются арифметические действия в восьмеричной, шестнадцатеричной и других системах счисления. При этом необходимо учитывать, что величина переноса в следующий разряд при сложении и заем из старшего разряда при вычитании определяется величиной основания системы счисления.
Например, выполним сложение восьмеричных чисел 368 и 158, а также вычитание шестнадцатеричных чисел 9С16 и 6716:

При выполнении арифметических операций над числами, представленными в разных системах счисления, нужно предварительно перевести их в одну и ту же систему.
Представление чисел в компьютере
Формат с фиксированной запятой
В памяти компьютера целые числа хранятся в формате с фиксированной запятой: каждому разряду ячейки памяти соответствует один и тот же разряд числа, «запятая» находится вне разрядной сетки.
Для хранения целых неотрицательных чисел отводится 8 битов памяти. Минимальное число соответствует восьми нулям, хранящимся в восьми битах ячейки памяти, и равно 0. Максимальное число соответствует восьми единицам и равно
1 ⋅ 27 + 1 ⋅ 26 + 1 ⋅ 25 + 1 ⋅ 24 + 1 ⋅ 23 + 1 ⋅ 22 + 1 ⋅ 21 + 1 ⋅ 20 = 25510.
Таким образом, диапазон изменения целых неотрицательных чисел — от 0 до 255.
Для п-разрядного представления диапазон будет составлять от 0 до 2n – 1.
Для хранения целых чисел со знаком отводится 2 байта памяти (16 битов). Старший разряд отводится под знак числа: если число положительное, то в знаковый разряд записывается 0, если число отрицательное — 1. Такое представление чисел в компьютере называется прямым кодом.
Для представления отрицательных чисел используется дополнительный код. Он позволяет заменить арифметическую операцию вычитания операцией сложения, что существенно упрощает работу процессора и увеличивает его быстродействие. Дополнительный код отрицательного числа А, хранящегося в п ячейках, равен 2n − |А|.
Алгоритм получения дополнительного кода отрицательного числа:
1. Записать прямой код числа в п двоичных разрядах.
2. Получить обратный код числа. (Обратный код образуется из прямого кода заменой нулей единицами, а единиц — нулями, кроме цифр знакового разряда. Для положительных чисел обратный код совпадает с прямым. Используется как промежуточное звено для получения дополнительного кода.)
3. Прибавить единицу к полученному обратному коду.
Например, получим дополнительный код числа –201410 для шестнадцатиразрядного представления:
| Прямой код | Двоичный код числа 201410 со знаковым разрядом | 1000011111011110 |
| Обратный код | Инвертирование (исключая знаковый разряд) | 1111100000100001 |
| Прибавление единицы | 1111100000100001 + 0000000000000001 | |
| Дополнительный код | 1111100000100010 |
При алгебраическом сложении двоичных чисел с использованием дополнительного кода положительные слагаемые представляют в прямом коде, а отрицательные — в дополнительном коде. Затем суммируют эти коды, включая знаковые разряды, которые при этом рассматриваются как старшие разряды. При переносе из знакового разряда единицу переноса отбрасывают. В результате получают алгебраическую сумму в прямом коде, если эта сумма положительная, и в дополнительном — если сумма отрицательная.
Например:
1) Найдем разность 1310 – 1210 для восьмибитного представления. Представим заданные числа в двоичной системе счисления:
1310 = 11012 и 1210 = 11002.
Запишем прямой, обратный и дополнительный коды для числа –1210 и прямой код для числа 1310 в восьми битах:
| 1310 | –1210 | |
| Прямой код | 00001101 | 10001100 |
| Обратный код | — | 11110011 |
| Дополнительный код | — | 11110100 |
Вычитание заменим сложением (для удобства контроля за знаковым разрядом условно отделим его знаком «_»):

Так как произошел перенос из знакового разряда, первую единицу отбрасываем, и в результате получаем 00000001.
2) Найдем разность 810 – 1310 для восьмибитного представления.
Запишем прямой, обратный и дополнительный коды для числа –1310 и прямой код для числа 810 в восьми битах:
| 810 | –1310 | |
| Прямой код | 00001000 | 10001101 |
| Обратный код | — | 11110010 |
| Дополнительный код | — | 11110011 |
Вычитание заменим сложением:

В знаковом разряде стоит единица, а значит, результат получен в дополнительном коде. Перейдем от дополнительного кода к обратному, вычтя единицу:
11111011 – 00000001 = 11111010.
Перейдем от обратного кода к прямому, инвертируя все цифры, за исключением знакового (старшего) разряда: 10000101. Это десятичное число –510.
Так как при п-разрядном представлении отрицательного числа А в дополнительном коде старший разряд выделяется для хранения знака числа, минимальное отрицательное число равно: А = –2n–1, а максимальное: |А| = 2n–1 или А = –2n–1 – 1.
Определим диапазон чисел, которые могут храниться в оперативной памяти в формате длинных целых чисел со знаком (для хранения таких чисел отводится 32 бита памяти). Минимальное отрицательное число равно
А = –231 = –214748364810.
Максимальное положительное число равно
А = 231 – 1 = 214748364710.
Достоинствами формата с фиксированной запятой являются простота и наглядность представления чисел, простота алгоритмов реализации арифметических операций. Недостатком является небольшой диапазон представимых чисел, недостаточный для решения большинства прикладных задач.
Формат с плавающей запятой
Вещественные числа хранятся и обрабатываются в компьютере в формате с плавающей запятой, использующем экспоненциальную форму записи чисел.
Число в экспоненциальном формате представляется в таком виде:
$A=m·q^n$,
где $m$ — мантисса числа (правильная отличная от нуля дробь);
$q$ — основание системы счисления;
$n$ — порядок числа.
Например, десятичное число 2674,381 в экспоненциальной форме запишется так:
2674,381 = 0,2674381 ⋅ 104.
Число в формате с плавающей запятой может занимать в памяти 4 байта (обычная точность) или 8 байтов (двойная точность). При записи числа выделяются разряды для хранения знака мантиссы, знака порядка, порядка и мантиссы. Две последние величины определяют диапазон изменения чисел и их точность.
Определим диапазон (порядок) и точность (мантиссу) для формата чисел обычной точности, т. е. четырехбайтных. Из 32 битов 8 выделяется для хранения порядка и его знака и 24 — для хранения мантиссы и ее знака.
Найдем максимальное значение порядка числа. Из 8 разрядов старший разряд используется для хранения знака порядка, остальные 7 — для записи величины порядка. Значит, максимальное значение равно 11111112 = 12710. Так как числа представляются в двоичной системе счисления, то
$q^n = 2^{127}≈ 1.7 · 10^{38}$.
Аналогично, максимальное значение мантиссы равно
$m = 2^{23} — 1 ≈ 2^{23} = 2^{(10 · 2.3)} ≈ 1000^{2.3} = 10^{(3 · 2.3)} ≈ 10^7$.
Таким образом, диапазон чисел обычной точности составляет $±1.7 · 10^{38}$.
Кодирование текстовой информации. Кодировка ASCII. Основные используемые кодировки кириллицы
Соответствие между набором символов и набором числовых значений называется кодировкой символа. При вводе в компьютер текстовой информации происходит ее двоичное кодирование. Код символа хранится в оперативной памяти компьютера. В процессе вывода символа на экран производится обратная операция — декодирование, т. е. преобразование кода символа в его изображение.
Присвоенный каждому символу конкретный числовой код фиксируется в кодовых таблицах. Одному и тому же символу в разных кодовых таблицах могут соответствовать разные числовые коды. Необходимые перекодировки текста обычно выполняют специальные программы-конверторы, встроенные в большинство приложений.
Как правило, для хранения кода символа используется один байт (восемь битов), поэтому коды символов могут принимать значение от 0 до 255. Такие кодировки называют однобайтными. Они позволяют использовать 256 символов ( N = 2I = 28 = 256 ). Таблица однобайтных кодов символов называется ASCII (American Standard Code for Information Interchange — Американский стандартный код для обмена информацией). Первая часть таблицы ASCII-кодов (от 0 до 127) одинакова для всех IBM-PC совместимых компьютеров и содержит:
- коды управляющих символов;
- коды цифр, арифметических операций, знаков препинания;
- некоторые специальные символы;
- коды больших и маленьких латинских букв.
Вторая часть таблицы (коды от 128 до 255) бывает различной в различных компьютерах. Она содержит коды букв национального алфавита, коды некоторых математических символов, коды символов псевдографики. Для русских букв в настоящее время используется пять различных кодовых таблиц: КОИ-8, СР1251, СР866, Мас, ISO.
В последнее время широкое распространение получил новый международный стандарт Unicode. В нем отводится по два байта (16 битов) для кодирования каждого символа, поэтому с его помощью можно закодировать 65536 различных символов ( N = 216 = 65536 ). Коды символов могут принимать значение от 0 до 65535.
Примеры решения задач
Пример. С помощью кодировки Unicode закодирована следующая фраза:
Я хочу поступить в университет!
Оценить информационный объем этой фразы.
Решение. В данной фразе содержится 31 символ (включая пробелы и знак препинания). Поскольку в кодировке Unicode каждому символу отводится 2 байта памяти, для всей фразы понадобится 31 ⋅ 2 = 62 байта или 31 ⋅ 2 ⋅ 8 = 496 битов.
Ответ: 32 байта или 496 битов.
Измерение информации, алфавитный подход
Методика преподавания темы в 10-11 классах и подготовки к ЕГЭ
В данной методике рассматривается алфавитный подход к измерению информации.
При изучении данной темы обращаем особое внимание на таблицы степеней двойки и соответствия единиц измерения количества информации, а так же их взаимосвязь, что послужит изложенному выше принципу решения задач.
При этом знание таблиц является необходимым условием для максимально быстрого и точного решения, без потери времени и математических ошибок.
Ниже приведена таблица степеней двойки, где k – это степень, а 2k — результат возведения числа 2 в степень k. При алфавитном подходе эта таблица показывает, сколько вариантов всевозможных «слов» Q= 2k можно закодировать с помощью k бит на символ.
|
n |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
2n |
1 |
2 |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
2048 |
4096 |
Бит — наименьшая единица измерения количества информации, может принимать только два значения – 0 или 1.
Байт содержит 8 бит (23 бит). При этом байт является неделимой единицей и всегда отображается целым числом.
Во второй таблице даны укрупненные единицы информации и их соответствие.
В России правила образования укрупненных единиц в информатике подтверждены постановлением № 879 Правительства РФ от 31 октября 2009г. Это постановление гласит:
«Наименование и обозначение единицы количества информации «байт» применяются с двоичными приставками «Кило», «Мега», «Гига», которые соответствуют множителям 210, 220 и 230 (1 Килобайт = 1024 байт, 1 Мегабайт = 1024 Килобайт,
1 Гигабайт = 1024 Мегабайт). Эти приставки пишутся с большой буквы».
Таким образом, каждая следующая единица измерения количества информации в 1024 = 210 раза больше предыдущей, на основании чего и строится таблица их соответствия:
|
Наименование ед.изм. |
В бит= |
В бит / байт |
Примечание |
|
1 Кбит (один Килобит) |
210 бит |
1 024 бит |
более 1 тыс.бит |
|
бит (один Мегабит) |
220 бит |
1 048 576 бит |
более 1 млн.бит |
|
1 Гбит (один Гигабит) |
230 бит |
более 109 бит |
более 1 млрд.бит |
|
1 Кбайт (один Килобайт) |
213 бит |
210 байт = 1024 байт |
более 1 тыс.байт |
|
1 Мбайт (один Мегабайт) |
223 бит |
220 байт = 1 048 576 байт |
более 1 млн.байт |
|
1 Гбайт (один Гигабайт) |
233 бит |
230 байт = 109 байт |
более 1 млрд.байт |
Таблицы не нужно учить наизусть! Рекомендуется пользоваться ими при решении задач, но при этом заглядывать в них все реже и реже, пытаясь сначала вспомнить значения, приведенные в них. Тогда эти таблицы сами «улягутся» в Вашей голове, и очень поможет Вам на экзамене в этой и в других темах!
Отцом-основателем теории информации, нашедшей применение в современных высокотехнологических системах связи, является американский инженер, криптоаналитик и математик Клод Шеннон. Именно он в 1948 году предложил использовать слово «бит» для обозначения наименьшей единицы измерения информации (в статье «Математическая теория связи»). Кроме того, понятие энтропии было важной особенностью теории Шеннона. Он продемонстрировал, что введённая им энтропия эквивалентна мере неопределённости информации в передаваемом сообщении, что и лежит в основе содержательного подхода к измерению информации, который в данной разработке нами не рассматривается. Статьи Шеннона «Математическая теория связи» и «Теория связи в секретных системах» считаются основополагающими для теории информации и криптографии.
В начале 60-х гг. русский советский математик, один из крупнейших математиков XX века Андрей Николаевич Колмогоров начал искать пути построения теории информации и теории вероятностей на принципиально новой, алгоритмической основе. В свое первой статье по алгоритмической теории информации «Три подхода к определению понятия «количество информации», вышедшей в первом выпуске первого тома журнала «Проблемы передачи информации», в 1965г, А.Н.Колмогоров указал способ измерения сложности конечного объекта (слова), для чего он ввел понятие, называемое сейчас «колмогоровской сложностью». Свое новое понятие он применил для построения алгоритмического варианта теории информации, позволяющего измерять информацию в конечной строке знаков.
Согласно Колмогорову, количество информации, содержащейся в тексте, определяется минимально возможной длиной двоичного кода, необходимого для представления этого текста.
Общей формулой, применяемой в двух различных подходах к измерению информации является формула Хартли — логарифмическая мера информации, которая определяет количество информации, содержащееся в сообщении (объем сообщения):
I = N *log2М
Здесь М — количество символов в используемом алфавите (мощность алфавита), N — длина сообщения (количество символов в сообщении), I — количество информации в сообщении в битах.
Формула была предложена Ральфом Хартли в 1928 году как один из научных подходов к оценке сообщений.
Для случая определения количества информации k в одном символе (бит на символ) алфавита мощности М, формула Хартли принимает вид:
k = log2М
Соответственно, мощность алфавита равна:
M= 2k
Из формулы Хартли следует, что алфавит, содержащий только 1 символ, не может быть использован для передачи информации, так как
log21 = 0.
Пусть, имеется алфавит, из M букв которого составляется сообщение.
Количество возможных вариантов Q всех возможных «слов» (символьных цепочек без учета смысла) длиной N равно
Q = Мk
где М — количество букв в алфавите, k — информационный вес символа (количество бит, необходимое для его кодирования, бит на символ).
Для простоты понимания и решения задач, за М мы будем принимать значения терминов, наиболее часто применяемых в условиях задач – виды, типы, состояния символов. Это упростит понимание и решение задач в алфавитном подходе.
Отметим, что формулы вычисления объема информации I = N * k и подсчета количества вариантов Q=Mk взаимодействуют друг с другом через величину k (бит на символ).
Алфавитный подход к измерению информации
Основные понятия и термины:
Алфавит – это набор символов, используемых в языке, на котором передается сообщение. При этом символом алфавита могут быть буквы, цифры и прочие символы, входящие в сообщение.
Мощность алфавита — это количество символов в алфавите.
Например, мощность русского алфавита равна 32 при Е =Ё и 33 – в противном случае. Мощность английского алфавита равно 26.0
Для упрощения понимания и легкости запоминания различий в рассматриваемых далее задачах, разобьем их на 5 типов и будем рассматривать решения соответственно этим типам.
Для быстрого и точного вычисления количества информации следует применять таблицу степеней двойки, которая показывает, сколько вариантов всевозможных «слов» Q можно закодировать с помощью k бит на символ.
Так же при решении задач следует обязательно привести единицы измерения количества информации к одному виду. При этом помним, что значение k – это бит на символ, другого измерения здесь быть не может!
Задача 1 типа.
В велокроссе участвуют 119 спортсменов. Специальное устройство регистрирует прохождение каждым из участников промежуточного финиша, записывая его номер с использованием минимально возможного количества бит, одинакового для каждого спортсмена.
Каков информационный объем в битах сообщения, записанного устройством, после того как промежуточный финиш прошли 70 велосипедистов?
Рекомендации к решению.
Перед решением этой задачи следует проговорить ее условие, заменяя слова из него синонимами, которые можно найти в формулах.
Читаем условие очень внимательно, находим хотя бы один синоним – и задача практически решена, остается только подставить формулы и получить ответ!
Чтобы легче запомнить задачи 1 типа, будем называть их общим термином «велосипедисты».
Решение.
Есть 119 спортсменов с различными номерами, т.е. 119 вариантов различных номеров, тогда Q=119.
Так как Q = Мk, то для одного номера получаем Q = 119 ≤ 128=27, откуда k=7.
Тогда для N = 70 номеров получаем информационный объем сообщения
I = N * k = 70 * 7 = 490 бит.
Также для вычисления значения бита на символ можно использовать математическое решение формулы Хартли:
k= log2N
В данном случае k= log28 = 3.
Ответ: 490
Задача 2 типа.
Объем сообщения, содержащего 4096 символов, равен 1/512 части Мбайт. Какова мощность алфавита, с помощью которого записано это сообщение?
Рекомендации к решению.
Задачи данного типа – чисто математические (так и запомним их определение), и здесь очень полезно использовать таблицы степеней двойки и соответствия единиц измерения количества информации.
Подставляем числовые значения в формулы, заменяем числа степенями числа 2 и упрощаем. При этом не забываем привести единицы измерения к одному виду и помнить, что k – это бит на символ!
Решение.
Воспользовавшись таблицей степеней двойки, имеем: N = 4096 = 212 символов, тогда I =1/512 Мбайта = 223/29=214 бит. Отсюда k = I/N = 214/212=22=4 бита на символ.
Тогда мощность алфавита (количество различных вариантов символов)
М=24 = 16 символов.
Ответ: 16
Задача 3 типа.
В некоторой стране автомобильный номер длиной 7 символов составляется из заглавных букв (всего используется 26 букв) и десятичных цифр в любом порядке. Каждый символ кодируется одинаковым и минимально возможным количеством бит, а каждый номер – одинаковым и минимально возможным целым количеством байт.
Определите объем памяти, необходимый для хранения 20 автомобильных номеров.
Рекомендации к решению.
Решая задачи данного типа, необходимо обратить внимание на слова «каждый символ» и «каждый номер», которые подразумевают разделение информации при решении. Поэтому при решении задач 3 типа следует сначала считать объем одного номера в битах, перевести его в байты (с округлением до целого числа в большую сторону!) и только потом искать общий объем на несколько номеров.
Округление в большую сторону при вычислении объема одного номера необходимо, чтобы не потерять ни одного символа кодируемой информации.
Запомним, что округление при вычислении объемов информации всегда будем выполнять в большую сторону!
Будем так и называть этот тип задач – «автомобильные номера», хотя здесь встречаются и задачи на нахождение паролей (решение задач от этого не зависит).
Решение.
Особенность решения данной задачи – решение в два шага, т.е. поиск двух видов объема:
I1 — отдельно для каждого номера, I2 – для всех номеров.
Шаг 1. Мощность используемого алфавита Q = 26 + 10 = 36 ≤26, откуда k=6 бит на символ. Тогда I1 = 7*6=42 бита = 6 байт на один номер.
Шаг 2.Следовательно, на 20 номеров требуется I2 = 20 * 6 = 120 байт.
Ответ: 120
Для проверки правильности рассуждений пересчитаем объем без учета рекомендаций, данных ранее, и сравним итоги.
Мощность используемого алфавита и значение k=6 бит на символ остаются. Тогда объем одного номера I1 = 7*6=42 бита, а 20 номеров I2 = 42 * 20 = 840 бит = 105 байт.
В итоге потеряны 15 байт информации, а это значит, что не все номера были бы закодированы.
Задача 4 типа.
В школьной базе данных хранятся записи, содержащие информацию об учениках:
-
-16 символов: русские буквы (первая прописная, остальные строчные),
-
-12 символов: русские буквы (первая прописная, остальные строчные),
-
— 16 символов: русские буквы (первая прописная, остальные строчные),
-
— числа от 1992 до 2003.
Каждое поле записывается с использованием минимально возможного количества бит. Определите минимальное количество байт, необходимое для кодирования одной записи, если буквы е и ё считаются совпадающими.
Рекомендации к решению.
Перед решением задач данного типа вспомним, что базы данных (далее – БД) состоят из записей, которые делятся на поля.
И преимущество БД перед другим способом хранения информации в том, что поля в одной записи могут иметь разные форматы данных(числовые, символьные, даты и др.), которые кодируются соответственно их форматам.
Поэтому для подсчета общего объема одной записи следует считать объем каждого поля отдельно, а затем сложить их.
При этом помним, что в таблице ASCII (так как таблица кодировки в условии задачи не указана, берем ее по умолчанию) каждый символ занимает один байт памяти. Число (до определенного значения) – тоже кодируется одним байтом памяти.
Запомним определение задач 4 типа как «базы данных».
Решение.
Определяем минимально возможные размеры в битах для каждого из полей (в данном случае – четырех) с учетом их типов отдельно.
Так как по условию задачи первые буквы имени, отчества и фамилии – всегда заглавные, то будем хранить их в виде строчных и делать заглавными только при выводе на экран.
Таким образом, для символьных полей достаточно использовать алфавит из 32 символов (русские строчные буквы, «е» и «ё» совпадают, пробелы не нужны).
Для кодирования каждого символа 32-символьного алфавита нужно 5 бит (32 = 25), то для хранения имени, отчества и фамилии нужно (16 + 12 + 16)•5=220 бит.
Для года рождения есть 12 вариантов чисел, поэтому для него нужно отвести 4 бита
(12 ≤ 16 = 24).
Таким образом, всего требуется 220+4 = 224 бита или 28 байт.
Ответ: 28
Задача 5 типа (1).
В зоопарке 32 обезьяны живут в двух вольерах, А и Б. Одна из обезьян заболела. Сообщение «Заболевшая обезьяна живет в вольере А» содержит 4 бита информации.
Сколько обезьян живут в вольере Б?
Рекомендации к решению.
Заметим, что условие этой задачи отличается от задачи 1 типа только тем, что там все номера считались как единая информация, а здесь требуется выбор мотка определенного цвета, т.е. вся информация разделена на части.
Поэтому в решении задач 5 типа делается один дополнительный шаг — определяется, какую часть от общего количества составляет выделенная информация.
Решение.
По условию, красные клубки составляют 1/8 часть от целого (от всех клубков).
Поэтому сообщение о том, что первый вынутый клубок шерсти – красный, соответствует выбору одного из 8 вариантов, и это будет: Q = 8 = 23, что дает нам k = 3 бит.
(Можно запомнить решение задач 5 типа без дробей и дополнительных объяснений: в дополнительном по отношению к задачам 1 типа шаге находим Q = 32/4 = 8 вариантов, а затем решаем, как и задачи 1 типа: Q = 8 = 23, что дает нам k = 3 бит).
Ответ: 3
Задача 5 типа (2).
В зоопарке 32 обезьяны живут в двух вольерах, А и Б. Одна из обезьян заболела. Сообщение «Заболевшая обезьяна живет в вольере А» содержит 4 бита информации.
Сколько обезьян живут в вольере Б?
Решение.
Почему эта задача относится к 5 типу? Потому что информация разделена на части – обезьяны здоровые и больные.
Решается она в порядке, обратном решению предыдущей задачи.
Итак, информация в 4 бита соответствует выбору одного из 16 вариантов, поэтому в вольере А живет 1/16 часть всех обезьян: 32/16 = 2 обезьяны
Тогда в вольере Б живут все оставшиеся 32 – 2 = 30 обезьян.
Описание задач 5 типа можно определить и запомнить как задачи «про шары и обезьян».
Ответ: 30
Задачи смешанных типов.
Усвоив решение каждого типа задач отдельно, можно рассмотреть задачи смешанных типов.
Для их успешного решения необходимо прежде всего внимательно рассмотреть условие задачи, чтобы не пропустить это смешивание, а потом уже решать с учетом всех тонкостей, описанных ранее.
Разберем две из таких задач.
Задача 1.
При регистрации в компьютерной системе каждому пользователю выдаётся идентификатор, состоящий из 8 символов, первый и последний из которых – одна из 18 букв, а остальные – цифры (допускается использование 10 десятичных цифр.
Каждый такой идентификатор в компьютерной программе записывается минимально возможным и одинаковым целым количеством байт (при этом используют посимвольное кодирование; все цифры кодируются одинаковым и минимально возможным количеством бит, все буквы также кодируются одинаковым и минимально возможным количеством бит).
Определите объём памяти в байтах, отводимый этой программой для записи 500 паролей.
Решение.
Рассмотрим условие и разделим его на части, относящиеся к разным типам задач.
В первом абзаце говорится, что идентификатор состоит из букв и цифр в определенном порядке, а они кодируются по-разному. Это подтверждается и во-втором абзаце, где способ кодировки для цифр и букв описывается отдельно. Следовательно, каждый идентификатор рассматривается как запись из БД, то есть эта часть задачи относится к типу 4.
Во втором абзаце условия так же сказано, что каждый идентификатор записывается минимально возможным и одинаковым целым количеством байт, а посимвольное (т.е. для каждого символа отдельно) кодирование выполняется минимальным количеством бит для каждого вида символов. Следовательно, эта часть задачи относится к типу 3.
Тогда решение будет следующим:
В идентификаторе шесть цифр из алфавита мощностью 10 символов.
Тогда k1=4 и I1=6*k1=24 бита.
Вторая часть идентификатора длиной 2 символа состоит из алфавита мощностью 18 символов. Тогда k2=5 и I2=2*k2=10 бит.
Значит, объем одного идентификатора равен I1 + I2 = 24 + 10 = 34 бита.
Далее решаем задачу соответственно решению, описанному в 3 типе задач:
34 бита = 5 байт,
Общий объем 500 идентификаторов равен I = 5*500=2500 байт.
Ответ: 2500
Задача 2.
При регистрации в компьютерной системе каждому пользователю выдаётся пароль, состоящий из 15 символов и содержащий только символы из 12-символьного набора. В базе данных для хранения сведений о каждом пользователе отведено одинаковое и минимально возможное целое число байт. При этом используют посимвольное кодирование паролей, все символы кодируют одинаковым и минимально возможным количеством бит.
Кроме собственно пароля, для каждого пользователя в системе хранятся дополнительные сведения, для чего отведено 12 байт на одного пользователя.
Определите объём памяти (в байтах), необходимый для хранения сведений о 50 пользователях. В ответе запишите только целое число – количество байт.
Решение.
В условии сказано, что сведения о пользователях хранятся в БД, где запись состоит из двух полей – собственно идентификатора и дополнительных сведений (тип 4).
При этом идентификатор рассчитывается как в задачах 1 типа, а дополнительные сведения заданы конкретным значением и расчет их не нужен.
Тогда решение будет следующим:
Мощность используемого алфавита Q = 12 ≤24, откуда k=4 бита на символ. Тогда I1 = 15*4 = 60 бит = 8 байт на один идентификатор.
Объем одной записи равен I1+2 = 8 + 12 = 20 байт.
Следовательно, для 50 записей требуется I50 = 20 * 50 = 1000 байт.
Ответ: 1000
КОДИРОВАНИЕ И ДЕКОДИРОВАНИЕ
Кодирование – это перевод информации в удобную для передачи, обработки или хранения форму с помощью некоторого кода. В компьютере символы, изображения, музыка – все кодируется двоичным кодом.
Двоичный код — это способ представления данных в виде кода, в котором каждый разряд принимает одно из двух возможных значений, обычно обозначаемых цифрами 0 и 1. 0 и 1 – это алфавит двоичной системы счисления. Основание двоичной системы счисления – q =2, т.к. в алфавит входят всего две цифры.
Для решения задач на двоичное кодирование необходимо:
1) уметь строить таблицу соответствия двоичных чисел десятичным, восьмеричным и шестнадцатеричным числам (знать алфавиты данных систем счисления и двоичную арифметику(8 класс))
2) уметь переводить из двоичной системы счисления в восьмеричную, шестнадцатеричную, десятичную и обратно (8 класс)
Примеры задач на кодирование:
1. Для кодирования букв О, В, Д, П, А решили использовать двоичное представление чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления). Закодируйте последовательность букв ВОДОПАД таким способом и результат запишите восьмеричным кодом.
Алгоритм решения:
1) строим таблицу из того, что дано по условию задачи:
|
O |
В |
Д |
П |
А |
|
0 |
1 |
2 |
3 |
4 |
2) Вычисляем двоичное представление чисел 0, 1, 2, 3 и 4: для этого строим таблицу соответствия двоичной (с сохранением одного незначащего нуля в случае одноразрядного представления) и десятичной системы:
|
q=10 |
q=2 |
|
0 |
00 |
|
1 |
01 |
|
2 |
10 |
|
3 |
11 |
|
4 |
100 |
|
5 |
101 |
|
6 |
110 |
|
7 |
111 |
3) Записываем двоичные числа в таблицу:
|
O |
В |
Д |
П |
А |
|
0 |
1 |
2 |
3 |
4 |
|
00 |
01 |
10 |
11 |
100 |
4) Записываем двоичную последовательность для указанного слова ВОДОПАД = 01 00 10 00 11 100 10
5) Переводим полученное число двоичной системы счисления в указанную систему (в данном случае в восьмеричную):
ВОДОПАД = 010010001110010
Для этого делим СПРАВА налево полученное число на ТРИАДЫ (если переводим в шестнадцатеричную систему, то разделяем на ТЕТРАДЫ (группы по 4)): получится 010 010 001 110 010 и каждое полученное трехразрядное число переводим в восьмеричную систему счисления по уже созданной таблице (она включает числа от 0 до 7 – что совпадает с алфавитом восьмеричной системы счисления):
|
010 |
010 |
001 |
110 |
010 |
|
2 |
2 |
1 |
6 |
2 |
Ответ: 22162
2. Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=1, Б=01, В=001. Как нужно закодировать букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
1) 0001
2) 000
3) 11
4) 101
Алгоритм решения:
1) Находим среди вариантов двоичное число с наименьшим количеством разрядов, в данном случае это 11
2) Проверяем можно ли закодировать однозначно букву Г этим числом: А=1, поэтому, 11 можно принять как АА, таким образом это число не подходит
3) Находим следующее число после 11 с наименьшим количеством разрядов: 000 и 101.
4) Проверяем, можно ли закодировать букву Г данными числами: 101 можно принять как АБ, т.е. этот вариант не подходит. 000 – подходит.
Ответ: 2)000
ИЗМЕРЕНИЕ ИНФОРМАЦИИ.
ЕДИНИЦЫ ИЗМЕРЕНИЯ ИНФОРМАЦИИ
Основная единица измерения информации – бит.
Существует несколько подходов к измерению информации – алфавитный и содержательный. В алфавитном подходе речь идет об объеме информации. Количество символов в алфавите называется мощностью алфавита (N), а то, сколько «весит» один символ в битах – информационным весом символа (i). Чем больше символов в тексте, тем больше будет объем сообщения. Содержательный подход говорит не об объеме сообщения, а о количестве информации, которое человек может получить из него. В данном случае сообщение, уменьшающее неопределенность знания в два раза будет нести 1 бит информации. Если сообщение не несет нового знания и не убирает неопределенность, то оно несет в себе 0 бит, в независимости от того, сколько символов в данном сообщении.
Что нужно знать:
1) Единицы измерения информации и их перевод(8класс):
8 бит = 1 байт
1024 байта = 210 байта = 1 Кбайт
1024 Кб = 210 Кб = 1 Мб
1024 Мб = 210 Мб = 1 Гб
1024 Гб = 210 Гб = 1 Тб
2) Главную формулу информатики (7-9 класс):
N = 2i, где N – количество информации, i – количество бит на единицу информации.
3) Применение главной формулы информатики для алфавитного и содержательного подхода:
|
Алфавитный подход |
Содержательный подход |
|
|
N |
мощность алфавита (количество символов в алфавите) |
количество равновероятных вариантов |
|
i |
информационный вес одного символа алфавита в битах |
количество бит в одном сообщении |
4)Целые степени двойки для вычисления i:
|
i |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
2i |
1 |
2 |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
5) Формулу информационного объема сообщения:
I = K*i, где I – объем сообщения, K – количество символов в сообщении, i – количество бит на один символ сообщения.
Примеры задач:
1. B некоторой стране автомобильный номер длиной 6 символов составляют из заглавных букв (используются только 33 различных буквы) и десятичных цифр в любом порядке. Каждый такой номер в компьютерной программе записывается минимально возможным и одинаковым целым количеством байтов (при этом используют посимвольное кодирование и все символы кодируются одинаковым и минимально возможным количеством битов). Определите объём памяти, отводимый этой программой для записи 125 номеров. (Ответ дайте в байтах.)
Алгоритм решения:
1) находим N – в данном случае 33+10 = 43
2) находим i по формуле N = 2i: 25 (32)– мало, 26 (64) – достаточно, значит i = 6 бит (на один символ номера)
3) находим I номера (т.е. количество информации в одном номере): К = 6, i = 6, значит I = 36 бит (6 символов в номере – каждый по 6 бит)
4) Переводим в байты и округляем В БОЛЬШУЮ СТОРОНУ (ВСЕГДА!): 36/8 = 4,5 байта – не целое число, в большую сторону = 5 байт на 1 номер
5) Находим I для общего количества номеров: 125 номеров, каждый по 5 байт – 125*5 = 625 байт
Ответ: 625 байт
2. В скачках участвуют 20 лошадей. Специальное устройство регистрирует прохождение каждой лошадью финиша, записывая ее номер с использованием минимально возможного количества бит, одинакового для каждой лошади. Каков информационный объем сообщения, записанного устройством, если до финиша добрались только 15 из 20 участвовавших в скачках лошадей? (Ответ дайте в битах.)
Это подобная задача, алгоритм почти тот же.
N = 20 (т.к. всего лошадей 20), i = 5 бит на одну лошадь, т.к. 24= 16 – мало, К = 15, т.к. из 20 только 15 добрались до финиша. I = 15*5 = 45 бит на 15 лошадей
Ответ: 45 бит
3. В корзине лежат 32 клубка шерсти, из них 4 красных. Сколько бит информации несет сообщение о том, что достали клубок красной шерсти?
Задача на содержательный подход. Алгоритм решения:
1) Находим какую часть от 32 составляет 4 клубка: 4 шара – 1/8 от 32
2) Если 1/8 часть – то частей всего – 8, т.е. количество вариантов – 8, иными словами N=8
3) N=8, значит i = 3 бита
Ответ: 3 бита
4. В корзине лежат 32 шаров. Сообщение о том, что из корзины достали красный шар содержит 3 бита. Сколько красных шаров?
Это обратная задача. Алгоритм:
1) i = 3 бита, значит N = 8, т.е. 1/8 от всех шаров
2) Всего шаров 32. 1/8 от 32 – 4 шара красных.
(находим сколько частей, находим какая это часть от всего количества, находим количество)
Ответ: 4 шара
Автор материалов — Лада Борисовна Есакова.
При работе с вычислительной техникой, информационным объемом сообщения называют количество двоичных символов, которое используют для кодирования этого сообщения.
Чтобы найти информационный объем сообщения I, нужно количество символов этого сообщения N умножить на количество бит, выделяемых для кодирования одного символа
K : I = N * K.
Количество символов в некотором алфавите называется мощностью алфавита.
Несложно понять, что количество слов длиной N, составленных из символов (букв) алфавита мощностью M равно MN.
При компьютерном кодировании мощность алфавита равна 2, значит количество слов длиной N равно 2N.
Подсчет количества буквенных цепочек
Пример 1.
Все 5-буквенные слова, составленные из букв А, О, У, записаны в алфавитном порядке. Вот начало списка:
1. ААААА
2. ААААО
3. ААААУ
4. АААОА
……
Запишите слово, которое стоит на 210-м месте от начала списка.
Решение:
Заменим буквы А, О, У на 0, 1, 2 и выпишем начало списка:
1. 00000
2. 00001
3. 00002
4. 00010
…
Полученная запись есть числа, записанные в троичной системе счисления в порядке возрастания. Тогда на 210 месте будет стоять число 209 (т. к. первое число 0). Переведём число 209 в троичную систему: 20910 = 212023
Заменим обратно цифры на буквы и получим УОУАУ.
Ответ: УОУАУ
Пример 2.
Сколько слов длины 6, начинающихся с согласной буквы, можно составить из букв Г, О, Д? Каждая буква может входить в слово несколько раз. Слова не обязательно должны быть осмысленными словами русского языка.
Решение:
На первом месте может стоять две буквы: Г или Д, на остальных — три буквы.
Слов, начинающихся на Г, 35. Слов, начинающихся на Д, тоже 35.Таким образом, можно составить 2 · 35 = 486 слов.
Ответ: 486
Пример 3.
Вася составляет 5-буквенные слова, в которых есть только буквы С, Л, О, Н, причём буква С используется в каждом слове ровно 1 раз. Каждая из других допустимых букв может встречаться в слове любое количество раз или не встречаться совсем. Словом считается любая допустимая последовательность букв, не обязательно осмысленная. Сколько существует таких слов, которые может написать Вася?
Решение:
Пусть С стоит в слове на первом месте. Тогда на каждое из оставшихся 4 мест можно поставить независимо одну из 3 букв. То есть всего 3*3*3*3 = 81 вариант. Таким образом, С можно по очереди поставить на все 5 мест, в каждом случае получая 81 вариант. Итого получается 81 * 5 = 405 слов.
Ответ: 405
Количество информации при двоичном (компьютерном) кодировании
Пример 4.
Объем сообщения – 7,5 Кбайт. Известно, что данное сообщение содержит 7680 символов. Какова мощность алфавита?
Решение:
Объем сообщения I, написанного в исходном алфавите мощности M, содержащего N символов, равен: I = log2M * N
I = 7680 * log2M
Log2M = (7,5 * 213 бит) / 7680 =(7,5 * 213) /(15 * 29) = 8
M = 28 = 256
Ответ: 256
Количество информации при различных (не компьютерных) способах кодирования
Пример 5.
Азбука Морзе позволяет кодировать символы для сообщений по радиосвязи, задавая комбинацию точек и тире. Сколько различных символов (цифр, букв, знаков пунктуации и т. д.) можно закодировать, используя код азбуки Морзе длиной не менее четырёх и не более пяти сигналов (точек и тире)?
Решение:
Мы имеем алфавит из двух букв: точка и тире. Из двух букв можно составить 24 четырёхбуквенных слова и 25 пятибуквенных слов.
Значит, всего можно закодировать 16 + 32 = 48 различных символов.
Ответ: 48
Пример 6.
Световое табло состоит из лампочек. Каждая лампочка может находиться в одном из трех состояний («включено», «выключено» или «мигает»). Какое наименьшее количество лампочек должно находиться на табло, чтобы с его помощью можно было передать 18 различных сигналов?
Решение:
Мощность алфавита M =3 («включено», «выключено» или «мигает»).
Количество различных сигналов 18 <= MN= 3N. (Поскольку равенство не выполняется, N берем с избытком, иначе не сможем закодировать все сигналы). N = 3.
Ответ: 3
Благодарим за то, что пользуйтесь нашими публикациями.
Информация на странице «Задача №10. Измерение количества информации. Основы комбинаторики.» подготовлена нашими авторами специально, чтобы помочь вам в освоении предмета и подготовке к экзаменам.
Чтобы успешно сдать нужные и поступить в ВУЗ или техникум нужно использовать все инструменты: учеба, контрольные, олимпиады, онлайн-лекции, видеоуроки, сборники заданий.
Также вы можете воспользоваться другими материалами из данного раздела.
Публикация обновлена:
09.03.2023
Теория
| 1. | Методы измерения количества информации | |
| 2. | Как решать задание ЕГЭ |
Задания
| 1. |
Задание для подготовки № 1
Сложность: |
1 |
| 2. |
Задание для подготовки № 2
Сложность: |
1 |
| 3. |
Задание для подготовки № 3
Сложность: |
1 |
Экзаменационные задания (подписка)
| 1. |
Как на ЕГЭ (1). Измерение количества информации
Сложность: |
1 |
| 2. |
Как на ЕГЭ (2). Измерение количества информации
Сложность: |
1 |
| 3. |
Как на ЕГЭ (3). Измерение количества информации
Сложность: |
1 |
| 4. |
Как на ЕГЭ (4). Измерение количества информации
Сложность: |
1 |
Тесты
| 1. |
Тренировочная работа по теме Задание № 8. Измерение количества информации
Сложность: среднее |
4 |
Материалы для учителей
| 1. | Методическое описание |