Программа дисциплины
Аннотация
Целью освоения дисциплины «Хранилища данных» является обеспечение обучающихся основополагающими знаниями в области современных способов хранения информации и анализа данных, а также приобретение слушателями навыков по созданию хранилищ данных заданной архитектуры и по анализу данных. В ходе изучения дисциплины перед обучающимися ставятся следующие задачи: изучение методов анализа данных; изучение методологии создания хранилищ данных; освоение основных технологий для создания хранилищ данных; изучение программных средств, используемых при создании хранилищ данных; формирование практических навыков проектирования хранилищ данных; формирование навыков работы со специальной литературой.

Цель освоения дисциплины
-
Формирование знаний, умений и навыков проектирования и администрирования хранилищ данных (ХД), разработки приложений (внешних интерфейсов) ХД, использования средств многомерного анализа данных класса OLAP

Планируемые результаты обучения
-
Описывает архитектуру программных средств, работающих с ХД
-
Отличает особенности многомерной модели ХД
-
Анализирует подходы к построению ХД и сфер их применимости
-
Объясняет теорию многомерных ХД: схемы типа «Звезда», «Снежинка», метод Data Vault Modeling, ETL-процедуры, ROLAP и др.
-
Применяет навыки проектирования структуры ХД
-
Применяет инструментальные средства СУБД при реализации модели ХД
-
Разрабатывает проект ХД вручную и с использованием выбранного CASE-средства
-
Показывает навыки анализа данных с использованием ХД
-
Показывает навыки формирования MDX-запросов к ХД
-
Применяет язык манипулирования (построения запросов) многомерными данными MDX

Содержание учебной дисциплины
-
Хранилища данных (ХД) — причины возникновения
-
Архитектура ХД
-
Основные принципы проектирования ХД
-
Проектирование и разработка процесса наполнения ХД
-
Физическая модель ХД
-
Использование ХД в процессе анализа данных

Элементы контроля
-
неблокирующий
Работа на лекции
Студентам дается задание в конце лекции в виде теста
-
неблокирующий
Работа на семинаре
На семинарах дается оцениваемое домашнее задание
-
неблокирующий
Контрольная работа
Набор тестовых заданий на один час
-
неблокирующий
Контрольное домашнее задание
Групповой проект
-
Тест по окончанию курса. Тест представляет из себя набор вопросов закрытого типа. Форма экзамена:
Экзамен проводится в письменной форме.Платформа проведения:
Экзамен проводится на платформе Canvas LMS.Для участия в экзамене студент обязан:
Не позднее 7 дней до проведения экзамена проверить работоспособность компьютерного оборудования, необходимого для сдачи экзамена и убедиться в соответствие имеющегося оборудования требованиям к компьютеру для участия в экзамене на платформе Canvas LMS;
Войти на платформу Canvas LMS под личной учетной записью (используется аккаунт студента @edu.hse.ru);
Перед началом экзамена проверить скорость работы сети Интернет (для наилучшего результата рекомендуется подключение компьютера к сети через кабель);
Подготовить необходимые для проведения экзамена инструменты: ручка, листы бумаги, калькулятор и т. д.;
Отключить в диспетчере задач компьютера иные приложения, кроме браузера, в котором будет выполняться вход на платформу Canvas LMS, а также необходимого окружения СУБД.В случае, если одно из необходимых условий участия в экзамене невозможно выполнить, необходимо за 2 недели до даты проведения экзамена проинформировать об этом преподавателя или сотрудника учебного офиса для принятия решения об участии студента в экзаменах.
Во время экзамена студентам запрещено:
Пользоваться конспектами, учебниками, прочими учебными материалами;
Покидать место выполнения экзаменационного задания;
Пользоваться умными гаджетами (смартфон, планшет и др.);
Привлекать посторонних лиц для помощи в проведении экзамена, разговаривать с посторонними во время выполнения заданий;
Вслух громко зачитывать задания.Во время экзамена студентам разрешено:
Использовать бумагу, ручку для ведения записей, расчетов;
Использовать калькулятор для ведения расчетов;
Запрашивать у преподавателя дополнительную информацию, связанную с выполнением экзаменационного задания;
Взаимодействовать с другими студентами по разрешению преподавателя.В случае долговременного нарушения связи с платформами MS Teams и Canvas LMS во время выполнения экзаменационного задания, студент должен уведомить об этом преподавателя, зафиксировать факт потери связи с платформой (скриншот, ответ от провайдера сети Интернет) и обратиться в учебный офис с объяснительной запиской о случившемся для принятия решения о пересдаче экзамена.

Промежуточная аттестация
-
2021/2022 учебный год 2 модуль
0.1 * Работа на лекции + 0.11 * Работа на семинаре + 0.3 * Экзамен + 0.15 * Контрольная работа + 0.34 * Контрольное домашнее задание

Список литературы
Рекомендуемая основная литература
-
Гордеев С. И., Волошина В. Н. — ОРГАНИЗАЦИЯ БАЗ ДАННЫХ В 2 Ч. ЧАСТЬ 1 2-е изд., испр. и доп. Учебник для вузов — М.:Издательство Юрайт — 2020 — 310с. — ISBN: 978-5-534-04469-0 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/organizaciya-baz-dannyh-v-2-ch-chast-1-452928
-
Гордеев С. И., Волошина В. Н. — ОРГАНИЗАЦИЯ БАЗ ДАННЫХ В 2 Ч. ЧАСТЬ 1 2-е изд., испр. и доп. Учебник для вузов — М.:Издательство Юрайт — 2021 — 310с. — ISBN: 978-5-534-04469-0 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/organizaciya-baz-dannyh-v-2-ch-chast-1-471758
-
Гордеев С. И., Волошина В. Н. — ОРГАНИЗАЦИЯ БАЗ ДАННЫХ В 2 Ч. ЧАСТЬ 2 2-е изд., испр. и доп. Учебник для вузов — М.:Издательство Юрайт — 2020 — 513с. — ISBN: 978-5-534-04470-6 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/organizaciya-baz-dannyh-v-2-ch-chast-2-454122
-
Гордеев С. И., Волошина В. Н. — ОРГАНИЗАЦИЯ БАЗ ДАННЫХ В 2 Ч. ЧАСТЬ 2 2-е изд., испр. и доп. Учебник для вузов — М.:Издательство Юрайт — 2021 — 513с. — ISBN: 978-5-534-04470-6 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/organizaciya-baz-dannyh-v-2-ch-chast-2-473007
-
Кондрашов Ю.Н. — Анализ данных и машинное обучение на платформе MS SQL Server — Русайнс — 2020 — 303с. — ISBN: 978-5-4365-3369-8 — Текст электронный // ЭБС BOOKRU — URL: https://book.ru/book/933497
-
Кондрашов Ю.Н. — Анализ данных и машинное обучение на платформе MS SQL Server — Русайнс — 2021 — 303с. — ISBN: 978-5-4365-7924-5 — Текст электронный // ЭБС BOOKRU — URL: https://book.ru/book/941049
-
Кондрашов Ю.Н. — Эффективное использование СУБД MS SQL Server — Русайнс — 2020 — 121с. — ISBN: 978-5-4365-4597-4 — Текст электронный // ЭБС BOOKRU — URL: https://book.ru/book/935743
-
Парфенов Ю. П. ; под науч. ред. Папуловской Н.В. — ПОСТРЕЛЯЦИОННЫЕ ХРАНИЛИЩА ДАННЫХ. Учебное пособие для вузов — М.:Издательство Юрайт — 2020 — 121с. — ISBN: 978-5-534-09837-2 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/postrelyacionnye-hranilischa-dannyh-453758
-
Парфенов Ю. П. ; под науч. ред. Папуловской Н.В. — ПОСТРЕЛЯЦИОННЫЕ ХРАНИЛИЩА ДАННЫХ. Учебное пособие для вузов — М.:Издательство Юрайт — 2021 — 121с. — ISBN: 978-5-534-09837-2 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/postrelyacionnye-hranilischa-dannyh-472624
-
Стружкин Н. П., Годин В. В. — БАЗЫ ДАННЫХ: ПРОЕКТИРОВАНИЕ. Учебник для вузов — М.:Издательство Юрайт — 2020 — 477с. — ISBN: 978-5-534-00229-4 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/bazy-dannyh-proektirovanie-450165
-
Стружкин Н. П., Годин В. В. — БАЗЫ ДАННЫХ: ПРОЕКТИРОВАНИЕ. Учебник для вузов — М.:Издательство Юрайт — 2021 — 477с. — ISBN: 978-5-534-00229-4 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/bazy-dannyh-proektirovanie-469021
Рекомендуемая дополнительная литература
-
— Интеллектуальный анализ данных средствами MS SQL Server 2008 — Национальный Открытый Университет «ИНТУИТ» — 2016 — ISBN: — Текст электронный // ЭБС ЛАНЬ — URL: https://e.lanbook.com/book/100609
-
Hartmann, S., & Alfermann, D. (2019). Practical Guide to SAP HANA and Big Data Analytics. Espresso Tutorials.
-
Perkins, L., Redmond, E., & Wilson, J. R. (2018). Seven Databases in Seven Weeks : A Guide to Modern Databases and the NoSQL Movement (Vol. Second edition). Raleigh, N. C: Pragmatic Bookshelf. Retrieved from http://search.ebscohost.com/login.aspx?direct=true&site=eds-live&db=edsebk&AN=1806794
-
Марасанов А.М., Аносова Н.П., Бородин О.О. — Распределенные базы и хранилища данных — Национальный Открытый Университет «ИНТУИТ» — 2016 — ISBN: — Текст электронный // ЭБС ЛАНЬ — URL: https://e.lanbook.com/book/100445
-
Стружкин Н. П., Годин В. В. — БАЗЫ ДАННЫХ: ПРОЕКТИРОВАНИЕ. ПРАКТИКУМ. Учебное пособие для вузов — М.:Издательство Юрайт — 2020 — 291с. — ISBN: 978-5-534-00739-8 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/bazy-dannyh-proektirovanie-praktikum-451246
-
Стружкин Н. П., Годин В. В. — БАЗЫ ДАННЫХ: ПРОЕКТИРОВАНИЕ. ПРАКТИКУМ. Учебное пособие для вузов — М.:Издательство Юрайт — 2021 — 291с. — ISBN: 978-5-534-00739-8 — Текст электронный // ЭБС ЮРАЙТ — URL: https://urait.ru/book/bazy-dannyh-proektirovanie-praktikum-470023
ОАД
— вопросы на зачёт
1.Хранилище
данных.
2. Система
поддержки принятия решений (СППР).
3. Отличия
CППP и ОLТР-систем.
4. Семантический
слой в хранилище данных.
5. Основные
требования к хранилищу данных.
6. Свойства
хранилища данных.
7. Структурная
схема хранилища данных.
8. Хранилище
данных — детализированные и агрегированные
данные.
9. Хранилище
данных — метаданные, бизнес-метаданные,
технический уровень.
10. Хранилище
данных — регламентированные,
нерегламентированные запросы.
11. Оперативный
анализ данных — OLAP систем.
12. Реляционные
OLAP системы — структурная схема, функционал.
13. Многомерные
OLAP системы -структурная схема, функционал.
14. Гибридные
OLAP системы — структурная схема, функционал.
15. Виртуальные
OLAP системы — структурная схема, функционал.
16. Многомерная
модель данных ОLАР-кубов.
17. Семантический
слой в виртуальных OLAP систем — структурная
схема, функционал.
18. Декомпозиция
ОLАР-кубов в виде двухмерных таблиц.
19. Базовые
понятия многомерной модели данных —
измерения и факты.
20. Структура
многомерного куба, привести пример.
21. Принцип
организации многомерного куба, привести
пример.
22. Потери,
при декомпозиции ОLАР-кубов в виде
двухмерных таблиц.
23. Компенсация
потерь при декомпозиции ОLАР-кубов в
виде двухмерных таблиц.
24. Преимущества
многомерного OLAP-подхода.
25. Недостатки
многомерного OLAP-подхода.
26. Операции
над измерениями — сечение, привести
пример.
27. Операции
над измерениями — транспонирование,
привести пример.
28. Операции
над измерениями — свертка, привести
пример.
29. Операции
над измерениями — детализация, привести
пример.
30. Операции
над измерениями — сечение с 1 измерением,
привести пример.
31. Операции
над измерениями — сечение с 2 измерениями,
привести пример.
32. Операции
над измерениями — сечение с 3 измерениями,
привести пример.
33. Реляционные
хранилища и база данных, их сходства и
различия.
34. Реляционные
OLAP системы — схема “звезда”, привести
пример.
35. Реляционные
OLAP системы — схема “снежинка”, привести
пример.
36. Реляционные
OLAP системы — отличия cxeм «звезда» и
«снежинка», привести пример.
37. Витрина
данных — структурная схема, функционал.
38.
Централизованное ХД с витринами данных
— структурная схема, функционал.
39. Аналитические
платформы — структурная схема, функционал.
40. Data Mining —
предназначение, полный цикл функционирования.
41. Data Мining —
классификация, задачи, привести пример.
42. Data Мining —
признаки классификации, основной,
второстепенный.
43. Data Мining —
признаки классификации, простой, сложный.
44. Data Мining —
этапы классификации.
45. Классификация
с помощью деревьев решений, пример.
46. Классификация
при помощи искусственных нейронных
сетей, пример.
47. Классификации
— бинарная, многоклассовая, пример.
48.
Характеристики, для оценки методов
классификации.
49. Классификация
— ошибки I и II рода, предназначение,
пример.
50. Классификация
— балансировка уровня ошибок I и II рода,
предназначение, пример.
51. Data Mining —
кластеризация, задачи, привести пример.
52. Data Mining —
кластеризация, типы кластеров.
53. Data Мining —
сравнение задач классификации и
кластеризации, пример.
54. Data Mining —
линейная регрессия, модель, предназначение,
пример.
55. Data Мining —
логистическая регрессия, модель,
предназначение, пример.
56. Data Мining —
генетические алгоритмы, предназначение,
пример.
57. Data Мining —
машинное обучение, обучающая выборка.
58. Data Mining —
машинное обучение, тестовая выборка.
59. Data Мining —
машинное обучение, эффект переобучения.
60. Data Мining-
машинное обучение, ошибки обучения и
обобщения.
Хранилище
данных — разновидность системы хранения,
ориентированная на поддержку анализа
данных. Обеспечивает целостность,
непротиворечивость, а также высокую
скорость выполнения аналитических
запросов.
Важнейшим
элементом ХД является семантический
слой — механизм, позволяющий аналитику
оперировать данными посредством
бизнес-терминов предметной области.
Семантический слой дает пользователю
возможность сосредоточиться на анализе
и не задумываться о механизмах получения
данных.
Типичное
ХД существенно отличается от обычных
систем хранения данных. Главным отличием
являются цели использования. Например,
регистрация продаж и выписка соответствующих
документов — задача уровня OLTP-систем,
использующих обычные реляционные СУБД.
Анализ динамики продаж и спроса за
несколько лет, позволяющий выработать
стратегию развития фирмы и спланировать
работу с поставщиками и клиентами,
удобнее всего выполнять при поддержке
ХД.
Другое
важное отличие заключается в динамике
изменения данных. Базы данных в
OLTP-системах характеризуются очень
высокой динамикой изменения записей
из-за повседневной работы большого
числа пользователей (откуда, кстати,
велика вероятность появления противоречий,
ошибок, нарушения целостности данных
и т.д.). Что касается ХД, то данные из него
не удаляются, а пополнение происходит
в соответствии с определенным регламентом
(раз в час, день, неделю, в определенное
время).
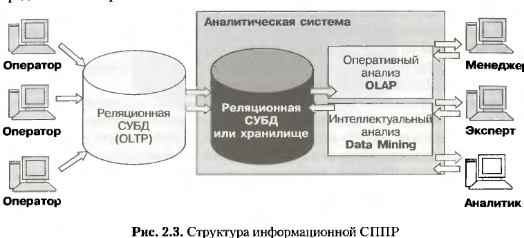
2. Система поддержки принятия решений (сппр). Ссылка Система поддержки принятия решений
или
СППР (Decision Support Systems, DSS) — это компьютерная
система, которая путем сбора и анализа
большого количества информации может
влиять на процесс принятия решений
организационного плана в бизнесе и
предпринимательстве. Интерактивные
системы позволяют руководителям получить
полезную информацию из первоисточников,
проанализировать ее, а также выявить
существующие бизнес-модели для решения
определенных задач. С помощью СППР можно
проследить за всеми доступными
информационными активами, получить
сравнительные значения объемов продаж,
спрогнозировать доход организации при
гипотетическом внедрении новой
технологии, а также рассмотреть все
возможные альтернативные решения.
Система
поддержки решений СППР решает две
основные задачи:
-
выбор наилучшего
решения из множества возможных
(оптимизация), -
упорядочение
возможных решений по предпочтительности
(ранжирование).
В
обеих задачах первым и наиболее
принципиальным моментом является выбор
совокупности критериев, на основе
которых в дальнейшем будут оцениваться
и сопоставляться возможные решения
(будем называть их также альтернативами).
Система СППР помогает пользователю
сделать такой выбор.
Наиболее
широкой сферой
практического применения СППР
являются планирование и прогнозирование
для различных видов управленческой
деятельности.
Пример
популярного типа СППР — СППР в виде
генератора финансового отчета. С помощью
электронной таблицы, например, Microsoft
Excel, создаются модели, чтобы прогнозировать
различные элементы организации или
финансового состояния. В качестве данных
используются предыдущие финансовые
отчеты организации. Начальная модель
включает различные предположения
относительно будущих трендов в категориях
расхода и дохода. После рассмотрения
результатов базовой модели менеджер
проводит ряд исследований типа «Что,
если…?», изменяя одно или большее
количество предположений, чтобы
определить их влияние на исходное
состояние. Это простые типы генератора
финансового отчета, но мощные СППР для
руководства принятием финансовых
решений.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #

Форма обучения:
дистанционная
Стоимость самостоятельного обучения:
бесплатно
Качество курса:
4.24 | 4.15
Целью курса является изучение теоретических основ и принципов построения хранилищ данных, приобретение практических навыков аналитической обработки данных.
В курсе рассматриваются принципы построения систем, ориентированных на анализ данных, различные модели данных, используемых для построения хранилищ данных. А также рассмотрены вопросы построение систем на основе хранилищ данных, доставка данных в хранилище, технология интеллектуального анализа данных и другие вопросы.
Дополнительные курсы
Кубы данных
Кубы данных (многомерная модель данных). Форматы хранения данных в OLAP кубах.
—
Построение OLAP срезов. Инструмент анализа Data Analyzer
Возможности построения OLAP срезов. Создание сводных диаграмм с данными OLAP-кубов. Создание локальных OLAP-кубов с помощью Microsoft Excel. Инструмент анализа Data Analyzer. Подключение к источникам данных. Создание отображений. Средства анализа данных.
—
Составление отчетов
Создание простого (статического) отчета табличного вида из многомерной базы данных (куба). Размещение отчета на Web-сервере. Просмотр отчета через Web-browser.
—
Что такое хранилище данных?
Хранилища данных (DW) является процессом сбора и управления данными из различных источников , чтобы обеспечить значимые бизнес — идею. Хранилище данных обычно используется для подключения и анализа бизнес-данных из разнородных источников. Хранилище данных является ядром системы BI, которая построена для анализа данных и отчетности.
Это смесь технологий и компонентов, которая помогает стратегическому использованию данных. Это электронное хранилище большого объема информации, предназначенное для бизнеса и предназначенное для обработки запросов и анализа вместо обработки транзакций. Это процесс преобразования данных в информацию и своевременного предоставления их пользователям, чтобы изменить ситуацию.
В этом уроке вы узнаете больше о
- История Datawarehouse
- Как работает Datawarehouse?
- Типы хранилищ данных
- Основные этапы хранилища данных
- Компоненты хранилища данных
- Кому нужно хранилище данных?
- Для чего используется хранилище данных?
- Шаги по внедрению хранилища данных
- Лучшие практики для реализации хранилища данных
- Зачем нам нужно хранилище данных? Преимущества недостатки
- Будущее хранилищ данных
- Инструменты хранилища данных
База данных поддержки принятия решений (хранилище данных) поддерживается отдельно от оперативной базы данных организации. Однако хранилище данных — это не продукт, а среда. Это архитектурная конструкция информационной системы, которая предоставляет пользователям текущую и историческую информацию поддержки принятия решений, которую трудно получить или представить в традиционном хранилище оперативных данных.
Многие знают, что база данных, разработанная 3NF для системы инвентаризации, имеет таблицы, связанные друг с другом. Например, отчет о текущей инвентарной информации может включать более 12 объединенных условий. Это может быстро замедлить время ответа на запрос и отчет. Хранилище данных предоставляет новый дизайн, который может помочь сократить время отклика и повысить производительность запросов для отчетов и аналитики.
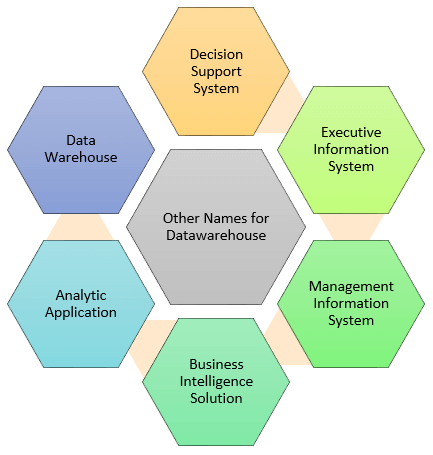
Система хранилища данных также известна под следующим именем:
- Система поддержки принятия решений (DSS)
- Исполнительная информационная система
- Информационная система управления
- Решение для бизнес-аналитики
- Аналитическое приложение
- Хранилище данных
История Datawarehouse
Datawarehouse помогает пользователям понимать и повышать производительность своей организации. Потребность в хранении данных развивалась по мере того, как компьютерные системы становились все более сложными и нужными для обработки растущих объемов информации. Тем не менее, хранилище данных не новость.
Вот некоторые ключевые события в эволюции хранилища данных:
- 1960 — Дартмут и Дженерал Миллс в совместном исследовательском проекте разрабатывают термины измерения и факты.
- 1970 — Nielsen и IRI представляют витрины размерных данных для розничных продаж.
- 1983 — Tera Data Corporation представляет систему управления базами данных, которая специально разработана для поддержки принятия решений
- Хранилище данных началось в конце 1980-х годов, когда сотрудник IBM Пол Мерфи и Барри Девлин разработали хранилище бизнес-данных.
- Однако настоящую концепцию дал Инмон Билл. Он считался отцом хранилища данных. Он написал о множестве тем для строительства, использования и обслуживания склада и Корпоративной информационной фабрики.
Как работает Datawarehouse?
Хранилище данных работает как центральное хранилище, куда информация поступает из одного или нескольких источников данных. Данные поступают в хранилище данных из транзакционной системы и других реляционных баз данных.
Данные могут быть:
- Структурированные
- Полуструктурированный
- Неструктурированные данные
Данные обрабатываются, преобразуются и принимаются, так что пользователи могут получить доступ к обработанным данным в хранилище данных с помощью инструментов бизнес-аналитики, клиентов SQL и электронных таблиц. Хранилище данных объединяет информацию, поступающую из разных источников, в одну комплексную базу данных.
Объединяя всю эту информацию в одном месте, организация может более целостно анализировать своих клиентов. Это помогает гарантировать, что он рассмотрел всю доступную информацию. Хранилище данных делает возможным интеллектуальный анализ данных. Data Mining ищет шаблоны данных, которые могут привести к увеличению продаж и прибыли.
Типы хранилищ данных
Три основных типа хранилищ данных:
1. Хранилище корпоративных данных:
Enterprise Data Warehouse — это централизованное хранилище. Он обеспечивает поддержку принятия решений по всему предприятию. Он предлагает унифицированный подход к организации и представлению данных. Это также дает возможность классифицировать данные в соответствии с предметом и предоставлять доступ в соответствии с этими подразделениями.
2. Оперативное хранилище данных:
Оперативное хранилище данных, которое также называют ODS, — это не что иное, как хранилище данных, которое требуется, когда ни хранилище данных, ни системы OLTP не поддерживают потребности организаций в отчетности. В ODS хранилище данных обновляется в режиме реального времени. Следовательно, это широко предпочитается для рутинных действий, таких как хранение записей сотрудников.
3. Data Mart:
Витрина данных является подмножеством хранилища данных. Он специально разработан для определенной сферы бизнеса, такой как продажи, финансы, продажи или финансы. В независимой витрине данных данные могут собираться непосредственно из источников.
Основные этапы хранилища данных
Ранее организации начали относительно простое использование хранилищ данных. Однако со временем началось более сложное использование хранилищ данных.
Ниже приведены общие этапы использования хранилища данных:
Оперативная база данных в автономном режиме:
На этом этапе данные просто копируются из операционной системы на другой сервер. Таким образом, загрузка, обработка и создание отчетов о скопированных данных не влияют на производительность операционной системы.
Автономное хранилище данных:
Данные в хранилище данных регулярно обновляются из оперативной базы данных. Данные в Datawarehouse отображаются и преобразуются в соответствии с целями Datawarehouse.
Хранилище данных в реальном времени:
На этом этапе хранилища данных обновляются всякий раз, когда в оперативной базе данных происходит какая-либо транзакция. Например, система бронирования авиабилетов или ж / д.
Интегрированное хранилище данных:
На этом этапе хранилища данных постоянно обновляются, когда операционная система выполняет транзакцию. Затем Datawarehouse генерирует транзакции, которые передаются обратно в операционную систему.
Компоненты хранилища данных
Четыре компонента хранилищ данных:
Диспетчер загрузки: Диспетчер загрузки также называется фронтальным компонентом. Он выполняет все операции, связанные с извлечением и загрузкой данных в хранилище. Эти операции включают преобразования для подготовки данных для ввода в хранилище данных.
Warehouse Manager: Warehouse Manager выполняет операции, связанные с управлением данными в хранилище. Он выполняет такие операции, как анализ данных, для обеспечения согласованности, создания индексов и представлений, генерации денормализации и агрегирования, преобразования и объединения исходных данных, а также архивирования и обработки данных.
Менеджер запросов: Менеджер запросов также известен как бэкэнд-компонент. Он выполняет все операции, связанные с управлением пользовательскими запросами. Операции этих компонентов хранилища данных являются прямыми запросами к соответствующим таблицам для планирования выполнения запросов.
Инструменты доступа конечного пользователя:
Он подразделяется на пять различных групп, таких как 1. Отчетность о данных 2. Инструменты запросов 3. Инструменты разработки приложений 4. Инструменты EIS, 5. Инструменты OLAP и инструменты интеллектуального анализа данных.
Кому нужно хранилище данных?
Хранилище данных необходимо для всех типов пользователей, таких как:
- Лица, принимающие решения, которые полагаются на большое количество данных
- Пользователи, которые используют настраиваемые сложные процессы для получения информации из нескольких источников данных.
- Он также используется людьми, которым нужна простая технология для доступа к данным.
- Это также важно для тех людей, которые хотят системного подхода к принятию решений.
- Если пользователь хочет быстрой работы с огромным объемом данных, который необходим для отчетов, таблиц или диаграмм, хранилище данных оказывается полезным.
- Хранилище данных — это первый шаг, если вы хотите обнаружить «скрытые шаблоны» потоков и группировок данных.
Для чего используется хранилище данных?
Вот наиболее распространенные сектора, где используется хранилище данных:
Авиакомпания:
В системе «Авиакомпания» она используется для оперативных целей, таких как назначение экипажа, анализ прибыльности маршрута, продвижение программ для часто летающих пассажиров и т. Д.
Банковское дело:
Он широко используется в банковском секторе для эффективного управления ресурсами, имеющимися на столе. Немногие банки также использовали для исследования рынка, анализа эффективности продукта и операций.
Здравоохранение:
Сектор здравоохранения также использовал хранилище данных для выработки стратегии и прогнозирования результатов, формирования отчетов о лечении пациентов, обмена данными со связанными страховыми компаниями, службами медицинской помощи и т. Д.
Государственный сектор:
В государственном секторе хранилище данных используется для сбора информации. Это помогает правительственным учреждениям вести и анализировать налоговые записи, записи политики здравоохранения для каждого человека.
Инвестиционно-страховой сектор:
В этом секторе склады в основном используются для анализа моделей данных, тенденций покупателей и отслеживания изменений на рынке.
Сохранить цепочку:
В розничных сетях хранилище данных широко используется для распространения и маркетинга. Он также помогает отслеживать товары, структуру покупок, рекламные акции, а также используется для определения ценовой политики.
Телекоммуникационная:
Хранилище данных используется в этом секторе для продвижения продукции, принятия решений о продажах и принятия решений о распространении.
Индустрия гостеприимства:
Эта отрасль использует складские услуги для разработки, а также оценки своих рекламных и рекламных кампаний, где они хотят ориентироваться на клиентов, на основе их отзывов и моделей поездок.
Шаги по внедрению хранилища данных
Лучший способ устранить бизнес-риски, связанные с реализацией Datawarehouse, — это использовать стратегию, состоящую из трех частей, как показано ниже
- Стратегия предприятия : здесь мы определяем технические, включая текущую архитектуру и инструменты. Мы также определяем факты, размеры и атрибуты. Отображение данных и преобразование также передается.
- Поэтапная доставка : внедрение Datawarehouse должно осуществляться поэтапно в зависимости от предметных областей. Связанные бизнес-объекты, такие как бронирование и выставление счетов, должны быть сначала реализованы, а затем интегрированы друг с другом.
- Итеративное прототипирование : вместо подхода большого взрыва к реализации, Datawarehouse следует разрабатывать и тестировать итеративно.
Вот ключевые шаги в реализации Datawarehouse вместе с его результатами.
| шаг | Задания | Практические результаты |
| 1 | Необходимо определить масштаб проекта | Определение области |
| 2 | Необходимо определить потребности бизнеса | Логическая модель данных |
| 3 | Определить требования к операционному хранилищу данных | Модель хранилища оперативных данных |
| 4 | Приобретать или разрабатывать инструменты для извлечения | Извлечение инструментов и программного обеспечения |
| 5 | Определить требования к хранилищу данных | Модель данных перехода |
| 6 | Документ пропущенных данных | Сделать список проектов |
| 7 | Сопоставляет оперативное хранилище данных с хранилищем данных | Карта интеграции данных D / W |
| 8 | Разработка базы данных хранилища данных | Дизайн базы данных D / W |
| 9 | Извлечение данных из оперативного хранилища данных | Интегрированные экстракты данных D / W |
| 10 | Загрузить хранилище данных | Начальная загрузка данных |
| 11 | Ведение хранилища данных | Постоянный доступ к данным и последующие загрузки |
Лучшие практики для реализации хранилища данных
- Определите план проверки согласованности, точности и целостности данных.
- Хранилище данных должно быть хорошо интегрировано, четко определено и с временными отметками.
- При разработке Datawarehouse убедитесь, что вы используете правильный инструмент, придерживайтесь жизненного цикла, позаботьтесь о конфликтах данных и будьте готовы к тому, что вы ошибаетесь.
- Никогда не заменяйте операционные системы и отчеты
- Не тратьте слишком много времени на извлечение, очистку и загрузку данных.
- Убедитесь, что все заинтересованные стороны, включая бизнес-персонал, вовлечены в процесс внедрения Datawarehouse. Установить, что хранилище данных является совместным / групповым проектом. Вы не хотите создавать хранилище данных, которое бесполезно для конечных пользователей.
- Подготовьте план обучения для конечных пользователей.
Зачем нам нужно хранилище данных? Преимущества недостатки
Преимущества хранилища данных:
- Хранилище данных позволяет бизнес-пользователям быстро получать доступ к критически важным данным из некоторых источников в одном месте.
- Хранилище данных предоставляет согласованную информацию о различных межфункциональных действиях. Он также поддерживает специальные отчеты и запросы.
- Хранилище данных помогает интегрировать множество источников данных, чтобы снизить нагрузку на производственную систему.
- Хранилище данных помогает сократить общее время обработки для анализа и отчетности.
- Реструктуризация и интеграция упрощают использование отчетов и анализа.
- Хранилище данных позволяет пользователям получать доступ к критически важным данным из нескольких источников в одном месте. Таким образом, это экономит время пользователя на получение данных из нескольких источников.
- Хранилище данных хранит большое количество исторических данных. Это помогает пользователям анализировать различные периоды времени и тенденции, чтобы делать прогнозы на будущее.
Недостатки хранилища данных:
- Не идеальный вариант для неструктурированных данных.
- Создание и внедрение хранилища данных — это, безусловно, запутанное время.
- Хранилище данных может сравнительно быстро устареть
- Трудно вносить изменения в типы данных и диапазоны, схему источника данных, индексы и запросы.
- Хранилище данных может показаться простым, но на самом деле оно слишком сложное для обычных пользователей.
- Несмотря на все усилия по управлению проектами, объем проекта хранилищ данных всегда будет увеличиваться.
- Иногда пользователи склада разрабатывают различные бизнес-правила.
- Организации должны тратить много своих ресурсов на обучение и внедрение.
Будущее хранилищ данных
- Изменения в нормативных ограничениях могут ограничивать возможность объединения источников разнородных данных. Эти разрозненные источники могут включать неструктурированные данные, которые трудно хранить.
- По мере увеличения размера баз данных оценки того, что составляет очень большую базу данных, продолжают расти. Сложно создавать и запускать системы хранилищ данных, размер которых постоянно увеличивается. Доступные сегодня аппаратные и программные ресурсы не позволяют хранить большой объем данных в сети.
- Мультимедийные данные не могут быть легко обработаны как текстовые данные, тогда как текстовая информация может быть получена с помощью реляционного программного обеспечения, доступного сегодня. Это может быть предметом исследования.
Инструменты хранилища данных
На рынке доступно много инструментов для хранения данных. Вот некоторые из наиболее выдающихся:
1. MarkLogic:
MarkLogic — это полезное решение для работы с хранилищами данных, которое делает интеграцию данных проще и быстрее с использованием множества корпоративных функций. Этот инструмент помогает выполнять очень сложные поисковые операции. Он может запрашивать различные типы данных, такие как документы, отношения и метаданные.
https://developer.marklogic.com/products/
2. Оракул:
Oracle является лидирующей в отрасли базой данных. Он предлагает широкий выбор решений для хранилищ данных как локально, так и в облаке. Это помогает оптимизировать качество обслуживания клиентов за счет повышения операционной эффективности.
https://www.oracle.com/index.html
3. Amazon RedShift:
Amazon Redshift является инструментом хранилища данных. Это простой и экономичный инструмент для анализа всех типов данных с использованием стандартного SQL и существующих инструментов BI. Это также позволяет выполнять сложные запросы к петабайтам структурированных данных, используя технику оптимизации запросов.
https://aws.amazon.com/redshift/?nc2=h_m1
Вот полный список полезных инструментов Datawarehouse.
КЛЮЧ ОБУЧЕНИЯ
- Хранилище данных работает как центральное хранилище, где информация поступает из одного или нескольких источников данных.
- Три основных типа хранилищ данных — это хранилище корпоративных данных, операционное хранилище данных и Data Mart.
- Общее состояние хранилища данных: автономная рабочая база данных, автономное хранилище данных, хранилище данных в реальном времени и интегрированное хранилище данных.
- Четыре основных компонента Datawarehouse: менеджер нагрузки, менеджер хранилища, менеджер запросов, инструменты доступа для конечного пользователя
- Datawarehouse используется в различных отраслях, таких как авиалинии, банковское дело, здравоохранение, страхование, розничная торговля и т. Д.
- Внедрение Datawarehosue является стратегией, состоящей из трех частей: Стратегия предприятия, поэтапная доставка и итеративное прототипирование.
- Хранилище данных позволяет бизнес-пользователям быстро получать доступ к критически важным данным из некоторых источников в одном месте.
Главная /
Базы данных /
Хранилища данных
Хранилища данных — ответы на тесты Интуит
Правильные ответы выделены зелёным цветом.
Все ответы: Целью курса является изучение теоретических основ и принципов построения хранилищ данных, приобретение практических навыков аналитической обработки данных.
Для чего используется SQL Server Reporting Services?
(1) для составления сводных таблиц
(2) для визуализации кубов
(3) для составления отчетов
Перечислите характерные требования к хранению данных для принятия решений в хранилищах данных
(1) данные должны быть обобщены
(2) данные представляют значения на указанное время
(3) данные могут корректироваться
С точки зрения возможностей размерности могут быть
(1) регулярными
(2) из таблицы фактов
(3) нерегулярными
К полям OLE DB Connection Manager следует отнести
(1) имя пользователя
(2) конфигуратор базы данных
(3) путь к файлу с базой данных
Какие значения могут вводиться для создания KPIs?
(1) Value Expression
(2) Goal Expression
(3) Status expression
Из приведенных ниже записей выделите возможных провайдеров для куба:
(1) ODBC
(2) OLE DB
(3) Java
К основным этапам работы с хранилищами данных относят:
(1) этап извлечения и преобразования
(2) этап очистки данных
(3) этап загрузки
Если не управлять агрегированием в кубах данных, то оно выполняется по умолчанию, то есть свертка показателей производится
(1) с использованием функции суммирования снизу вверх
(2) с использованием функции суммирования сверху вниз
(3) с использованием функции умножения снизу вверх
Какие типы соединений из приведенных ниже могут быть созданы в Connection Managers?
(1) ADO.NET Connection
(2) C# Connection
(3) ASP Connection
Status expression это
(1) MDX-выражение, измеряющее текущий статус и управляющее графическими иконками отображения
(2) любое допустимое MDX-выражение, разрешаемое как цель для достижения выражением Value Expression
(3) MDX-выражение — текущий тренд относительно определенных значений
Какой вид отчета более соответствует MOLAP?
(1) табличный
(2) структурный
(3) матричный
Таблицы с денормализованной формой чаще всего имеют схему организации данных
(1) типа «звезда»
(2) линейного типа
(3) типа «шина»
Показатели в кубах данных могут быть
(1) аддитивными
(2) полуаддитивными
(3) неаддитивными
Какой элемент из пары SQL Server Destination-OLE DB Source является приемником данных?
(1) OLE DB Source
(2) OLE DB Destination
(3) ни один из приведенных элементов
Value Expression это
(1) показатель, либо выражение, созданное из показателя
(2) MDX-выражение, измеряющее текущий статус и управляющее графическими иконками отображения
(3) MDX-выражение — текущий тренд относительно определенных значений
К шаблонам создания нового приложения Crystal Analysis Professional следует отнести
(1) Blank Application
(2) Restore Development
(3) Sales Analysis Expert
В схеме «звезда» центральная таблица носит название
(1) таблица факта
(2) таблица аргумента
(3) материнская таблица
Аддитивные показатели
(1) агрегируются со всеми размерностями, включенными в группы показателей
(2) агрегируются относительно некоторых (не всех) размерностей
(3) не агрегируются по размерностям, но могут быть посчитаны для любой ячейки куба
Заполнение таблицы фактов производится
(1) на первом уровне
(2) на втором уровне
(3) на последнем уровне
Trend expression это
(1) MDX-выражение, отображающее текущий тренд относительно определенных значений
(2) MDX-выражение, измеряющее текущий статус и управляющее графическими иконками отображения
(3) любое допустимое MDX-выражение, разрешаемое как цель для достижения выражением Value Expression
Какие из приведенных ниже модулей присутствуют в Crystal Analysis Professional?
(1) дизайнер связей и коррекции
(2) полнофункциональный клиент
(3) модуль для Excel
Таблицы измерений содержат
(1) неизвестные данные
(2) редко изменяемые данные
(3) постоянно изменяемые данные
Полуаддитивные показатели
(1) агрегируются со всеми размерностями, включенными в группы показателей
(2) агрегируются относительно некоторых (не всех) размерностей
(3) не агрегируются по размерностям, но могут быть посчитаны для любой ячейки куба
Чтобы сфокусировать внимание пользователя на определенные элементы куба используется
(1) коннектор
(2) сериализация
(3) перспектива
Что называют целью?
(1) численное многомерное выражение или вычисление, которое возвращает целевое значение ключевого индикатора производительности
(2) численное многомерное выражение или вычисление, которое возвращает фактическое значение ключевого показателя производительности
(3) многомерное выражение, которое отражает состояние ключевого индикатора производительности в определенный момент времени
Из приведенных ниже записей выделите типы компонентов Crystal Analysis Professional:
(1) компоненты виртуализации
(2) компоненты визуализации
(3) компоненты навигации
Консольные таблицы могут быть связаны
(1) только таблицами связей
(2) только таблицами размерности
(3) только с таблицей факта
Неаддитивные показатели
(1) агрегируются со всеми размерностями, включенными в группы показателей
(2) агрегируются относительно некоторых (не всех) размерностей
(3) не агрегируются по размерностям, но могут быть посчитаны для любой ячейки куба
Из приведенных ниже записей выделите параметры, которые могут быть отображены или спрятаны в перспективе?
(1) размерности
(2) атрибуты
(3) показатели
Многомерное выражение, которое отражает состояние ключевого индикатора производительности в определенный момент времени, называется
(1) цель
(2) значение
(3) состояние
Для совместного группирования всех размерностей, не представленных ни в столбцах или строках, ни на осях графика, используется
(1) навигатор представлений
(2) навигатор срезов
(3) навигатор отображений
Куб OLAP — это
(1) структура, в которой хранятся совокупности данных, полученные путем всех возможных сочетаний измерений в таблице фактов
(2) структура, в которой хранятся совокупности данных, полученные путем всех возможных сочетаний измерений в консольной таблице
(3) таблица фактов
При сохранении кубов
(1) пространство на диске не выделяется под пустые ячейки
(2) выполняется сжатие данных
(3) несвязанные таблицы удаляются
KPIs — это
(1) тип свяязей данных
(2) ключевые индикаторы производительности
(3) валидатор соединения с кубом
Многомерное выражение, которое оценивает значение ключевого индикатора производительности с течением времени, носит название
(1) состояние
(2) тренд
(3) отражение
Каким образом может проводиться сортировка на рабочем листе Crystal Analysis Professional?
(1) по группам иерархий
(2) с возвратом данных
(3) при использовании временных файлов баз данных
Перечислите типы иерархий в измерениях
(1) сбалансированные
(2) несбалансированные
(3) неровные
К простым размерностям относятся
(1) размерности, состоящие из одной таблицы
(2) размерности, состоящие из нескольких таблиц
(3) размерности типа «родитель-потомок»
Мастер формирования схем игнорирует типы данных во всех вариантах, за исключением столбцов, в которых используется тип данных SQL Server
(1) varchar
(2) double
(3) native
Индикатор состояния это
(1) видимый элемент, благодаря которому можно быстро получить представление о состоянии ключевого индикатора производительности
(2) видимый элемент, благодаря которому можно быстро получить представление о состоянии любого элемента хранилища
(3) видимый элемент, благодаря которому можно быстро получить представление о состоянии таблицы факта
Какое построение данных реализуется с помощью MDX?
(1) таблица
(2) массив
(3) куб
Сбалансированные иерархии это
(1) иерархии, в которых число уровней может быть изменено, и каждая ветвь иерархического дерева может содержать объекты, принадлежащие не всем уровням, а только нескольким первым
(2) иерархии, в которых число уровней определено её структурой и неизменно, и каждая ветвь иерархического дерева содержит объекты каждого из уровней
(3) иерархии, в которых число уровней определено её структурой и постоянно, и некоторые ветви иерархического дерева могут не содержать объекты какого-либо уровня
Витриной данных называют
(1) срез хранилища данных, представляющий собой массив тематической, узконаправленной информации
(2) очень большая предметно-ориентированная информационная корпоративная база данных, специально разработанная и предназначенная для подготовки отчётов, анализа бизнес-процессов с целью поддержки принятия решений в организации
(3) база данных, основанная на реляционной модели данных
Какими инструментальными средствами можно строить OLAP срезы?
(1) только клиентскими
(2) только серверными
(3) как клиентскими, так и серверными
Как называется видимый элемент, благодаря которому можно быстро получить представление о тренде ключевого индикатора производительности
(1) индикатор уровня
(2) индикатор тренда
(3) индикатор отображения
Какое максимальное количество осей можно указать в одном запросе SELECT?
(1) до 128
(2) до 256
(3) до 512
Несбалансированные иерархии это
(1) иерархии, в которых число уровней может быть изменено, и каждая ветвь иерархического дерева может содержать объекты, принадлежащие не всем уровням, а только нескольким первым
(2) иерархии, в которых число уровней определено её структурой и неизменно, и каждая ветвь иерархического дерева содержит объекты каждого из уровней
(3) иерархии, в которых число уровней определено её структурой и постоянно, и некоторые ветви иерархического дерева могут не содержать объекты какого-либо уровня
Какой режим восстановления базы данных имеет максимальную производительность?
(1) простой
(2) неполный
(3) полный
К параметрам сводной таблицы следует отнести
(1) макет страницы
(2) число полей в столбце
(3) автосумму по строке
Как называется папка, в которой пользователь, просматривающий куб, увидит ключевой индикатор производительности?
(1) папка состояния
(2) папка отображения
(3) папка тренда
Запрос набора кортежей носит название
(1) контейнер
(2) множество
(3) модуль
Перечислите недостатки хранения данных в виртуальном хранилище
(1) время обработки запросов значительно превышает соответствующие показатели для физического хранилища
(2) практически невозможно получить данные за долгий период времени
(3) объем памяти, занимаемой на носителе информацией, значительно превышает соответствующий показатель для физического хранилища
ROLAP-куб нужно заполнять
(1) от перифирии к центру
(2) от центра к перефирии
(3) в произвольном порядке
Локальные кубы хранятся в файлах с расширением
(1) .dfts
(2) .cub
(3) .apo
Элемент текущего времени это
(1) многомерное выражение, которое возвращает элемент, идентифицирующий временный контекст ключевого индикатора
(2) численное многомерное выражение, которое назначает ключевому индикатору производительности значение относительной важности
(3) видимый элемент, благодаря которому можно быстро получить представление о тренде ключевого индикатора производительности
Может ли множество в MDX быть пустым?
(1) да, если оно является зарезервированным
(2) нет, не может
(3) да, может
Перечислите преимущества формата MOLAP
(1) превосходные свойства индексации
(2) высокая эффективность использования дискового пространства
(3) обеспечивает значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа по сравнению с другими форматами
(4) высокая производительность
Схема «снежинка» используется для
(1) нормализации схемы «звезда»
(2) денормализации схемы «звезда»
(3) увеличения избыточности данных в таблицах размерностей
Из приведенных ниже данных выделите опции сортировки MDA:
(1) Natural Sort
(2) Sort Order
(3) Reflexive Sort
Вес это
(1) многомерное выражение, которое возвращает элемент, идентифицирующий временный контекст ключевого индикатора
(2) численное многомерное выражение, которое назначает ключевому индикатору производительности значение относительной важности
(3) видимый элемент, благодаря которому можно быстро получить представление о тренде ключевого индикатора производительности
К полям Shared Data Source следует отнести
(1) Name
(2) Type
(3) Connection String
Укажите характерные требования к хранению данных для принятия решений в хранилищах данных
(1) данные не должны корректироваться
(2) данные представляют значения на указанное время
(3) данные не должны быть избыточными
Какими могут быть размерности по своим возможностям?
(1) регулярными
(2) ссылочными
(3) прямыми
Из приведенных ниже записей выделите элементы Data Flow Sources Microsoft Visual Studio:
(1) Excel Source
(2) Raw File Source
(3) Engine Source
Какие значения могут вводиться для создания KPIs?
(1) Status graphics
(2) Trend expression
(3) Status expression
К возможным типам отчетов следует отнести
(1) Tabular
(2) Edit Grid
(3) Martix
Какие из нижеперечисленных пунктов являются основными этапами работы с хранилищами данных?
(1) этап извлечения и преобразования
(2) этап загрузки
(3) этап деструкции
Если не управлять агрегированием в кубах данных, то свертка показателей производится
(1) с использованием функции вычитания
(2) с использованием функции суммирования
(3) с использованием функции умножения
При создании нового соединения OLE DB Connection необходимыми данными следует считать
(1) имя сервера
(2) пароль и логин администратора
(3) имя базы данных
MDX-выражение, измеряющее текущий статус и управляющее графическими иконками отображения называется
(1) Value Expression
(2) Goal Expression
(3) Status expression
Какой из приведенных видов отчета наиболее соответствует многомерным базам данных?
(1) блочный
(2) матричный
(3) строчный
Какую схему организации данных чаще всего имеют таблицы с денормализованной формой?
(1) схему типа «звезда»
(2) схему типа «таблица»
(3) схему типа «столбец»
Какими могут быть показатели в кубах данных?
(1) аддитивными
(2) субстрактивными
(3) интерполирующими
Ко вкладкам OLE DB Destination Editor следует отнести
(1) Mappings
(2) Restore Manager
(3) Error Output
Показатель, либо выражение, созданное из показателя называется
(1) Value Expression
(2) Goal Expression
(3) Status expression
Из приведенных ниже записей выделите типы серверов, используемые в Crystal Analysis Professional
(1) IBM DB2 OLAP Server
(2) RTL DB Server
(3) DFL Connection Server
Как называется центральная таблица в схеме «звезда»
(1) реляционная таблица
(2) таблица факта
(3) таблица размерности
Какие показатели агрегируются со всеми размерностями, включенными в группы показателей?
(1) аддитивные
(2) полуаддитивные
(3) неаддитивные
Из приведенных ниже записей выделите элементы листа ошибок:
(1) Warnings
(2) Connections
(3) Master Code
MDX-выражение, отображающее текущий тренд относительно определенных значений называется
(1) Trend expression
(2) Goal Expression
(3) Status expression
Для просмотра отчетов через интернет с помощью Crystal Enterprise в Crystal Analysis Professional используется
(1) нулевой клиент
(2) сетевой клиент
(3) полнофункциональный клиент
Таблицы измерений могут содержать
(1) поля, указывающие на «родителя» какого-либо члена в иерархической структуре данных
(2) описательные поля (например с именем члена измерения)
(3) ключевое поле для однозначной идентификации члена измерения
Какие показатели агрегируются относительно некоторых (не всех) размерностей?
(1) аддитивные
(2) полуаддитивные
(3) неаддитивные
Для каких из приведенных ниже действий предназначена перспектива?
(1) разграничение и декларирование доступа к кубу
(2) для ограничения доступа к кубу
(3) для обеспечения более простого доступа к отдельным элементам куба
Дайте определение термину «значение»
(1) численное многомерное выражение или вычисление, которое возвращает целевое значение ключевого индикатора производительности
(2) численное многомерное выражение или вычисление, которое возвращает фактическое значение ключевого показателя производительности
(3) многомерное выражение, которое отражает состояние ключевого индикатора производительности в определенный момент времени
К компонентам визуализации Crystal Analysis Professional следует отнести
(1) Worksheet
(2) Matrix
(3) Chart
Консольная таблица используется для
(1) нормализации данных в таблицах размерности
(2) денормализации данных в таблицах размерности
(3) нормализации данных в таблице факта
Какие показатели не агрегируются по размерностям, но могут быть посчитаны для любой ячейки куба?
(1) аддитивные
(2) полуаддитивные
(3) неаддитивные
Какие из приведенных ниже параметров могут быть отображены или спрятаны в перспективе?
(1) иерархии>
(2) компиляторы
(3) группы показателей
Многомерное выражение состояния должно возвращать нормализованное значение
(1) в диапазоне от -1 до 1
(2) -1, 0 или 1
(3) в диапазоне от 0 до 1
Для каких целей в Crystal Analysis Professional может использоваться объект Text?
(1) для добавления инструкций для пользователя
(2) для ведения статистики соединений
(3) для добавления пояснений к отображаемым данным
Что называют кубом OLAP?
(1) структуру, в которой хранятся совокупности данных, полученные путем всех возможных сочетаний измерений в таблице измерений
(2) структуру, в которой хранятся совокупности данных, полученные путем всех возможных сочетаний измерений в таблице фактов
(3) таблицу размерностей
Выполняется ли сжатие данных при сохранении кубов
Какие из приведенных ниже данных используются для создания KPIs?
(1) Trend graphics
(2) Goal Expression
(3) Value Expression
Тренд это
(1) многомерное выражение состояния, которое должно возвращать нормализованное значение
(2) многомерное выражение, которое оценивает значение ключевого индикатора производительности с течением времени
(3) многомерное выражение, которое отражает состояние ключевого индикатора производительности в определенный момент времени
Нулевой клиент Crystal Analysis Professional реализован с использованием
(1) DHTML
(2) PHP
(3) Java
Какие типы иерархий в измерениях вы знаете?
(1) сбалансированные
(2) симметричные
(3) неровные
К простым размерностям относятся
(1) сбалансированные размерности, состоящие из одной таблицы
(2) несбалансированные размерности, состоящие из одной таблицы
(3) размерности типа «родитель-потомок»
Реляционная база данных, поддерживающая объекты OLAP, называется базой данных
(1) расширенного контекста
(2) предметной области
(3) маркировки объектов
Как называют видимый элемент, благодаря которому можно быстро получить представление о состоянии ключевого индикатора производительности?
(1) индикатор отображения
(2) индикатор тренда
(3) индикатор состояния
Если в ходе запроса необходимо вернуть многомерное результирующее множество, то можно воспользоваться
Иерархии, в которых число уровней определено её структурой и неизменно, и каждая ветвь иерархического дерева содержит объекты каждого из уровней называют
(1) сбалансированными
(2) несбалансированными
(3) неровными
Срез хранилища данных, представляющий собой массив тематической, узконаправленной информации называют
(1) витриной данных
(2) профилем данных
(3) выборкой данных
Интерактивная таблица, применяемая для суммирования или статистического анализа большого количества исходных данных, являющихся результатом запроса к какой-либо базе данных, называется
(1) pivot table
(2) eject table
(3) markup table
Видимый элемент, благодаря которому можно быстро получить представление о тренде ключевого индикатора производительности, носит название
(1) индикатор тренда
(2) индикатор состояния
(3) папка отображения
Комбинация членов из одной или более размерностей, удобная для манипуляций в MDX, носит название
(1) связка
(2) кортеж
(3) терминал
Иерархии, в которых число уровней может быть изменено, и каждая ветвь иерархического дерева может содержать объекты, принадлежащие не всем уровням, а только нескольким первым, называют
(1) сбалансированными
(2) несбалансированными
(3) неровными
Какой режим восстановления базы данных имеет минимальную производительность?
(1) простой
(2) неполный
(3) полный
Данные, отображаемые в сводной таблице, хранятся
(1) в оперативной памяти
(2) в постоянной памяти
(3) на съемном носителе
Папка, в которой пользователь, просматривающий куб, увидит ключевой индикатор производительности, носит название
(1) папка производительности
(2) папка отображения
(3) ключевая папка
Синтаксически, множество можно определить через набор кортежей, перечислив их
(1) через запятую
(2) в фигурных скобках
(3) через двоеточие
Перечислите достоинства хранения данных в виртуальном хранилище
(1) время обработки запросов значительно меньше чем у физического хранилища
(2) очень легко получить данные за долгий период времени
(3) объем памяти, занимаемой на носителе информацией, значительно меньше чем соответствующий показатель для физического хранилища
(4) простота и удобство работы с текущими, детализированными данными
Хранилище нужно создавать
(1) от перифирии к центру
(2) от центра к перефирии
(3) в произвольном порядке
Списки Length и Color в панели Measures используются для выбора
(1) измерения
(2) отображения
(3) меры
Элементом текущего времени называют
(1) численное многомерное выражение, которое назначает ключевому индикатору производительности значение относительной важности
(2) многомерное выражение, которое оценивает значение ключевого индикатора производительности с течением времени
(3) многомерное выражение, которое возвращает элемент, идентифицирующий временный контекст ключевого индикатора
Указание фильтра в запросе MDX производится с помощью ключевого слова
(1) WHERE
(2) FIND
(3) LOCATE
Перечислите преимущества формата ROLAP
(1) более высокая производительность по сравнению с другими форматами
(2) размер хранилища не является критичным параметром
(3) обеспечивает значительно более высокий уровень защиты данных и хорошие возможности разграничения прав доступа
Какая схема позволяет уменьшить избыточность в таблицах размерностей
(1) схема «звезда»
(2) схема «снежинка»
(3) схема «дерево»
Какие предопределенные измерения входят в состав Microsoft Data Analyzer?
(1) Number of Children
(2) Change from Last Year
(3) Change from Previous Period
Весом называют
(1) численное многомерное выражение, которое назначает ключевому индикатору производительности значение относительной важности
(2) многомерное выражение, которое возвращает элемент, идентифицирующий временный контекст ключевого индикатора
(3) многомерное выражение состояния, которое возвращает нормализованное значение в диапазоне от -1 до 1
К параметрам подключения к источнику данных следует отнести
(1) Data Source
(2) Connection Status
(3) Server name
Какие из вариантов ответов являются характерными требованиями к хранению данных для принятия решений в хранилищах данных?
(1) данные ориентированы на приложения
(2) данные управляются транзакциями
(3) данные обобщены либо очищены
Укажите, какими могут быть размерности с точки зрения возможностей?
(1) регулярными
(2) ссылочными
(3) многие-ко-многим
Какие из приведенных ниже полей содержит OLE DB Source Editor?
(1) Outlook Control
(2) Connection Manager
(3) Error Output
Какие значения могут вводиться для создания KPIs?
(1) Value Expression
(2) Trend expression
(3) Trend graphics
К вариантам отображения макета отчета следует отнести
(1) Layout
(2) Markup
(3) Detail
Перечислите основные этапы работы с хранилищами данных
(1) этап очистки данных
(2) этап обновления
(3) этап нормализации
Если не управлять агрегированием в кубах данных, то свертка показателей производится
(1) сверху вниз
(2) снизу вверх
Назначение потоков данных осуществляется в секции
(1) Data Flow Embeded
(2) Data Flow Destinations
(3) Data Flow Compare
Как называется MDX-выражение, лежащее в диапазоне от -1 до +1, и принимающее дробные значения в зависимости от типа графического изображения, управляемого им?
(1) Value Expression
(2) Goal Expression
(3) Status expression
Тип отчета, наиболее соответствующий MOLAP и многомерным базам данных, носит название
(1) диагональный
(2) табличный
(3) матричный
Какую схему организации данных чаще всего имеют таблицы с денормализованной формой?
(1) схему типа «шина»
(2) схему типа «звезда»
(3) схему типа «дерево»
Показатели в кубах данных могут быть
(1) аддитивными
(2) неаддитивными
(3) косвенными
Какая вкладка OLE DB Destination Editor отвечает за проверку соответствия столбцов источника и приемника?
(1) Autodetect
(2) Mappings
(3) Verifications
Как называется любое допустимое MDX-выражение, разрешаемое как цель для достижения выражением Value Expression?
(1) Value Expression
(2) Goal Expression
(3) Status expression
Какие из приведенных ниже модулей включает в себя Crystal Analysis Professional?
(1) дизайнер аналитических приложений
(2) нулевой клиент
(3) блок потокового вывода
Таблица факта это
(1) вспомогательная таблица в схеме «звезда», присоединенная к таблице размерности
(2) таблица, соединенная с центральной таблицей схемы «звезда» радиальными связями
(3) центральная таблица в схеме «звезда»
Если выбор любого члена любой размерности приводит к пересчету агрегатов показателей, то такие показатели называются
(1) аддитивными
(2) полуаддитивными
(3) неаддитивными
Для каких из приведенных ниже целей может использоваться служба Integration Services?
(1) верификация и кодировка данных
(2) заполнение пустой реляционной витрины
(3) определение контекстной связности в хранилище данных
Состояние Status graphics переключается выходными значениями
(1) Value Expression
(2) Goal Expression
(3) Status expression
Для просмотра отчетов в корпоративной сети с помощью Crystal Enterprise в Crystal Analysis Professional используется
(1) структурный клент
(2) полнофункциональный клиент
(3) многосвязный клиент
Таблицы измерений содержат
(1) неизменяемые либо редко изменяемые данные
(2) только служебную информацию, необходимую для существования таблицы фактов
(3) постоянно изменяемые данные
Если показатели не пересекаются с некоторыми размерностями, то такие показатели называются
(1) аддитивными
(2) полуаддитивными
(3) неаддитивными
В качестве фильтра для визуализации объектов в куб добавляется
(1) маркер
(2) перспектива
(3) визуализатор
Численное многомерное выражение или вычисление, которое возвращает фактическое значение ключевого показателя производительности, называется
(1) цель
(2) значение
(3) состояние
Какие из приведенных ниже элементов служат компонентами навигации в Crystal Analysis Professional?
(1) проводник измерений
(2) навигатор срезов
(3) валидатор связей
При связи консольной таблицы с таблицами размерности
(1) консольная таблица в этой связи дочерняя, а таблица размерности — родительская
(2) консольная таблица в этой связи родительская, а таблица размерности — дочерняя
(3) устанавливаются равноправные двунаправленные связи, без разделения на «родитель — потомок»
Подсчитываемый показатель, возвращающий процент дохода, не может быть агрегирован из значений процентов своих дочерних ячеек других размерностей. Как называется такой показатель?
(1) аддитивный
(2) полуаддитивный
(3) неаддитивный
К элементам, которые могут отображаться или скрываться в перспективе, следует отнести
(1) мастер связей
(2) ключевые индикаторы
(3) подсчитываемые члены
Сколько значений может принимать состояние?
(1) Два крайних (-1 и 1) и одно промежуточное — 0
(2) Два крайних (-1 и 1)
(3) Неограниченное количество, при условии поддержки со стороны клиентского приложения
Из приведенных ниже записей выделите стандартные аналитические задачи Crystal Analysis Professional:
(1) отчет по ключевым показателям эффективности
(2) анализ лог-файлов web-сайтов
(3) отчет по коллизиям
Кубом OLAP называют
(1) структуру, в которой хранятся совокупности данных, полученные путем всех возможных сочетаний измерений в таблице фактов
(2) структуру, в которой хранятся совокупности данных, полученные путем всех возможных сочетаний измерений в таблице размерностей
(3) таблицу измерений
Выделяется ли место на диске под пустые ячейки при сохранении кубов
Максимальным значением Status expression KPIs является
Как называется многомерное выражение, которое оценивает значение ключевого индикатора производительности с течением времени
(1) значение
(2) индикатор состояния
(3) тренд
В чем состоят преимущества использования для нулевого клиента Crystal Analysis Professional DHTML?
(1) отсутствие необходимости установки апплетов
(2) отсутствие необходимости установки подключаемых приложений
(3) зависимость от элементов управления
Укажите существующие типы иерархий в измерениях
(1) сбалансированные
(2) несбалансированные
(3) неровные
(4) ровные
К простым размерностям относятся
(1) сбалансированные размерности, состоящие из нескольких таблиц
(2) несбалансированные размерности, состоящие из нескольких таблиц
(3) размерности типа «родитель-потомок»
При создании реляционных таблиц мастер игнорирует
(1) связанные измерения
(2) связанные группы мер
(3) серверные измерения времени
От чего зависит отображаемое значение индикатора состояния?
(1) от значения многомерного выражения, оценивающего тренд
(2) от значения многомерного выражения, которое оценивает состояние
(3) от значения одномерного выражения, которое оценивает состояние
Из приведенных ниже записей выделите ключевые слова синтаксиса языка MDX:
(1) SELECT
(2) WHERE
(3) SEND
Число уровней сбалансированной иерархии
(1) может быть изменено
(2) неизменно
Витрина данных это
(1) хранилище данных, состоящее из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию
(2) хранилище данных, в котором данные оформлены в виде моделей объектов, включающих прикладные программы, которые управляются внешними событиями
(3) срез хранилища данных, представляющий собой массив тематической, узконаправленной информации
Ячейки сводной таблицы представляют собой
(1) ссылки на поля исходной таблицы
(2) суммы значений одного из числовых полей исходной таблицы
(3) комлексные запросы из исходной таблицы
Индикатор тренда это
(1) видимый элемент, благодаря которому можно быстро получить представление о тренде ключевого индикатора производительности
(2) видимый элемент, благодаря которому можно быстро получить представление о состоянии ключевого индикатора производительности
(3) многомерное выражение, которое оценивает значение ключевого индикатора производительности с течением времени
Для составления кортежа, содержащего члены более чем одной размерности, необходимо все члены поместить
(1) в квадратные скобки
(2) в круглые скобки
(3) в фигурные скобки
Число уровней несбалансированной иерархии
(1) может быть изменено
(2) неизменно
В каком режиме восстановления базы данных журнал транзакций автоматически очищается?
(1) простой
(2) неполный
(3) полный
Из приведенных ниже записей выделите дополнительные параметры поля сводной таблицы:
(1) параметры сортировки
(2) параметры автозаполнения
(3) отображение лучшей десятки
Папка отображения это
(1) папка, в которой пользователь, просматривающий куб, увидит ключевой индикатор производительности
(2) папка, в которой пользователь, просматривающий куб, может быстро получить представление о тренде индикатора производительности
(3) папка, в которой пользователь, просматривающий куб, может быстро получить представление о состоянии таблицы факта
Имя в MDX необходимо заключать в квадратные скобки, если оно
(1) содержит пробел
(2) совпадает с ключевым словом
(3) начинается с цифры
Выделите тезисы, характерные для хранения данных в виртуальном хранилище
(1) время обработки запросов значительно превышает соответствующие показатели для физического хранилища
(2) практически невозможно получить данные за долгий период времени
(3) объем памяти, занимаемой на носителе информацией, значительно меньше чем соответствующий показатель для физического хранилища
В каком порядке нужно заполнять ROLAP-куб
(1) от центра к перефирии
(2) от перифирии к центру
(3) в произвольном порядке
MDX — это
(1) тип данных Excel
(2) многомерный запрос
(3) сводная таблица
Как называют многомерное выражение, которое возвращает элемент, идентифицирующий временный контекст ключевого индикатора?
(1) элемент текущего времени
(2) тренд времени
(3) объем времени
Выделите из приведенных ниже имен те, которые необходимо заключать в квадратные скобки:
(1) 011SSD
(2) WHERE
(3) more
Перечислите преимущества формата HOLAP
(1) обеспечение возможности связи с огромными наборами данных в реляционных таблицах
(2) прирост производительности за счет использования многомерных хранилищ
(3) количество проводимых преобразований между ROLAP и MOLAP системами не влияет на общую эффективность
Какая из схем позволяет более быстро выполнять запросы о структуре размерностей?
(1) схема «звезда»
(2) схема «снежинка»
(3) схема «дерево»
Для каких из приведенных ниже целей в Microsoft Data Analyzer используется язык XML?
(1) для хранения файлов
(2) для хранения отображений
(3) для хранения вычисляемых измерений
Как называют численное многомерное выражение, которое назначает ключевому индикатору производительности значение относительной важности?
(1) вес
(2) тренд
(3) объем
оглавление
Глава 2 Хранилище данных
Глава 3 Предварительная обработка данных
Глава 4 Характеристика и дифференциация
Сбор данных
Глава V Правила ассоциации майнинга
Глава 6 Классификация горного дела
Глава VII Кластерная добыча
Глава 2 Хранилище данных
1. Индекс B-дерева
Вопрос: Почему технология индексирования, широко используемая в базе данных, такая как B-дерево, не может быть непосредственно внедрена в хранилище данных?
1. B-дерево требует, чтобы атрибуты имели много разных значений, например, поле значений, такое как идентификационный номер, имеет широкий диапазон значений, и дублирование почти отсутствует.
2. B-дерево требует, чтобы запрос имел более простые условия и меньше результатов
3. Пространственно-временная сложность создания B-деревьев очень велика
![[ , , (img-zBpY3W0H-1574591500400)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124094608731.png)]](https://russianblogs.com/images/854/b1e50ccc450931a4e0aa3b7590de5596.png)
2. Индекс BitMap
Существует два типа растровых индексов: простой растровый индекс и кодированный растровый индекс, который позволит вам нарисовать простой растровый индекс во время экзамена.
(1) Простой растровый индекс
Для каждого атрибута генерируйте разные битовые векторы из разных значений в атрибуте! Есть несколько разных битовых векторов для нескольких разных значений. Если значение атрибута кортежа в таблице данных равно v, соответствующая строка в индексе битовой карты указывает, что бит значения равен 1, а другие биты строки равны 0.
Например:
![[ , , (img-kDnJPqxl-1574591500402)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124093405039.png)]](https://russianblogs.com/images/800/10d70f568ca790635e125cde50f7e998.png)
Если мы хотим найти женщину, которая купила продукт b, сначала выньте продукт b и женский вектор F для расчета и операции.
b:0 0 1 1 1 0 0 0
F:1 0 1 1 0 1 0 0
0 0 1 1 0 0 0 0
Обнаружено, что третья и четвертая цифры равны 1, что указывает на то, что третья и четвертая строки данных являются результатами, которые мы хотим
Индекс растрового изображения подходит для столбцов с несколькими фиксированными значениями, такими как пол, семейное положение, административный регион и т. Д. Для пола диапазон значений, который можно принять, составляет только «мужской», «женский», а мужчины и женщины могут обозначать 50 % Данных, в это время добавление индекса B-дерева все еще должно извлечь половину данных, поэтому это совершенно не нужно. Если диапазон значений определенного поля очень широк, дублирования почти нет, например, номер ID, он не подходит для индекса растрового изображения, подходит для индекса B-дерева.
3. Присоединиться к указателю
Подходит для сложных запросов! Сложные запросы часто требуютМногостоловое соединениеИспользование индексов соединения может улучшить производительность. Как нарисовать индекс связи во время экзамена?
Позвольте мне поговорить о том, что такое таблица фактов и таблица измерений. Таблица фактов — это то, на чем вы хотите сосредоточиться, например различные данные о продажах, обычно содержит большое количество строк. Таблица измерений — это угол, под которым вы наблюдаете предмет. С какого угла вы просматриваете контент? Например, для данных о продажах вы можете посмотреть на определенный регион, а регион — это измерение.
Например, в звездообразной схеме связь между таблицей фактов Sales и таблицами измерений Customer и Item показана на рисунке.
![[ , , (img-D062oS99-1574591500402)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124095537302.png)]](https://russianblogs.com/images/217/d491ca773442eca3711730a0ab902bb9.png)
Их таблица индексов ссылок показана на рисунке.
![[ , , (img-Uwcq761b-1574591500403)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124095554686.png)]](https://russianblogs.com/images/528/23887b27fdae80da9ea7a5c6bd194178.png)
4. Стратегия хранения хранилища данных
Основываясь на дизайне логической модели, определите структуру хранения данных, стратегию индекса, расположение хранилища и место хранения данных, а также другое физическое содержимое, которое примерно похоже на проект базы данных.
Общие методы
- Таблица слияния
Операция соединения таблицы занимает много времени, а таблица объединяется и сохраняется для экономии времени соединения. Это стратегия пространства времени - Последовательность данных
Непрерывное использование данных постоянно сохраняется, и исходная логическая часть может продолжать существовать - Ввести избыточность
Это относится конкретно к процессу распространения атрибута из одной таблицы в другие таблицы. В этом процессе избыточность может сохранить количество подключений доступа - Физический раздел таблицы
Подобно сегментации данных на этапе разработки логики, разделенная таблица используется для выражения таблицы в исходном логическом смысле. - Генерация данных экспорта
Если к статистическим данным таблицы часто обращаются, эту часть агрегированных данных можно записать отдельно - Создать широкий индекс
Запишите статистические результаты, относящиеся к «большинству». Эта часть данных очень мала, и ее можно установить непосредственно на этапе обновления данных. При выполнении таких запросов вы можете преобразовать статистические операции в простой поискТак что нет индекса B-дерева!
5. Хранилище данных
(1) Появление хранилища данных?
Построение хранилища данныхНеДля замены традиционной системы обработки транзакций и базы данных, но для адаптации к потребностям аналитической обработки в новых областях. Хранилище данных становится одним из основных средств интеграции информации.
Его цель:
- Улучшить производительность обеих систем
- Улучшение транзакционной пропускной способности операционных баз данных.
- Структура данных, содержание и использование в двух системах могут быть разными
(2) Особенности / особенности хранилища данных
-
Предмет-ориентированной
Тема — это объект анализа, относящийся к определенной области деятельности предприятия. Тематическая ориентация означает, что информация в хранилище данных организована в соответствии с темой. Тема извлечена
-
интегрированный
Все данные размещены в одном месте, чтобы сформировать полную и согласованную сводку данных
-
Нелетучий
Данные в хранилище данных изолированы от рабочей среды данных.
-
Изменяющегося во времени
Хранилище данных является резервной копией только для чтения в любое время, а хранилище данных обновляется через определенные промежутки времени.
6、OLAP
OLAP — это оперативный анализ и обработка, благодаря специальному механизму интеграции данных и дополненному более интуитивно понятному интерфейсу доступа к данным, он может в кратчайшие сроки отвечать на сложные запросы специалистов, не занимающихся обработкой данных.
(1) характеристики OLAP
- OLAP — это онлайн-доступ к данным и их анализ для конкретных проблем
OLAP — инструмент только для чтения, который сильно отличается от SQL - Быстрый, стабильный, последовательный и интерактивный доступ к множеству возможных форм наблюдения за информацией
Несколько «измерений» - Позволяет лицам, принимающим решения, детально наблюдать за данными
Ориентированный на людей
(2) Основная модель данных OLAP
-
MOLAP
Многомерная база данных -
ROLAP
Используйте двумерную модель таблицы фактов для хранения значений метрики и определения большого количества внешних ключевых слов для указания на измерение
- Звездная модель
- Снежинка модель
Подробное введение в ROLAP
-
Звездный режим
- В n-мерной многомерной таблице есть таблица фактов и таблицы n измерений. Если добавляется новое измерение, добавляется таблица измерений, которую легко расширить.
- При работе с многомерными запросами полагайтесь на стандартный SQL для выполнения таблицы фактов и таблицы измерений.соединениепротивсобирать
- Преимущество звездной модели заключается в том, что после определения архитектуры существует несколько макро-факторов, которые влияют на архитектуру.В основном фиксированный способоптимизируют
-
Снежинка модель
- Расширение звездного режима
Некоторые таблицы измерений не являются единой плоской структурой, статус всех атрибутов измерений не равен - Преимущества
- Более приспособлен к человеческому пониманию и наблюдению
Внутренняя релевантность отражена в таблице подразмер - Стандартизированные тенденции дизайна экономят место для хранения
- Более приспособлен к человеческому пониманию и наблюдению
- Недостатки
- Структура намного сложнее, чем звездный рисунок
- Дополнительные множественные соединения вызывают потерю производительности
- Даже если размеры одинаковы, структура таблицы может сильно отличаться
сложно оптимизировать
- Расширение звездного режима
-
Другие режимы расширения
- Созвездие
Соедините несколько звездочек с помощью общего измерения - Режим метели
Соедините несколько моделей снежинок через общие измерения
- Созвездие
7. Куб данных
Куб данных — это многомерная модель данных, которая в основном включает режим звезды, режим снежинки и режим группировки фактов.
-
Звездный узор
Это наиболее распространенный шаблон. Он включает в себя большую центральную таблицу (таблицу фактов), которая содержит большой объем данных, но не является избыточной; набор небольших вспомогательных таблиц (таблиц измерений), каждая из которых Одно измерение. Как показано ниже, данные просматриваются из четырех элементов измерения, времени, ветви и местоположения.Центральная таблица — это таблица фактов продаж, которая содержит идентификаторы (сгенерированные системой) и три метрики четырех таблиц измерений. Каждое измерение представлено таблицей, а атрибуты в таблице могут образовывать иерархию или сетку.
![[ , , (img-oUj8mfPu-1574591500404)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191123211435930.png)]](data:image/svg+xml,%3Csvg%20xmlns='http://www.w3.org/2000/svg'%20viewBox='0%200%200%200'%3E%3C/svg%3E)
-
Снежинка
Это вариант режима «звезда», который нормализует некоторые таблицы и дополнительно разбивает данные на дополнительные таблицы в форме снежинок. -
Факт Созвездие
Разрешение нескольким таблицам фактов совместно использовать таблицы измерений можно рассматривать как набор шаблонов звездочек. Как показано ниже, две таблицы фактов «Продажи» и «Доставка» совместно используют три таблицы измерений: время, позиция и местоположение.
![[ , , (img-oUj8mfPu-1574591500404)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191123211435930.png)]](https://russianblogs.com/images/108/3c67865e840699ae8fdf33cb873e67fc.png)

![[ , , (img-I240VC9w-1574591500405)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191123211554679.png)]](https://russianblogs.com/images/666/2302d6728860c36126f5f6e8ddb4c94a.png)
Используйте фактический шаблон созвездия в хранилище данных, поскольку он может моделировать несколько связанных тем: шаблон «звезда» или «снежинка» популярен в витринах данных
8. Многомерные методы анализа данных
- ломтик
Только уменьшение данных, относящихся к элементам измерения, приводит к уменьшению размерности.
- Разрезать на кусочки
Это можно рассматривать как составную операцию среза, размерность не может быть уменьшена, но объем данных уменьшен
- Вращение
Поменяйте порядок размеров, чтобы получить новый способ представления. Операции с многомерным вращением будут полезны, меняя фокус определенных размеров
- Сверлить на
Поднимите набор данных нижнего уровня на более высокий уровень, и бурение не изменит основную часть наблюдения
- Сверлить
Обратная операция детализации снижает уровень данных. Развертка и детализация не могут продолжаться бесконечно. Нижняя граница — атомный слой.
- Другие операции
- Кросс-дрель
Одновременная детализация нескольких многомерных моделей для упрощения сравнения нескольких фактов
- Кросс-дрель
- Развернуть
- После детализации до минимальной детализации куба данных продолжите уточнение до реляционной таблицы хранилища / базы данных.
- Может найти некоторые ошибки
9. Проектирование хранилища данных
См ppt
Глава 3 Предварительная обработка данных
1. Процесс предварительной обработки данных
-
Очистка данных
- Отсутствующие значения, шум, несогласованность
-
Интеграция данных
- Интеграция шаблонов, избыточность обнаружения, обнаружение и обработка конфликта значений данных
-
Преобразование данных
- Гладкость, агрегация, обобщение, нормализация, построение атрибутов
-
Протокол данных
- Агрегация кубов данных, выбор подмножеств атрибутов, уменьшение размеров, сокращение чисел, дискретизация и генерация концептуальной иерархии
-
Дискретизация данных
-
Числовые данные
- Биннинг, гистограмма, кластеризация, дискретизация на основе энтропии, дискретизация на основе интуитивного разделения
-
Категориальные данные
- Пользователь или эксперт показывает на уровне модели, что атрибут частично упорядочен, уровень высокий, а число значений атрибута меньше
-
2. Очистка данных
** Шумные данные: ** Случайные ошибки или различия в измерении переменных, которые могут быть вызваны неверными значениями атрибутов (проблемы с инструментом сбора данных, проблемы ввода или передачи данных и т. Д.) И неполными, непоследовательными или дублирующимися записями. из
** Метод обработки данных шума: ** Биннинг / группирование, кластеризация, ручная проверка, регрессия
Простой метод дискретизации: биннинг
- Ширина эквипа
- Разделите диапазон на N интервалов одинакового размера
- Ширина интервала будет: W = (B-A) / N (самое высокое значение атрибута — самое низкое значение) / N интервалов
- Глубина снаряжения
- Разделенный на N интервалов, каждый интервал имеет одинаковое количество выборок
** После объединения необходимо сгладить данные, включая сглаживание по среднему значению блока, сглаживание по среднему значению блока и сглаживание по границе блока **
![[ , , (img-FcduVBrn-1574591500406)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124102906288.png)]](https://russianblogs.com/images/568/34175bab83b1dd0943d4e89c83a51ef0.png)
3. Интеграция и преобразование данных
Интеграция данных в основном говорит об устранении избыточности, здесь в основном зависит от способа преобразования данных
(1) преобразование данных
- Гладкая
- Устранить шумовые данные
- Агрегат
- Сводные данные
- Обобщить
- Восхождение на концептуальный уровень — это концептуализация
- Нормализации
- Увеличить данные до указанного диапазона
- Построение атрибута / функции
(2) Три способа нормализации
-
min-max normalization
значение ’= (значение-минимальное значение) / (максимальное-минимальное значение)
-
Z-score normalization
Стандартизация Z также называется стандартизацией стандартного отклонения. Этот метод дает среднее значение и стандартное отклонение исходных данных для стандартизации данных.
-
normalization by decimal scaling
Нормализованное масштабирование. Этот метод нормализует путем перемещения положения десятичной точки данных. Сколько движется десятичных знаков зависит от значения атрибута AМаксимальное абсолютное значение, В формуле j — наименьшее целое число, которое удовлетворяет условию.
Например, предположим, что значение A составляет от -986 до 917, а максимальное абсолютное значение A составляет 986. Для стандартизации с использованием десятичного масштабирования мы делим каждое значение на 1000 (т. е. j = 3 ), таким образом, -986 нормализуется до -0,986.
![[ , , (img-Vi1sK25r-1574591500406)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124103611814.png)]](https://russianblogs.com/images/209/6c77a3baf2c5eac12b584661d9e0f071.png)
![[ , , (img-wzkvQEqk-1574591500407)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124104152934.png)]](https://russianblogs.com/images/977/b8f64058fe1b7917ebbf3c725b658901.png)
![[ , , (img-IVOzOyfB-1574591500407)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124104214152.png)]](https://russianblogs.com/images/380/949f4f3509e3f3c4daafaaedc57b7d4c.png)
![[ , , (img-pzircjkJ-1574591500408)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124104322607.png)]](https://russianblogs.com/images/558/31cf7f7d7dcb5afd8ea7e4d67a22d676.png)
![[ , , (img-B4aDW0iI-1574591500408)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124104405001.png)]](https://russianblogs.com/images/206/37d5119c12eb4a96da73db545cb2b1e6.png)
![[ , , (img-kIiLKMxO-1574591500408)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124104635493.png)]](https://russianblogs.com/images/492/2e0aa98d8c2fd9526f98041f0311fc8c.png)
4. Спецификация данных
Сокращение данных, то есть протокол данных, 4 стратегии, упомянутые в PPT
- Агрегация куба данных
- Уменьшение размерности
- Numerosity reduction
- Дискретизация и генерация концептуальной иерархии
Соблюдайте контрольные работы прошлых летдискретизация

maxdiff: Сортировка данных в первую очередь. Для заданных β-сегментов или пакетов максимальная разница между соседними данными составляет β-1. Если максимальная разница превышена, ее нельзя поместить в сегмент.
пример:

Существует сомнение, почему минимальная дисперсия рассчитывается для каждой группы x2?
Другие методы дискретизации
-
Основанная на энтропии дискретизация
Для заданного набора выборок S, если граница T используется для разделения S на два интервала S1 и S2, энтропия после деления равна
В качестве двоичной дискретизации выбирается граница, минимизирующая энтропийную функцию на всех возможных границах. Этот процесс применяет рекурсию к полученным разделам, пока не будут выполнены определенные условия остановки.
-
3-4-5 правил
Правило 3-4-5 может использоваться для сегментирования цифровых данных на относительно однородные «естественные» интервалы.
https://blog.csdn.net/weixin_42859280/article/details/93306099 Посмотрите этот блог!
- Если наиболее значимая цифра интервала охватывает 3, 6, 7 или 9 различных значений, разделите диапазон на 3 интервала одинаковой ширины.
- Если его старший значащий бит охватывает 2, 4 или 8 различных значений, разделите диапазон на 4 интервала.
- Если его самый старший бит охватывает 1, 5 или 10 различных значений, разделите диапазон на 5 интервалов


Глава 4 Характеристика и дифференциация
ерунда
Сбор данных
1. Интеллектуальный анализ данных
(1) Что такое интеллектуальный анализ данных?
Интеллектуальный анализ данных = обнаружение знаний в базе данных, анализ большого количества полных данных, обобщение законов и получение знаний для управления объективным миром.
(2) Основные понятия интеллектуального анализа данных
- Режим
- Любая информация, которая выражает определенное логическое значение на языке высокого уровня, является шаблоном (информация + суждение)
- Знание
- Удовлетворять требования пользователей в отношении объективных стандартов оценки (поддержка / доверие …) и стандартов субъективной оценкиРежим
- Доверие к доверию
- Степень, в которой шаблон устанавливается на определенном наборе данных, напримерСреди клиентов, которые покупают хлеб с маслом, большинство людей также покупают молокоУровень достоверности этой модели: количество покупателей, покупающих хлеб, масло и молоко одновременно, в процентах от количества покупателей, покупающих хлеб и масло одновременно.
- Доверие не фиксируется
- Без достаточной уверенности модель нельзя назвать знанием
- Поддержка
- На определенном наборе данных степень внимания модели к пользователю также называетсяИнтерес
- Нетривиальный
- Обычные знания не являются целью добычи данныхПотому что такие знания стализдравый смысл, Что мы ищем, это экстраординарные знания
(3) Какова связь между интеллектуальным анализом данных и хранилищем данных?
- Изначально интеллектуальный анализ данных базировался на базе данных.
- После создания технологии хранилища данных
Поскольку данные в хранилище данных представляют собой комплексные данные после извлечения, сортировки и предварительной обработки, анализ данных можно запустить непосредственно в хранилище данных, и задача будет относительно простой.Но это не означает, что интеллектуальный анализ данных можно легко настроить в хранилище данных.
(4) Этапы добычи данных
-
Интеграция данных
-
Что делать, если нет данных? Обычно интегрируется в хранилище данных
-
Предварительная обработка данных в хранилище данных
- Очистить, интегрировать, преобразовать, уменьшить
-
-
Протокол данных
-
Объем данных, используемых для интеллектуального анализа данных, очень велик, и сокращение объема данных может сократить объем данных и повысить производительность операций интеллектуального анализа данных.
-
Общие методы сокращения данных
- Вычисления куба данных
- Выбор области майнинга
- Исходя из предположения, что это не влияет на результаты майнинга, попытайтесь выбрать как можно больше наборов атрибутов, связанных с операцией майнинга, и удалить явно не связанные факторы или из-за правил, обычаев и т. Д., Даже если соответствующие результаты анализа не могут быть применены
- Выбор временных рамок или содержимого резервной копии
- Сжатие данных
Сократите размер данных, сэкономьте накладные расходы на пространство хранения и накладные расходы на передачу данных, если используемый алгоритм анализа данных может напрямую извлекать сжатые данные без декомпрессии, технология сжатия данных будет очень полезна - дискретизация
Разделите непрерывную область значения атрибута на несколько областей и замените исходное значение идентификатором каждой области, чтобы уменьшить количество значений атрибута в атрибуте. Вы также можете использовать эти данные Технология протокола для автоматического построения концептуального иерархического дерева этого атрибута
-
-
Копать землю
- Метод добычи
- Правило ассоциации майнинг-глава 5
- Классификация горного дела — глава 6
- Кластерный майнинг — Глава 7
- Метод добычи
-
Экспресс
- Может включать текст, графику, таблицы, значки и другие визуальные формы
Глава 5: Правила ассоциации майнинга
1. Правила ассоциации
Информация https://www.jianshu.com/p/7d459ace31ab
-
Правила ассоциации используются для указания степени ассоциации между многими атрибутами в базе данных транзакций.
-
Анализ правил ассоциации заключается в использовании большого количества данных в базе данных для передачиАлгоритм ассоциацииПоискАтрибутыкорреляция
-
Атрибут называется здесьпункт
Набор атрибутов, состоящий из нескольких атрибутов, называетсянаборов
Пример: супермаркет
90% клиентов, которые приобретают товары A, будут покупать товары B одновременно, тогда правила ассоциации могут быть выражены как:
R1: A-> B означает правило -
Поддержка A-> B и B-> A одинакова, но уверенность обычно отличается
-
Любая комбинация может составлять правила ассоциации
Чтобы обнаружить значимые правила ассоциации, необходимо указать два порога:
Минимальная поддержка с участием Минимальная уверенность
- Правило, которое удовлетворяет минимальной уверенности и минимальной поддержкеСильные правила, В противном случаеСлабое правило
- Суть майнинга правил ассоциацииНайти строгие правила в базе данных (хранилище данных)
Служба поддержки
![[ , , (img-ldbmooAh-1574591500410)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124114039336.png)]](https://russianblogs.com/images/356/32a7a6fc645a6832904b5dfc70b27614.png)
уверенность

2. Априорный алгоритм
https://www.cnblogs.com/en-heng/p/5719101.html
(1) Основные понятия
- пункт
Значения атрибутов, появляющиеся в базе данных, каждое значение атрибута составляет элемент - наборов
Коллекция значений атрибутов, которые появляются в базе данных - набор k-элементов
набор элементов, состоящий из k элементов - Частые наборы элементов
- Частота появления элемента в базе данных соответствует минимальным требованиям поддержки, указанным пользователем.
- которыйКоличество записей, которые также содержат все значения атрибутов в наборе элементов Начать % От всех записей Больше или равно минимальной поддержке, указанной пользователем
- Правила связывания должны быть сгенерированы в частых наборах элементов, соответствующих минимальным требованиям поддержки пользователя
- Процесс майнинга ассоциативных правил — это процесс поиска частых наборов элементов в базе данных.
- В процессе поиска часто встречающихся предметов следуйтеЛюбое подмножество каждого частого набора элементов также является частым набором элементов
(2) метод поиска частых наборов предметов
- Найти частые наборы товаров первого порядка C1
Удалите редкие наборы элементов и получите L1- Генерировать надмножество второго порядка из L1, а именно набор возможных кандидатов C2
Удалите редкие наборы элементов и получите L2- Генерация суперсета третьего порядка C3 из L2
удаляет надмножества высшего порядка, которые не нужно временно рассматривать
Удалите редкие наборы элементов и получите L3- ……
Последний частый набор предметовСоюз L1, L2, L3 …
Алгоритм априори: перед выполнением алгоритма пользователь должен предоставить минимальную поддержку и минимальную достоверность. Генерация правил ассоциации обычно делится на следующие два этапа:
-
Используйте минимальную поддержку, чтобы найти частые наборы элементов из базы данных.
Для базы данных D процесс поиска часто встречающихся наборов показан ниже.
Сначала ищите набор частых элементов первого порядка C1. В C1 поддержка {1} составляет 2/4 = 0,5 (всего четыре вещи в базе данных D, {1} появляется в двух из них), остальные в C1 Некоторые из них также рассчитываются таким образом, предполагая, что заданная минимальная поддержка SUP_min = 0,5, {4} исключается и получается L1.
Затем генерируют надмножество второго порядка из L1, то есть набор вероятных элементов C2, и удаляют набор нечастых элементов (то есть менее SUP_min = 0,5), чтобы получить L2.
Сгенерируйте надмножество C3 третьего порядка из L2, удалите надмножество высшего порядка, которое не нужно рассматривать временно, и удалите нечастый набор предметов, чтобы получить L3
Мы можем видеть, что количество элементов в наборе предметов увеличилось с 1 до 3. И каждый рост генерируется с использованием элементов, которые встречают поддержку в предыдущем наборе элементов, этот процесс называетсяНабор кандидатов
-
Используйте минимальное доверие, чтобы найти правила ассоциации из частых наборов предметов. (3) Среднее содержание
Также предположим, что минимальная достоверность равна 0,5, из часто встречающегося набора элементов {2 3 5} мы можем обнаружить, что правило {2 3} ⇒ {5} имеет достоверность 1> 0,5, поэтому мы можем сказать, что {2 3} ⇒ {5 } Это правило, которое может представлять интерес. (Если вы не понимаете этого здесь, посмотрите на формулу доверия выше.)

Как найти все частые наборы предметов?
Набор данных, содержащий N элементов, имеет 2 ^ N-1 различных наборов элементов, например, все наборы элементов, содержащие 4 элемента:

(3) Создать правила ассоциации
Это определяет алгоритм генерации правил ассоциации: (входные параметры: набор данных и набор частых элементов)
Два правила могут быть построены для частых наборов элементов {A, C}
R1:A->C R2:C->AЧастые наборы первого порядка не могут создавать правила ассоциации, только обычные знания
Разделите каждый частый набор на левую и правую части, которые доступны для всехПротестируйте эти правила (рассчитайте достоверность по очереди, а используемые данные поддержки будут сохранены при создании частых наборов элементов)
Фильтровать правила сопоставления по заданным порогам
Объедините все оставшиеся правила из первого списка, чтобы создать второй список правил, где правая часть правила содержит два элемента
Проверьте правила во втором списке
Процесс повторяется до тех пор, пока N (или новые правила не могут быть созданы)
Наконец, оставшиеся правила ассоциации поднимаются до знаний, которые используются для поддержки принятия решений
Например, приведенный выше пример {2,3,5} можно разделить на {2} -> {3,5} и {2,3} -> {5}, а затем рассчитать достоверность, которая равна
Доверие con (X–> Y) = (X U Y) / X. Вот трюк
Предположим, что минимальная достоверность равна p, а правило 0,1,23 не соответствует требованию минимальной достоверности, то есть P (0,1,2,3) / P (0,1,2) <p
Тогда любое правило с подмножеством {0,1,2} слева не будет соответствовать требованию минимальной достоверности
(5) Метод оптимизации алгоритма Apriori
Поскольку алгоритм тратит время на многократное сканирование базы данных, основными методами оптимизации являются:
-
Метод разбиения базы данных
Оптимизировано для аппаратных ограничений
Хотя показатели доверия и поддержки могут измениться, но
Все правила ассоциации должны появляться в каждом подразделении
Разделение может привести к тому, что количество сгенерированных правил ассоциации будет слишком большим, и повышение порога приведет к потере первоначальных правил.
- Каждая часть может быть отсканирована в памяти
- Наконец, объедините все полученные частые наборы
-
Использование метода Hash для фильтрации 2 частых наборов элементов
Хэшируйте каждый элемент в хеш-таблицу, фильтруя тем самым большое количество ненужных наборов кандидатов. -
Используйте набор данных выборки, чтобы получить возможные правила, а затем используйте оставшиеся данные в базе данных, чтобы проверить правильность этих правил.
Этот метод может быть ненадежным, поскольку он не может гарантировать правильность заключения -
Уменьшите количество записей, обрабатываемых за сканирование
Если запись не содержит частые наборы элементов длины k, то эта запись не может содержать частые наборы элементов длины (k + 1)После получения всех частых наборов элементов k-порядка при каждом последующем сканировании не требуется доступ к вышеуказанным записям, что постепенно уменьшает количество проверенных записей.
3. FP-Growth алгоритм
####(1. Введение
** Ядро FP: ** Используйте дерево FP для рекурсивного роста часто встречающихся путей паттернов (разделяй и властвуй)
** Преимущество FP: ** Удалена ненужная информация; Соединение с исходящим узлом и размер счета меньше, чем в исходной базе данных; Быстро; Преобразование проблемы поиска длинных частых шаблонов в рекурсивный поиск некоторых более коротких шаблонов.
Алгоритм анализа ассоциации, который принимает следующую стратегию «разделяй и властвуй»: Сжатие базы данных, предоставляющей частые наборы элементов, в дерево частых шаблонов (FP-Tree), но сохраняющее информацию об ассоциации наборов элементов; наибольшее различие между этим алгоритмом и алгоритмом Apriori состоит в двух точках :первый,Найти частые наборы предметов без генерации кандидатов Во-вторых, нужно только дважды обойти базу данных, что значительно повысит эффективность. Но алгоритм FP-Growth можно использовать только для поиска часто встречающихся наборов элементов, а не правил ассоциации.
(2) Алгоритм псевдокода
Смотрите: http://blog.csdn.net/sealyao/article/details/6460578 для подробностей
(3) Пример PPT
https://blog.csdn.net/weixin_30347335/article/details/97523472
Дана база данных D и min_sup.
![[ , , (img-2T4xBrR1-1574591500412)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124133500629.png)]](https://russianblogs.com/images/972/b2492c69dbf79c9e24b47bfafcdcfaec.png)
-
Строительство FP-Tree — первый шаг
Первый шаг: сканирование базы данных, чтобы получить частые наборы товаров первого порядка. Поскольку min_sup = 0,5, он появляется как минимум 3 раза, а если он меньше 3 раз, он не рассматривается напрямую, и набор элементов выглядит следующим образом
![[ , , (img-002Fbihj-1574591500414)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124133640618.png)]](https://russianblogs.com/images/696/847bcdfb3f7f72f7a713e0d9c2b0b6c8.png)
-
Строительство FP-Tree — второй шаг
Шаг 2: Сортируйте частые элементы в порядке убывания частоты, обратите внимание на порядок внутри
-
Строительство FP-Tree — третья ступень
Элементы данных в каждой транзакции вставляются в дерево с NULL в качестве корневого узла в порядке убывания, поэтому все упорядоченные частые элементы сохраняются в дереве. , Верхний узел является узлом-предком, а нижний узел является узлом-потомком. Если есть общий предок, то количество соответствующих узлов общего предка увеличивается на единицу. После вставки, если появляется новый узел, узел, соответствующий таблице заголовка элемента, будет связан с новым узлом через список узлов. Пока все данные не будут вставлены в дерево FP, создание дерева FP будет завершено.
-
FP-Tree майнинг — первый шаг
Получив дерево FP и таблицу заголовков элементов и связанный список узлов, мы должны сначала вырыть из нижней части таблицы заголовков элементов. Для каждого элемента в таблице заголовков элементов, соответствующего дереву FP, нам нужно найти его базу условных шаблонов. База условных шаблонов — это поддерево FP, соответствующее конечному узлу, который мы хотим использовать в качестве конечного узла. Чтобы получить это поддерево FP, мы устанавливаем количество каждого узла в поддереве равным количеству конечных узлов и удаляем узлы, чье количество ниже уровня поддержки. На основе этого условного паттерна мы можем рекурсивно добывать частые наборы элементов.
Когда элемент равен x, то есть суффикс x, каковы его префиксы? Какое количество вхождений? Например, суффикс c, префикс f, и он появляется 3 раза, а для другого примера суффикс b, а его префикс fca (1 раз), f (1 раз), c (1 раз), что означает -
FP-Tree майнинг — второй шаг
Установите количество каждого узла полученного поддерева FP равным количеству конечных узлов и удалите узлы, число которых ниже уровня поддержки ** (здесь по крайней мере 3) **. Мы можем получить частые наборы предметов.
https://blog.csdn.net/weixin_30347335/article/details/97523472, обязательно посмотрите этот пример
Например, если листовой узел первого порядка
Копайте снизу вверх. Сначала посмотрите на p, его частый набор элементов: {f: 2, c: 3, a: 2, m: 2, b: 1, p: 3}, первые 5 представляют основу условного паттерна (на каждом языке это обычное явление). Несколько раз, например, c появляется 2 + 1 раза), число f, a, m, b меньше 3, что меньше, чем необходимая нам поддержка, удалить, объединить, получить частый бином n узла p Набор {c: 3, p: 3}, самый большой набор частых элементов, соответствующий p, является набором частых биномов.
Посмотрите снова на m, его частый набор элементов {f: 3, c: 3, a: 3, b: 1, m: 3}, удалите b, чтобы получить частый набор из четырех элементов m {f: 3, c: 3 , а: 3m: 3}
Посмотрите на b снова, его частый набор элементов {f: 2, c: 2, a: 1, b: 3}, удалите fca, он просто обычное знание, пустой
Посмотрите еще раз, его частый набор элементов {f: 3, c: 3, a: 3}, это его частый набор элементов третьего порядка
Посмотри на с …
Примеры, приведенные учителем(первый уровень)
Результат первого порядка, очевидно, согласуется с результатом идеи, которую мы только что сделали
Например, если конечный узел второго порядка или выше, та же идея
![[ , , (img-jbbSi22a-1574591500415)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124133748610.png)]](https://russianblogs.com/images/508/919bb3ad42389e250233025dd2bc3ba4.png)







Глава 6: Классификация майнинга
1. Классификация данных
- Анализ образцов обучающих данных для точного описания категорий
- Эта категория обычно состоит из правил классификации и может использоваться для классификации и прогнозирования будущих данных
Прежде всего, каждая информация (запись) помечается меткой, то есть данные (запись) классифицируются в соответствии с меткой, и классификационный анализ должен выявить присущие ей характеристики и законы для каждого типа данных (группы записей с одинаковой меткой).
2. Этапы классификации данных
Создайте модель, которая описывает данный набор классов или концепций данных, и создайте модель, анализируя кортежи базы данных, описанные атрибутами
- Набор кортежей, используемых для построения модели, называется набором обучающих данных, где каждый кортеж состоит из обучающих выборок.
Характер обучающих выборок и анализируемых выборок по сути одинаков, они представляют собой данные, накопленные в реальной среде. - Каждый обучающий образец относится к предопределенному классу, определяемому атрибутом метки класса
- Поскольку задан атрибут метки класса, этот шаг становится управляемым обучением
Нужно знать количество категорий и значение соответствующих категорий для людей
Если метка класса обучающей выборки неизвестна, она называется*** Неуправляемое обучение (кластеризация) *** - Модель обучения может быть представлена в виде правил классификации, деревьев решений и математических формул
Используйте модели для классификации данных
- Оценить точность классификации модели
Характер данных обучения и данных испытаний должен быть одинаковым, но не одинаковыми данными
Критерии оценки включают правильность, эффективность и понятность - Классифицировать кортежи с неизвестными метками классов по моделям
3. Классификационный метод анализа
Это метод индукции признаков, который извлекает характеристики, общие для каждого типа данных, для получения регулярных правил. В настоящее время существует множество методов анализа.Прочитав тестовую статью предыдущего года, я взял дерево решений и Наивный Байес
- Дерево решений-Экзамен ID3
- Наивный байесовский
- Определите вероятность того, что конкретный образец относится к категории в метке, по предшествующей вероятности и последующей вероятности
Значение вероятности предоставляется в соответствии с обучающей выборкой - Результаты, полученные методом Байеса, не являются уникальными и могут обеспечить вероятность соответствующих результатов.
- Байесовский метод является вычислительно сложным
Когда каждый атрибут независим, вычисление байесовского метода может быть упрощено
- Определите вероятность того, что конкретный образец относится к категории в метке, по предшествующей вероятности и последующей вероятности
Вышеупомянутые два метода основаны на теории информации и имеют очень хорошиеPrunability
, , , , , , , , , Нейронные сети и K-алгоритмы близости не должны тестироваться. , , , , , , , , , , , , Ставить!
4. Схема дерева решений ID3
#### (1) Концепция
Также известный как дерево решений, это древовидная структура, используемая для классификации
-
Согласно разделению решения, связанному со следующим решением или заключением, сформированные отношения являются деревом решений
-
Каждый внутренний узел представляет собой тест определенного атрибута
-
Каждое ребро представляет результат теста
-
Конечные узлы представляют класс или распределение классов
-
Верхний узел является корневым узлом
-
Вычисляя количество информации, определите вклад каждого атрибута в суждение, сделанное классификацией.
Разбейте множество S на S1 и S2, и размер информации будет иметь следующие отношения:I(S)≥I(S1)+I(S2) (Возьмите знак равенства, когда атрибут не влияет на классификацию) Информационный прирост атрибута A = I (S) - [I (S1) + I (S2)]Поместите атрибут с лучшим вкладом в верхний слой и повторите
- Отмена условия
- Набор данных тренировки пуст
- Классификация была определена
I(S)=0 - Атрибуты были исчерпаны и до сих пор не могут быть классифицированы с уверенностью
- Отмена условия
(2) алгоритм ID3
https://blog.csdn.net/qq_28697571/article/details/84678889 Рекомендуемый блог
Алгоритм, основанный на дереве решений, согласно получению информации, построению жадного дерева сверху вниз, получению информации, используется для измерения качества определенного атрибута, чтобы классифицировать набор выборок, мы должны выбрать атрибут с наибольшим выигрышем в информации. Дерево решений создается на основе обучающих объектов и известных меток классов, а прирост информации используется в качестве показателя для ранжирования атрибутов.
Два типа тегов: P (при условии, что p элементов) и N (при условии, что n элементов), информация, используемая для определения того, принадлежит ли какой-либо элемент к P или N:

Набор S делится на наборы {S1, S2, …, Sv} в соответствии с атрибутом A. В каждом Si элемент, принадлежащий классу P, равен Pi, а элемент, принадлежащий N, равен ni, Количество информации (энтропии), используемой для различения, составляет

Рассчитать информационный прирост атрибута A Gain (A)

Посмотрите прямо на пример PPT
Учитывая эту таблицу, в соответствии с каким атрибутом классифицировать?
![[ , , (img-ox6vhcm0-1574591500422)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124152229882.png)]](https://russianblogs.com/images/648/9333897e935922e1f1cc12f1901fde88.png)
В этом примере
P: buys_computer = «да», N: buys_computer = «нет», 14 данных, p: 9 и n: 5
I(p, n) = I(9, 5) =0.940
Расчет энтропии по возрастному признаку
- Согласно атрибуту age весь входной набор S разделен на три части: <= 30 лет, от 31 до 40 лет,> 40 лет
- <= Среди 5 человек 30 лет, да 2 человека, нет 3 человек, то есть 5/14 * I (2,3)
- Из 4 человек в возрасте от 31 до 40 лет, да 4 человека, нет 0 человек, то есть 4/14 * я (4,0)
- Из 5 человек старше 40 лет, да 3 человека, нет 2 человек, то есть 5/14 * я (3,2)
- Энтропия E (возраст) атрибута возраста может быть получена суммированием
Gain(age) = I(9,5) — E(age)
Следуйте тому же методу, чтобы найти Gain (доход), Gain (студент), Gain (credit_rating)
Результаты Прирост (возраст) = 0,25> Прибыль (студент)> Прибыль (кредит_рейтинг)> Прибыль (доход)
![[ , , (img-XGFYMxKg-1574591500422)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124154702015.png)]](https://russianblogs.com/images/539/209b38df46a37ee073b859e0cd56d30b.png)
Таким образом, мы знаем, какой атрибут отсортирован, а затем три случая по возрастной классификации
-
В случае <30, вычислите информационный прирост и найдите, что у студента самый большой информационный прирост, затем установите студента как узел;
-
Только да между 30-40, так что расчет не требуется
-
В случае> 40, если информационный прирост кредитного рейтинга оказывается наибольшим, он устанавливается как узел.

5. Наивный байесовский
Математическая основа наивного байесовского алгоритма основана на теореме Байеса, поэтому этот вид алгоритма называется наивным байесовским алгоритмом. ** Принцип классификации заключается в использовании байесовской формулы для вычисления апостериорной вероятности, то есть вероятности того, что объект принадлежит определенному классу, и выбора класса с наибольшей апостериорной вероятностью в качестве класса, к которому принадлежит объект. ** Ниже приведена формула Байеса. Чтобы максимизировать P (C | X) (априорная вероятность), вы должны максимизировать P (X | C) · P © (апостериорная вероятность),
![[ , , (img-vxK17SA5-1574591500423)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124155700353.png)]](https://russianblogs.com/images/149/83f0048a0c4cca67e5aa7f9f10cce1fd.png)
Наивный Байес предполагает, что атрибуты независимы, а признаки (атрибуты) независимы друг от друга
![[ , , (img-ddLFDxox-1574591500423)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124155826207.png)]](https://russianblogs.com/images/703/8d1ab6ebcb2c7c1b7dd14f0fdd8287f7.png)
пример 1
![[ , , (img-sJhqQ63n-1574591500424)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124162156159.png)]](https://russianblogs.com/images/859/47c8fc22cec562a6320b52ff4ef1638b.png)
Пример игры в теннис, p означает, что в игру можно играть, n означает, что в игру нельзя играть, X = <rain, hot, high, false>
![[ , , (img-8XsU8fLW-1574591500424)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124162544909.png)]](https://russianblogs.com/images/777/8aadbdcac8426f92ee7456fb33fa7c79.png)
Пример 2: Байесовская сеть убеждений / сеть вероятностей
Должен объединить причинно-следственную связь между байесовским выводом и атрибутами
Пример вопроса по PPT непосредственно смотрит на этот вопрос https://blog.csdn.net/qq_36739040/article/details/102652763
![[ , , (img-xaapQdqq-1574591500424)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124162932598.png)]](https://russianblogs.com/images/561/ffac5081bada001568b937518a5f06c9.png)
Сначала вычислите априорную вероятность страдания от болезни сердца
![[ , , (img-NMJKrr5U-1574591500425)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124163546868.png)]](https://russianblogs.com/images/482/27c823210cafcac4e0d1231dd6844daa.png)
α: возможное значение E, β: возможное значение D
Поскольку Наивный Байес предполагает независимость между атрибутами, то есть E и D независимы, то: P (E = α, D = β) = P (E = α) * P (D = β)
То есть четыре случая складываются, неправильный порядок PPT
Использовал эти данные
![[ , , (img-yM2u6ayZ-1574591500425)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124164447167.png)]](https://russianblogs.com/images/54/d89d5f354cb58c941f1672787c058356.png)
Вывод: вероятность отсутствия сердечно-сосудистых заболеваний выше
В случае BP = высокий, тот же метод используется для расчета данных гипертонии, которая связана с HD
![[ , , (img-vfX423m2-1574591500425)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124164615573.png)]](https://russianblogs.com/images/103/4414531e92b354b6a9c88aeb64c55287.png)
Вывод: если артериальное давление высокое, вероятность сердечных заболеваний выше
Вероятность HD в случае АД = высокая, D = здоровая, E = да (вероятность высокого кровяного давления, здорового питания, болезней сердца во время физических упражнений)
![[ , , (img-8GE5sSuW-1574591500426)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124164919569.png)]](https://russianblogs.com/images/535/6648fcd236750992921bda46793abb6f.png)
Глава 7: Кластерный майнинг
1. Кластерный анализ
Кластерный анализ состоит в том, чтобы найти взаимосвязь между объектами данных в данных, сгруппировать данные, чем больше сходство внутри группы, тем больше разница между группами, тем лучше эффект кластеризации.
- Также известный как кластерный анализ, это многомерный статистический метод для изучения задач классификации
- Разделен наДистанционная кластеризацияс участиемКластеризация коэффициентов сходстваТо есть двумя способами определить степень сходства, на самом деле нет необходимости строго различать
- Выбранная часть данных не мала, и модель получается после обработки, а затем модель используется для двух этапов общей обработки.
Смешанное использование с классификационным анализом
Поскольку временная сложность кластерного анализа связана с общим количеством выборок, часть данных может быть взята для кластерного анализа. После получения результатов для каждого кластера вырабатываются концептуальные правила, чтобы искусственно определить некоторые концептуальные правила, а затем использовать это правило для остальных Классификация данных
- Входными данными кластерного анализа являются немаркированные записи, и система разумно делит набор записей в соответствии с определенными правилами.
эквивалентно маркировке записей, но критерии классификации не определяются пользователем - Затем используйте метод классификации для анализа данных и повторно разделите исходный набор записей в соответствии с результатом анализа, а затем выполните другой анализ классификации
- Повторяйте, пока не получите удовлетворительный результат анализа.
2. Основные методы кластеризации
-
На основе метода разбиения
В некоторых сценариях число k кластеров известно, даже если количество кластеров неизвестно, его можно определить исчерпывающим образом (1≤k≤N).
- Случайно выбрать k данных
- Отметить все остальные данные на ближайшем расстоянии
завершить итерацию - Выберите фактическую (или виртуальную) точку данных на основе текущего кластера
представитель - Вторая итерация, разделить снова в соответствии с выбранной точкой
Репрезентативные точки данных продолжают изменяться - Повторяйте это до тех пор, пока кластеризация всех данных больше не изменится
- Выбор репрезентативных точек данных
- Если фактические точки данных выбраны в качестве представителей, критерии выбора трудно определить
- Если вы выбрали виртуальную точку данных в качестве представителя, точка данных может не иметь смысла, вам нужно выбрать тип в соответствии с фактической задачей
-
Многоуровневый подход
Объедините две данные с наибольшим сходством и используйте виртуальную точку данных в качестве ее представителя, чтобы повторить расчет
- Значение k не обязательно указывать
использует степень сходства внутри кластеров и степень различия между кластерами в качестве индикаторов - Без итеративного процесса результаты могут быть неточными
- Значение k не обязательно указывать
PS: я сдал экзамен в предыдущие годыАлгоритм K-среднихс участием Алгоритм сжатого иерархического расстояния
3. Алгоритм кластеризации K-средних
Это метод расстояний на основе разделов, в котором в качестве репрезентативной точки кластера используется среднее значение всех выборок данных в каждом подмножестве кластера. Сделайте каждый сгенерированный кластер компактным и независимым.
Расстояние, на котором появится тест, — это в основном расстояние от Манхэттена

алгоритм k-средних
Входные данные: количество кластеров k и база данных, содержащая n объектов.
Вывод: k кластеров, минимизирующих критерий квадратичной ошибки.
Шаги алгоритма:
1. Определите начальный центр кластера для каждого кластера, чтобы было K исходных центров кластера.
2. Назначьте образцы в наборе образцов на ближайший кластер в соответствии с принципом минимального расстояния
3. Используйте выборочное среднее значение в каждом кластере в качестве нового кластерного центра.
4. Повторяйте шаг 2.3, пока центр кластера больше не изменится.
5. Конец, получить K кластеров
Подготовка к экзаменационным вопросам [Конец 2012]
![[ , , (img-Q2dASTqB-1574591500427)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124172648779.png)]](https://russianblogs.com/images/234/1c7b31af50ba7b6e5bbbf7c542295a1a.png)
** Первый вопрос: попросите матрицу несоответствия. ** Матрица различий (сохраняет аппроксимацию между n объектами в парах). В то же время предлагается также матрица, представляющая n объектов, а именно матрица данных (использующая p-переменные для представления n объектов), как показано ниже.
![[ , , (img-Ywq4nKCt-1574591500428)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124172917126.png)]](https://russianblogs.com/images/505/f28f15ecb8b760f2d87827eef3625cb1.png)
Нам просто нужно перенести значения x и y каждого кортежа в манхэттенское расстояние, чтобы вычислить ответ -_-
![[ , , (img-1MSzFfMl-1574591500428)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124173108400.png)]](https://russianblogs.com/images/802/dd331f444d5718f138afd73a36d1f852.png)
Вторая проблема: кластеризация набора данных, Учитывая количество кластеров как k = 3, учитывая три начальные центральные точки (3, 5), (2, 6), (3, 8), всего 12 точек (объектов), то для оставшихся 9 точек (объектов) присваиваются ближайшему кластеру в соответствии с их расстоянием от центра каждого кластера. Говоря о местных точках, мы говорим о расстоянии до Манхэттена, чтобы вычислить, к какой центральной точке он близок, и классифицируем его.
![[ , , (img-s6klZyFf-1574591500429)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124174754568.png)]](https://russianblogs.com/images/42/13be12b0926ca9a36430433960757862.png)
Просто посмотрите на первые три столбца и возьмите самый маленький в соответствующий кластер.
(1,4,6,7,11,12)
(2,9)
(3,5,8,10)
Отрегулируйте центральные точки трех кластеров
(1,4,6,7,11,12) --> x = (3+3+4+9+5+4)/6 = 4.6;y = (5+4+5+1+2+2)/6 = 3.17 (4.6,3.17)
(2,9) --> x = (2+1)/2 = 1.5;y = (6+6)/2 = 6 (1.5,6)
(3,5,8,10) x = (3+7+4+6)/4 = 5;y=(8+7+10+8)/4 = 8.25 (5,8.25)
Затем рассчитайте расстояние до трех центральных точек от каждой точки, чтобы получить три кластера
Продолжайте делать это, пока кластер не изменится
### 4, алгоритм сжатого иерархического расстояния
[Конец 2014 года] б спросить
![[ , , (img-c2tHoFOw-1574591500429)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124180341531.png)]](https://russianblogs.com/images/610/008fd3b821be996377edc04b0847b7f2.png)
![[ , , (img-kUR8nSNU-1574591500429)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124180928025.png)]](https://russianblogs.com/images/279/92529a18b43e95e157b102cbc04f444f.png)
Рассчитайте расстояние между каждой точкой и другими точками, выберите две точки с наименьшим расстоянием в качестве начальных двух точек, соберите их, чтобы вычислить их центральную точку, а затем вычислите расстояние между этой центральной точкой и другими n-2 точками, Затем возьмите два наименьших из них, а затем вычислите центральную точку … пока все они не сойдутся. В конце мы хотим разделить на несколько категорий и разрезать его на последних нескольких шагах. Например, его необходимо сгруппировать в две категории: одну на шаге 3, одну категорию — cde, а другую — ab.
Первоначальный спрашивает Манхэттен расстояние
![、[ , , (img-LKkRTe9u-1574591500430)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124182805650.png)]](https://russianblogs.com/images/893/1e2b21b4a1bfb6230d2dc9eaef9fab3d.png)
Соберите 1 и 3, затем рассчитайте расстояние от других точек до новой точки
![[ , , (img-80aANeDH-1574591500430)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124182840259.png)]](https://russianblogs.com/images/895/bba73c0d6711041b883ab98ebab91117.png)
Соберите 135, а затем рассчитайте расстояние от других точек до новой точки
![[ , , (img-uwJw7PY3-1574591500430)(/Users/zhangye/Library/Application Support/typora-user-images/image-20191124182904118.png)]](https://russianblogs.com/images/803/2cad7c31210d0fe129d40cf318d7b03b.png)
Соберись 1352, и наконец соберись 12345

Оглавление
1. Указать особенности подходов к понятию business intelligence............1
2. Классификация продуктов business intelligence…….….….….….….….….…1
3. Указать основных игроков на поле business intelligence…………………….2
4. Описать предпосылки к развитию систем business intelligence.………...1
5. Указать место BI-систем в корпоративной информационной системе
предприятия………………………………………………………….….….….….….….….…...1
6. Описать особенности процесса функционирования хранилища
данных. Сценарий функционирования хранилища данных………….….….…1
7. Описать особенности процесса преобразования корпоративной
модели данных в хранилище…………………………………………….….….….….…...1
8. Описать особенности процесса проектирования хранилища данных.
Виды таблиц………………………………………………………………………………….….…1
9. Указать особенности моделей данных, используемых при построении
Хранилищ данных. (Из презы)………………………………………………..….….….…2
10. Описать критерии, определяющие выбор инструментов для
моделирования хранилищ данных……………………………………….….….….….…3
11. Описать особенности методологии создания хранилищ данных.......1
12. Указать особенности архитектуры ИАС на базе хранилищ данных.. 2
13. Описать процессы предобработки и очистки данных перед
загрузкой в хранилище……………………………………………………………….….….…4
14. Указать особенности BI-приложений и их назначения в
стратегических информационных системах……………………….….….….….…..1
15. Указать особенности информационно-аналитических систем BPM-
класса как промышленного стандарта BPM.……………….….….….….….….…..2
16. Указать отличие стратегического управления от оперативного и
особенности его обеспечения в BPM-системах.…………………………………….1
17. Описать этапы стратегического планирования и технологии,
поддерживающие принятие решений…………………………………………….….….2
18. Указать особенности аналитических информационных систем и их
место в процессах управления и информационной инфраструктуре
предприятия………………………………………………………….….….….….….….….…...1
19. Указать особенности становления и сущности концепции
управления эффективностью бизнеса (BPM)………………..….….….….….….…1