Урок посвящен тому, как решать 4 задание ЕГЭ по информатике
Содержание:
- Кодирование информации
- Кодирование и расшифровка сообщений
- Решение 4 заданий ЕГЭ
Кодирование информации
4-е задание: «Кодирование и декодирование информации»
Уровень сложности
— базовый,
Требуется использование специализированного программного обеспечения
— нет,
Максимальный балл
— 1,
Примерное время выполнения
— 2 минуты.
Проверяемые элементы содержания: Умение кодировать и декодировать информацию
До ЕГЭ 2021 года — это было задание № 5 ЕГЭ
Типичные ошибки и рекомендации по их предотвращению:
«Из-за невнимательного чтения условия задания экзаменуемые иногда не замечают, что требуется найти кодовое слово минимальной длины с максимальным (минимальным) числовым значением.
Кроме того, если в задании указано, что несколько букв остались без кодовых слов (как, например, в задании демоварианта), то кодовое слово для указанной буквы должно быть подобрано таким образом, чтобы осталась возможность найти кодовые слова, удовлетворяющие условию Фано, и для других букв. Так, например, если мы букву А закодируем нулём, а букву Б единицей, то букву В мы уже никак не сможем закодировать с соблюдением условия Фано, поэтому длину кодового слова для А или Б следует увеличить»
ФГБНУ «Федеральный институт педагогических измерений»
- Кодирование — это представление информации в форме, удобной для её хранения, передачи и обработки. Правило преобразования информации к такому представлению называется кодом.
- Кодирование бывает равномерным и неравномерным:
- при равномерном кодировании всем символам соответствуют коды одинаковой длины;
- при неравномерном кодировании разным символам соответствуют коды разной длины, это затрудняет декодирование.
Пример: Зашифруем буквы А, Б, В, Г при помощи двоичного кодирования равномерным кодом и посчитаем количество возможных сообщений:

Таким образом, мы получили равномерный код, т.к. длина каждого кодового слова одинакова для всех кодов (2).
Кодирование и расшифровка сообщений
Декодирование (расшифровка) — это восстановление сообщения из последовательности кодов.
Для решения задач с декодированием, необходимо знать условие Фано:
Условие Фано: ни одно кодовое слово не должно являться началом другого кодового слова (что обеспечивает однозначное декодирование сообщений с начала)
Префиксный код — это код, в котором ни одно кодовое слово не совпадает с началом другого кодового слова. Сообщения при использовании такого кода декодируются однозначно.
- если сообщение декодируется с конца, то его можно однозначно декодировать, если выполняется обратное условие Фано:
- условие Фано – это достаточное, но не необходимое условие однозначного декодирования.
Обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова
Постфиксный код — это код, в котором ни одно кодовое слово не совпадает с концом другого кодового слова. Сообщения при использовании такого кода декодируются однозначно и только с конца.

Однозначное декодирование обеспечивается:

Однозначное декодирование

Декодирование
Егифка ©:

Задание демонстрационного варианта 2022 года ФИПИ
Плейлист видеоразборов задания на YouTube: 
ЕГЭ 4.1: Для кодирования букв О, В, Д, П, А решили использовать двоичное представление чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления).
Закодируйте последовательность букв ВОДОПАД таким способом и результат запишите восьмеричным кодом.
✍ Решение:
- Переведем числа в двоичные коды и поставим их в соответствие нашим буквам:
О -> 0 -> 00 В -> 1 -> 01 Д -> 2 -> 10 П -> 3 -> 11 А -> 4 -> 100
ВОДОПАД:010010001110010
010 010 001 110 010 ↓ ↓ ↓ ↓ ↓ 2 2 1 6 2
Результат: 22162
Теоретическое решение ЕГЭ данного задания по информатике, видео:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
Рассмотрим еще разбор 4 задания ЕГЭ:
ЕГЭ 4.2: Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв — из двух бит, для некоторых — из трех). Эти коды представлены в таблице:
| a | b | c | d | e |
|---|---|---|---|---|
| 000 | 110 | 01 | 001 | 10 |
Какой набор букв закодирован двоичной строкой 1100000100110?
✍ Решение:
- Во-первых, проверяем условие Фано: никакое кодовое слово не является началом другого кодового слова. Условие верно.
- Код разбиваем слева направо согласно данным, представленным в таблице. Затем переведём его в буквы:
✎ 1 вариант решения:
110 000 01 001 10 ↓ ↓ ↓ ↓ ↓ b a c d e
Результат: b a c d e.
✎ 2 вариант решения:
-
Этот вариант решения 4 задания ЕГЭ более сложен, но тоже верен.
- Сделаем дерево, согласно кодам в таблице:
- Сопоставим закодированное сообщение с кодами в дереве:

110 000 01 001 10
Результат: b a c d e.
Кроме того, вы можете посмотреть видеорешение этого задания ЕГЭ по информатике (теоретическое решение):
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
Решим следующее 4 задание:
ЕГЭ 4.3:
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4, и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23, то получим последовательность 0010100110).
Определите, какое число передавалось по каналу в виде 01100010100100100110.
✍ Решение:
- Рассмотрим пример из условия задачи:
Было2310 Стало00101001102
0010100110 (0010 - 2, 0011 - 3)
01100 01010 01001 00110
0110 0101 0100 0011
0110 0101 0100 0011 ↓ ↓ ↓ ↓ 6 5 4 3
Ответ: 6 5 4 3
Вы можете посмотреть видеорешение этого задания ЕГЭ по информатике, теоретическое решение:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
ЕГЭ 4.4:
Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0, для буквы К — кодовое слово 10.
Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
Подобные задания для тренировки
✍ Решение:
✎
1 вариант решения
основан на логических умозаключениях:
- Найдём самые короткие возможные кодовые слова для всех букв.
- Кодовые слова 01 и 00 использовать нельзя, так как тогда нарушается условие Фано (начинаются с 0, а 0 — это Н).
- Начнем с двухразрядных кодовых слов. Возьмем для буквы Л кодовое слово 11. Тогда для четвёртой буквы нельзя подобрать кодовое слово, не нарушая условие Фано (если потом взять 110 или 111, то они начинаются с 11).
- Значит, надо использовать трёхзначные кодовые слова. Закодируем буквы Л и М кодовыми словами 110 и 111. Условие Фано соблюдается.
- Суммарная длина всех четырёх кодовых слов равна:
(Н)1 + (К)2 + (Л)3 + (М)3 = 9
✎ 2 вариант решения:
- Будем использовать дерево. Влево откладываем 0, вправо — 1:
- Теперь выпишем соответствие каждой буквы ее кодового слова согласно дереву:

(Н) -> 0 -> 1 символ (К) -> 10 -> 2 символа (Л) -> 110 -> 3 символа (М) -> 111 -> 3 символа
(Н)1 + (К)2 + (Л)3 + (М)3 = 9
Ответ: 9
4.5:
По каналу связи передаются сообщения, содержащие только 4 буквы: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А, Б, В используются такие кодовые слова:
А: 101010, Б: 011011, В: 01000
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Подобные задания для тренировки
✍ Решение:
- Наименьшие коды могли бы выглядеть, как 0 и 1 (одноразрядные). Но это не удовлетворяло бы условию Фано (А начинается с единицы — 101010, Б начинается с нуля — 011011).
- Следующим наименьшим кодом было бы двухбуквенное слово 00. Так как оно не является префиксом ни одного из представленных кодовых слов, то Г = 00.
Результат: 00
4.6:
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приемной стороне канала связи. Использовали код:
А - 01 Б - 00 В - 11 Г - 100
Укажите, каким кодовым словом должна быть закодирована буква Д. Длина этого кодового слова должна быть наименьшей из всех возможных. Код должен удовлетворять свойству однозначного декодирования. Если таких кодов несколько, укажите код с наименьшим числовым значением.
✍ Решение:
- Так как необходимо найти кодовое слово наименьшей длины, воспользуемся деревом. Влево будем откладывать нули, а вправо — единицы:
- Поскольку у нас все ветви завершены листьями, т.е. буквами, кроме одной ветви, то остается единственный вариант, куда можно поставить букву Д:
- Перепишем сверху вниз получившееся кодовое слово для Д: 101


Результат: 101
Подробней разбор урока можно посмотреть на видео ЕГЭ по информатике 2017:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
4.7: Демоверсия ЕГЭ 2018 информатика (ФИПИ):
По каналу связи передаются шифрованные сообщения, содержащие только десять букв: А, Б, Е, И, К, Л, Р, С, Т, У. Для передачи используется неравномерный двоичный код. Для девяти букв используются кодовые слова.

Укажите кратчайшее кодовое слово для буквы Б, при котором код будет удовлетворять условию Фано. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Подобные задания для тренировки
✍ Решение:
- Для решения будем использовать дерево. Ветви, соответствующие нулю, будем откладывать влево, единице — вправо.
- При рассмотрении дерева видим, что все ветви «закрыты» листьями, кроме одной ветви — 1100:


Результат: 1100
Подробное теоретическое решение данного 4 (раньше №5) задания из демоверсии ЕГЭ 2018 года смотрите на видео:
📹 Видеорешение на RuTube здесь
4.8:
По каналу связи передаются шифрованные сообщения, содержащие только четыре букв: А, Б, В, Г; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв А, Б, В используются кодовые слова:
А: 00011 Б: 111 В: 1010
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
✍ Решение:
- Для решения будем использовать дерево. Ветви, соответствующие нулю, будем откладывать влево, единице — вправо.
- Поскольку в задании явно не указано о том, что код должен удовлетворять условию Фано, то дерево нужно построить как с начала (по условию Фано), так и с конца (обратное условие Фано).
- Получившееся числовое значение кодового слова для буквы Г — 01.
- Получившееся числовое значение кодового слова для буквы Г — 00.
- После сравнения двух кодовых слов (01 и 00), код с наименьшим числовым значением — это 00.
Дерево по условию Фано (однозначно декодируется с начала):

Дерево по обратному условию Фано (однозначно декодируется с конца):

Результат: 00
4.9:
По каналу связи передаются сообщения, содержащие только буквы: А, Е, Д, К, М, Р; для передачи используется двоичный код, удовлетворяющий условию Фано. Известно, что используются следующие коды:
Е – 000 Д – 10 К – 111
Укажите наименьшую возможную длину закодированного сообщения ДЕДМАКАР.
В ответе напишите число – количество бит.
Подобные задания для тренировки
✍ Решение:
- С помощью дерева отобразим известные коды для букв:
- В результирующем слове — ДЕДМАКАР — вде буквы А. Значит, для получения наименьшей длины необходимо для буквы А выбрать наименьший код в дереве. Учтем это и достроим дерево для остальных трех букв А, М и Р:
- Расположим буквы в порядке их следования в слове и подставим их кодовые слова:


Д Е Д М А К А Р 10 000 10 001 01 111 01 110
Результат: 20
Смотрите виде решения задания:
📹 YouTube здесь
📹 Видеорешение на RuTube здесь
Привет! Сегодня узнаем, как решать 4 задание из ЕГЭ по информатике нового формата 2021.
Четвёртое задание из ЕГЭ по информатике раскрывает тему кодирование информации. Одним из центральных приёмов при решении задач подобного типа является построение дерева Фано. Рассмотрим на примерах этот метод.
Задача (стандартная)
По каналу связи передаются сообщения, содержащие только шесть букв: А, B, C, D, E, F. Для передачи используется неравномерный двоичный код, удовлетворяющий условию Фано. Для букв A, B, C используются такие кодовые слова: А — 11, B — 101, C — 0. Укажите кодовое слово наименьшей возможной длины, которое можно использовать для буквы F. Если таких слов несколько, укажите то из них, которое соответствует наименьшему возможному двоичному числу.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование
Решение:
Т.к. код букв должен удовлетворять условию Фано (т.е. однозначно декодироваться), то
расположим буквы, которые уже имеют код (A, B, C), на Дереве Фано.
Дерево Фано для двоичного кодирования начинается с двух направлений, которые означают 0(ноль) и 1(единицу) (цифры двоичного кодирования).
От каждого направления можно также рисовать только два направления: 0(ноль) и 1(единицу) и т.д. Для удобства будем рисовать 1(единицу) только вправо, а 0(ноль) только влево.
Получается структура похожая на дерево!
В конце каждой ветки можно располагать букву, которую мы хотим закодировать, но если мы расположили букву, от этой ветки больше нельзя делать новых ответвлений.
Такой подход позволяет однозначно декодировать сообщение, состоящее из этих букв.
.jpg?7 "ЕГЭ по информатике - задание 4 (Дерево Фано)")
Буква C заблокировала левую ветку, поэтому будем работать с правой частью нашего дерева.
Если мы расположим какую-нибудь букву на оставшуюся ветку (100), то эта ветка заблокируется, и нам некуда будет писать остальные 2 буквы. Поэтому продолжаем ветку (100) дальше.
.jpg?6 "ЕГЭ по информатике - задание 4 (Дерево Фано решение)")
Теперь свободно уже две ветки, а нам нужно закодировать ещё три буквы. Поэтому должны ещё раз продолжить дерево от какой-нибудь ветки.
Но уже видно, что букве F будет правильно присвоить код 1000, т.к. нам в условии сказано, что код буквы F должен соответствовать наименьшему возможному двоичному числу. Как расположить буквы D и E в данной задаче не принципиально.
.jpg?4 "ЕГЭ по информатике - задание 4 (Дерево Фано окончательное решение)")
Ответ: 1000.
Ещё один важный тип задания 4 из ЕГЭ по информатике нового формата 2021.
Задача (стандартная)
По каналу связи передаются сообщения, содержащие только семь букв: А, Б, И, К, Л, С, Ц. Для передачи используется двоичный код, удовлетворяющий условию Фано. Кодовые слова для некоторых букв известны: Б — 00, К — 010, Л — 111. Какое наименьшее количество двоичных знаков потребуется для кодирования слова АБСЦИССА?
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Решение:
Коды букв должны удовлетворять условию Фано. Некоторые буквы уже имеют заданные коды (Б, К, Л). Нам нужно, чтобы слово АБСЦИССА имело как можно меньше двоичных знаков. Заметим, что буква C встречается три раза, а буква A два раза, значит, этим буквам стараемся присвоить как можно меньшую длину!
Отметим на дереве Фано уже известные буквы (Б, К, Л).
.jpg?4 "ЕГЭ по информатике - задание 4 (стандартная задача Дерево Фано)")
У нас осталось 4 (четыре) буквы, а свободных веток 3(три), поэтому мы должны продолжить дерево. но какую ветку продолжить ?
1 вариант
Если продолжить линию 1-0, то получится такая картина :
.jpg?4 "ЕГЭ по информатике - задание 4 (тренировочная задача Дерево Фано)")
Теперь получились 4(четыре) свободные ветки равной длины (3(трём) двоичным символам). Т.к. ветки равной длины, то не важно на какую ветку какую букву расположим.
Посчитаем общую длину слова АБСЦИССА.
.jpg?4 "ЕГЭ по информатике - задание 4 (тренировочная задача подсчёт длины)")
3 + 2 + 3 + 3 + 3 + 3 + 3 + 3 = 23.
2 вариант
Продлим линию 1-1-0 (можно и 0-1-1, не принципиально, т.к. эти ветки имеют одинаковую длину.), то получится:
.jpg?4 "ЕГЭ по информатике - задание 4 (тренировочная задача дерево фано 2)")
С мы присваиваем 1-0, т.к. это буква повторяется в сообщении самое большое количество раз, значит, ей присваиваем самый маленький код, чтобы всё сообщение имело наименьшую длину.
Из этих же соображений букве А присваиваем код из трёх двоичных символов 0-1-1.
Подсчитаем общее количество символов в сообщении.
.jpg?4 "ЕГЭ по информатике - задание 4 (тренировочная задача подсчёт длины 2)")
3 + 2 + 2 + 4 + 4 + 2 + 2 + 3 = 22
Длина получилась меньше, чем в первом варианте. Других вариантов нет, поэтому ответ будет 22.
Ответ: 22.
Задача (не сложная)
Для передачи по каналу связи сообщения, состоящего только из символов А, Б, В и Г, используется неравномерный (по длине) код: А-10, Б-11, В-110, Г-0. Через канал связи передаётся сообщение: ВАГБААГВ. Закодируйте сообщение данным кодом. Полученное двоичное число переведите в восьмеричный вид.
Решение:
В этой задаче ничего не сказано про условие Фано. Здесь уже все буквы закодированы, осталось написать сам код.
Задача сводится к переводу из двоичной системы в восьмеричную систему. На эту тему был урок на моём сайте.
.jpg?4 "ЕГЭ по информатике - задание 4 (кодирование сообщения)")
Ответ: 151646.
На этом всё! Увидимся на следующих занятиях по подготовке к ЕГЭ по информатике.
Этого не знаю. Это просто примерные задачи, которые наиболее часто попадаются в книжках и на сайтах по подготовке к ЕГЭ по информатике.
Здравствуйте, а вот такое задание ПО КАНАЛУ СВЯЗИ ПЕРЕДАЮТСЯ СООБЩЕНИЯ, СОДЕРЖАЩИЕ ТОЛЬКО 4 БУКВЫ : А, Б, В, Г; ДЛЯ ПЕРЕДАЧИ ИСП. ДВОИЧНЫЙ КОД, ДОПУСКАЮЩИЙ ОДНОЗНАЧНОЕ ДЕКОДИРОВАНИЕ. ДЛЯ БУКВ А, Б, В ИСПОЛЬЗУЮТСЯ ТАКИЕ КОДОВЫЕ СЛОВА: А:00011, Б:1001, В: 01100.
УКАЖИТЕ КРАТЧАЙШЕЕ КОДОВОЕ СЛОВО ДЛЯ БУКВЫ Г, ПРИ КОТОРОМ КОД БУДЕТ ДОПУСКАТЬ ОДНОЗНАЧНОЕ ДЕКОДИРОВАНИЕ. ЕСЛИ ТАКИХ КОДОВ НЕСКОЛЬКО, УКАЖИТЕ КОД С НАИМЕНЬШИМ ЧИСЛОВЫМ ЗНАЧЕНИЕМ. В ответе указано число 10. Не могу понять почему. У меня 11.
Здравствуйте, а вот такое задание ПО КАНАЛУ СВЯЗИ ПЕРЕДАЮТСЯ СООБЩЕНИЯ, СОДЕРЖАЩИЕ ТОЛЬКО 4 БУКВЫ : А, Б, В, Г; ДЛЯ ПЕРЕДАЧИ ИСП. ДВОИЧНЫЙ КОД, ДОПУСКАЮЩИЙ ОДНОЗНАЧНОЕ ДЕКОДИРОВАНИЕ. ДЛЯ БУКВ А, Б, В ИСПОЛЬЗУЮТСЯ ТАКИЕ КОДОВЫЕ СЛОВА: А:00011, Б:1001, В: 01100.
УКАЖИТЕ КРАТЧАЙШЕЕ КОДОВОЕ СЛОВО ДЛЯ БУКВЫ Г, ПРИ КОТОРОМ КОД БУДЕТ ДОПУСКАТЬ ОДНОЗНАЧНОЕ ДЕКОДИРОВАНИЕ. ЕСЛИ ТАКИХ КОДОВ НЕСКОЛЬКО, УКАЖИТЕ КОД С НАИМЕНЬШИМ ЧИСЛОВЫМ ЗНАЧЕНИЕМ. В ответе указано число 10. Не могу понять почему. У меня 11.
Ольга Владимировна Сорокина, как я понимаю, суть задания в том, что здесь действует либо прямое, либо обратное условие Фано. (Примечание. Условие Фано означает, что соблюдается одно из двух условий.
Либо никакое кодовое слово не является началом другого кодового слова,
либо никакое кодовое слово не является окончанием другого кодового слова.
Это обеспечивает возможность однозначной расшифровки закодированных
сообщений.)
Поэтому 10 является ответом, так как ни один код для букв не оканчивается на 10 (срабатывает обратное условие Фано)
Всего: 34 1–20 | 21–34
Добавить в вариант
Для кодирования растрового рисунка, напечатанного с использованием шести красок, применили неравномерный двоичный код. Для кодирования цветов используются кодовые слова.
Белый — 0, Зелёный — 11111, Фиолетовый — 11110, Красный — 1110, Чёрный — 10. Укажите кратчайшее кодовое слово для кодирования синего цвета, при котором код будет допускать однозначное декодирование.
Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова.
Источник: ЕГЭ по информатике 13.06.2019. Основная волна. Юг-Центр.
По каналу связи передаются сообщения, содержащие только 4 буквы: С, Л, О, Н; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв С, О, Н используются такие кодовые слова: С: 011, О: 00, Н: 11. Укажите такое кодовое слово для буквы Л, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите тот, у которого меньшая длина.
1) 1
2) 10
3) 010
4) 0
По каналу связи передаются сообщения, содержащие только 4 буквы: А, Т, О, М; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Т, О, М используются такие кодовые слова: Т: 100, О: 00, М: 11. Укажите такое кодовое слово для буквы А, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите тот, у которого меньшая длина.
1) 1
2) 0
3) 01
4) 101
По каналу связи передаются сообщения, содержащие только 4 буквы К, О, Р, А; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Р, А, К используются такие кодовые слова:
Р: 000, А: 10, К: 01.
Укажите такое кодовое слово для буквы О, при котором код будет допускать однозначное декодирование. Если таких кодовых слов несколько, укажите то, у которого меньшая длина.
1) 1
2) 0
3) 11
4) 001
По каналу связи передаются сообщения, содержащие только 4 буквы П, О, С, Т; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Т, О, П используются такие кодовые слова:
Т: 111, О: 10, П: 01.
Укажите такое кодовое слово для буквы С, при котором код будет допускать однозначное декодирование. Если таких кодовых слов несколько, укажите тот, у которого меньшая длина.
1) 1
2) 0
3) 00
4) 110
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А–111, Б–110, В–100, Г–101.
Укажите, каким кодовым словом может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
1) 0
2) 01
3) 00
4) 000
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А — 100, Б — 101, В — 111, Г — 110.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
1) 10
2) 11
3) 000
4) 1111
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А — 001, Б — 010, В— 000, Г — 011.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д.
Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
1) 00
2) 01
3) 101
4) 0000
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В и Г использовали такие кодовые слова: А — 111, Б — 110, В — 101, Г — 100.
Укажите, каким кодовым словом из перечисленных ниже может быть закодирована буква Д. Код должен удовлетворять свойству однозначного декодирования. Если можно использовать более одного кодового слова, укажите кратчайшее из них.
1) 1
2) 0
3) 01
4) 10
По каналу связи передаются сообщения, содержащие только четыре буквы: А, Б, В, Г; для передачи используется двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В используются такие кодовые слова: А — 0; Б — 110; В — 100.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Источник: ЕГЭ по информатике 23.03.2016. Досрочная волна
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В, Г использовали соответственно кодовые слова 000, 001, 10, 11. Укажите кратчайшее возможное кодовое слово для буквы Д, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением. Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Источник: Тренировочная работа по ИНФОРМАТИКЕ 11 класс 29 ноября 2016 года Вариант ИН10203
По каналу связи передаются сообщения, содержащие только шесть букв: А, B, C, D, E, F. Для передачи используется неравномерный двоичный код, удовлетворяющий условию Фано. Для букв A, B, C используются такие кодовые слова: А — 11, B — 101, C — 0. Укажите кодовое слово наименьшей возможной длины, которое можно использовать для буквы F. Если таких слов несколько, укажите то из них, которое соответствует наименьшему возможному двоичному числу. Примечание. Условие Фано означает, что ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано, допускают однозначное декодирование
Источник: Тренировочная работа по ИНФОРМАТИКЕ 11 класс 30 сентября 2016 года Вариант ИН10103
По каналу связи передаются сообщения, содержащие только четыре буквы: П, О, С, Т; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Т, О, П используются такие кодовые слова: Т: 111, О: 0, П: 100.
Укажите кратчайшее кодовое слово для буквы С, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Источник: Демонстрационная версия ЕГЭ—2016 по информатике.
По каналу связи передаются сообщения, содержащие только пять букв: A, B, С, D, E. Для передачи используется двоичный код, допускающий однозначное декодирование. Для букв A, B, C используются такие кодовые слова:
A – 111, B – 0, C – 100.
Укажите кратчайшее кодовое слово для буквы D, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
По каналу связи передаются сообщения, содержащие только пять букв: A, B, С, D, E. Для передачи используется двоичный код, допускающий однозначное декодирование. Для букв A, B, C используются такие кодовые слова: A — 1, B — 010, C — 000.
Укажите кратчайшее кодовое слово для буквы E, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В и Г, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В используются такие кодовые слова: А — 000, Б — 1, В — 011.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В и Г, решили использовать неравномерный двоичный код, позволяющий однозначно декодировать двоичную последовательность, появляющуюся на приёмной стороне канала связи. Для букв А, Б, В используются такие кодовые слова: А — 010, Б — 1, В — 011.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
По каналу связи передаются сообщения, содержащие только четыре буквы: А, Б, В, Г; для передачи используется двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В используются такие кодовые слова: А — 0; Б — 110; В — 101.
Укажите кратчайшее кодовое слово для буквы Г, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наибольшим числовым значением.
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Источник: ЕГЭ — 2018. Досрочная волна. Вариант 2., ЕГЭ — 2018. Досрочная волна. Вариант 1.
По каналу связи передаются сообщения, содержащие только четыре буквы: А, Б, В, Г; для передачи используется двоичный код, удовлетворяющий условию Фано. Для букв Б, В, Г используются такие кодовые слова: Б — 101; В — 110; Г — 0.
Укажите кратчайшее кодовое слово для буквы А, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наибольшим числовым значением.
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Источник: ЕГЭ по информатике 2020. Досрочная волна. Вариант 1
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В, Г использовали кодовые слова 100, 101, 00, 01 соответственно. Для двух оставшихся букв — Д и Е — коды неизвестны.
Укажите кратчайшее кодовое слово для буквы Д, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Источник: ЕГЭ по информатике 2020. Досрочная волна. Вариант 2
Всего: 34 1–20 | 21–34
Кодирование – это перевод информации, представленной символами первичного алфавита, в последовательность кодов.
Декодирование (операция, обратная кодированию) – перевод кодов в набор символов первичного алфавита.
Кодирование может быть равномерное и неравномерное. При равномерном кодировании каждый символ исходного алфавита заменяется кодом одинаковой длины. При неравномерном кодировании разные символы исходного алфавита могут заменяться кодами разной длины.
Задача 1
Для кодирования букв О, В, Д, П, А решили использовать двоичное представление
чисел 0, 1, 2, 3 и 4 соответственно (с сохранением одного незначащего нуля в случае одноразрядного представления). Если закодировать последовательность букв ВОДОПАД таким способом и результат записать восьмеричным кодом, то получится
1) 22162
2) 1020342
3) 2131453
4) 34017
Решение:
Представим коды указанных букв в двоичном коде, добавив незначащий нуль для одноразрядных чисел:
| О | В | Д | П | А |
| 0 | 1 | 2 | 3 | 4 |
| 00 | 01 | 10 | 11 | 100 |
Закодируем последовательность букв: ВОДОПАД — 010010001110010.
Разобьём это представление на тройки справа налево и переведём каждую тройку в восьмеричное число.
010 010 001 110 010 — 22162.
Правильный ответ указан под номером 1.
Ответ: 1
Задача 2
Для передачи по каналу связи сообщения, состоящего только из символов А, Б, В и Г, используется посимвольное кодирование: А-10, Б-11, В-110, Г-0. Через канал связи передаётся сообщение: ВАГБААГВ. Закодируйте сообщение данным кодом. Полученное двоичное число переведите в шестнадцатеричный вид.
1) D3A6
2) 62032206
3) 6A3D
4) CADBAADC
Решение:
Закодируем последовательность букв: ВАГБААГВ — 1101001110100110. Разобьем это представление на четвёрки справа налево и переведём каждую четверку в шестнадцатеричное число:
1101 0011 1010 01102 = D3A616
Правильный ответ указан под номером 1.
Ответ: 1
Задача 3
Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв – из двух бит, для некоторых – из трех). Эти коды представлены в таблице:
| a | b | c | d | e |
| 100 | 110 | 011 | 01 | 10 |
Определите, какой набор букв закодирован двоичной строкой 1000110110110, если известно, что все буквы в последовательности – разные:
1) cbade
2) acdeb
3) acbed
4) bacde
Решение:
Мы видим, что условия Фано и обратное условие Фано не выполняются, значит код можно раскодировать неоднозначно.
Значит, будем перебирать варианты, пока не получим подходящее слово :
1) 100 011 01 10 110
Первая буква определяется однозначно, её код 100: a.
Пусть вторая буква — с, тогда следующая буква — d, потом — e и b.
Такой вариант удовлетворяет условию, значит, окончательно получили ответ: acdeb.
Ответ: 2
Задача 4
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4, и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23, то получим последовательность 0010100110). Определите, какое число передавалось по каналу в виде 01010100100111100011?
1) 59143 2) 5971 3) 102153 4) 10273
Решение:
При кодировании под саму цифру отводится 4 разряда, и еще один под код проверки четности (т.е. всего под цифру отводится 5 разрядов).
Разобьем заданную последовательность на группы по 5 бит в каждой:
01010, 10010, 01111, 00011.
отбросим пятый (последний) бит в каждой группе:
0101, 1001, 0111, 0001.
это и есть двоичные коды передаваемых чисел:
01012 = 5, 10012 = 9, 01112 = 7, 00012 = 1.
таким образом, были переданы числа 5, 9, 7, 1 или число 5971.
Ответ: 2
Задача 5
По каналу связи передаются сообщения, содержащие только 4 буквы — П, О, Р, Т. Для кодирования букв используются 5-битовые кодовые слова:
П — 11111, О — 11000, Р — 00100, Т — 00011.
Для этого набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях.
Это свойство важно для расшифровки сообщений при наличии помех (в предположении, что передаваемые биты могут искажаться, но не пропадают). Закодированное сообщение считается принятым корректно, если его длина кратна 5 и каждая пятёрка отличается от некоторого кодового слова не более чем в одной позиции; при этом считается, что пятёрка кодирует соответствующую букву. Например, если принята пятерка 00000, то считается, что передавалась буква Р.
Среди приведённых ниже сообщений найдите то, которое принято корректно, и укажите его расшифровку (пробелы несущественны).
11011 11100 00011 11000 01110
00111 11100 11110 11000 00000
1) ПОТОП
2) РОТОР
3) ТОПОР
4) ни одно из сообщений не принято корректно
Решение:
Длина обоих сообщений кратна пяти.
Анализируя первое сообщение «11011 11100 00011 11000 01110», приходим к выводу, что оно принято некорректно, поскольку нет такого слова, которое бы отличалось от слова «01110» только в одной позиции.
Рассмотрим второе сообщение. Учитывая, что каждая пятёрка отличается от некоторого кодового слова не более чем в одной позиции, его возможно расшифровать только как «ТОПОР».
Ответ: 3
Задача 6
Для передачи данных по каналу связи используется 5-битовый код. Сообщение содержит только буквы А, Б и В, которые кодируются следующими кодовыми словами: А — 11010, Б — 10111, В — 01101.
При передаче возможны помехи. Однако некоторые ошибки можно попытаться исправить. Любые два из этих трёх кодовых слов отличаются друг от друга не менее чем в трёх позициях. Поэтому если при передаче слова произошла ошибка не более чем в одной позиции, то можно сделать обоснованное предположение о том, какая буква передавалась. (Говорят, что «код исправляет одну ошибку».) Например, если получено кодовое слово 10110, считается, что передавалась буква Б. (Отличие от кодового слова для Б только в одной позиции, для остальных кодовых слов отличий больше.) Если принятое кодовое слово отличается от кодовых слов для букв А, Б, В более чем в одной позиции, то считается, что произошла ошибка (она обозначается ‘х’).
Получено сообщение 11000 11101 10001 11111. Декодируйте это сообщение — выберите правильный вариант.
1) АххБ
2) АВхБ
3) хххх
4) АВББ
Решение:
Декодируем каждое слово сообщения. Первое слово: 11000 отличается от буквы А только одной позицией. Второе слово: 11101 отличается от буквы В только одной позицией. Третье слово: 10001 отличается от любой буквы более чем одной позицией. Четвёртое слово: 11111 отличается от буквы Б только одной позицией.
Таким образом, ответ: АВхБ.
Ответ: 2
Однозначное декодирование. Условие Фано
Код называется однозначно декодируемым, если любое сообщение, составленное из кодовых слов, можно декодировать единственным способом.
Равномерное кодирование всегда однозначно декодируемо.
Для неравномерных кодов существует следующее достаточное (но не необходимое) условие однозначного декодирования:
Сообщение однозначно декодируемо с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова.
Сообщение однозначно декодируемо с конца, если выполняется обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова.
Задача 7
Для передачи по каналу связи сообщения, состоящего только из букв А, Б, В, Г, решили использовать неравномерный по длине код: A=1, Б=01, В=001. Как нужно закодировать букву Г, чтобы длина кода была минимальной и допускалось однозначное разбиение кодированного сообщения на буквы?
1) 0001
2) 000
3) 11
4) 101
Решение:
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Видим, что ближайший от корня дерева свободный лист (т.е. код с минимальной длиной) имеет код 000.
Ответ: 2
Задача 8
Для кодирования некоторой последовательности, состоящей из букв У, Ч, Е, Н, И и К, используется неравномерный двоичный префиксный код. Вот этот код: У — 000, Ч — 001, Е — 010, Н — 100, И — 011, К — 11. Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему остался префиксным? Коды остальных букв меняться не должны.
Выберите правильный вариант ответа.
Примечание. Префиксный код — это код, в котором ни одно кодовое слово не является началом другого; такие коды позволяют однозначно декодировать полученную двоичную последовательность.
1) кодовое слово для буквы Е можно сократить до 01
2) кодовое слово для буквы К можно сократить до 1
3) кодовое слово для буквы Н можно сократить до 10
4) это невозможно
Решение:
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Легко заметить, что если букву Н перенести в вершину 10, она останется листом. Т.е. кодовое слово для буквы Н можно сократить до 10.
Правильный ответ указан под номером 3.
Ответ: 3
Задача 9
Для кодирования некоторой последовательности, состоящей из букв К, Л, М, Н, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы Н использовали кодовое слово 0, для буквы К — кодовое слово 110. Какова наименьшая возможная суммарная длина всех четырёх кодовых слов?
1) 7
2) 8
3) 9
4) 10
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Решение:
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Легко заметить, что ближайшие от корня свободные листы (т.е. свободные коды с наименьшей длиной) – это 10 и 111. Таким образом, наименьшая возможная суммарная длина всех четырёх кодовых слов будет 1 + 3 + 2 + 3 = 9.
Правильный ответ указан под номером 3.
Ответ: 3
Задача 10
По каналу связи передаются сообщения, содержащие только четыре буквы: П, О, С, Т; для передачи используется двоичный код, допускающий однозначное декодирование. Для букв Т, О, П используются такие кодовые слова: Т: 111, О: 0, П: 100.
Укажите кратчайшее кодовое слово для буквы С, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Решение:
Для анализа соблюдения условия однозначного декодирования (условия Фано) изобразим коды в виде дерева. Тогда однозначность выполняется, если каждая буква является листом дерева:

Легко заметить, что ближайшие от корня свободные листы (т.е. свободные коды с наименьшей длиной) – это 101 и 110. Наименьшее числовое значение имеет код 101.
Ответ: 101
Благодарим за то, что пользуйтесь нашими материалами.
Информация на странице «6. Задание 4. Кодирование и декодирование информации» подготовлена нашими редакторами специально, чтобы помочь вам в освоении предмета и подготовке к экзаменам.
Чтобы успешно сдать необходимые и поступить в высшее учебное заведение или колледж нужно использовать все инструменты: учеба, контрольные, олимпиады, онлайн-лекции, видеоуроки, сборники заданий.
Также вы можете воспользоваться другими статьями из данного раздела.
Публикация обновлена:
07.03.2023
На этой странице вы узнаете
- Как закодировать сообщение “КУРЛЫК” правильно?
- Что такое равномерное кодирование?
- Так как кодировать сообщения максимально эффективно?
Понятие однозначного декодирования
Вы любите шпионов? А готовы почувствовать себя в их шкуре?
Нам нужно передать секретное сообщение на базу, а раз оно секретное, никто не должен понять, что мы передаем. Для этого надо представить наше сообщение в каком-то новом виде, который на первый взгляд будет бессмысленным, но мы будем знать, как его расшифровать.

Главное — чтобы расшифровать было возможно.
Мы уже знаем, что для компьютера информацию надо представить в двоичномкоде — подробнее об этом рассказано в статье «Основные понятия об информации». Но сам процесс кодирования информации — не такая простая вещь. Есть несколько факторов, которые нужно соблюсти, чтобы кодирование прошло хорошо.
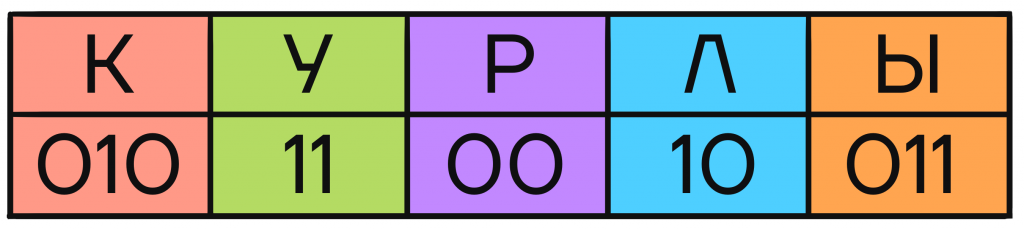
Но чтобы научиться делать что-то правильно, сначала надо разобраться, как сделать неправильно. Давайте попробуем произвольным образом закодировать буквы К, У, Р, Л, Ы, чтобы составлять из них сообщения.
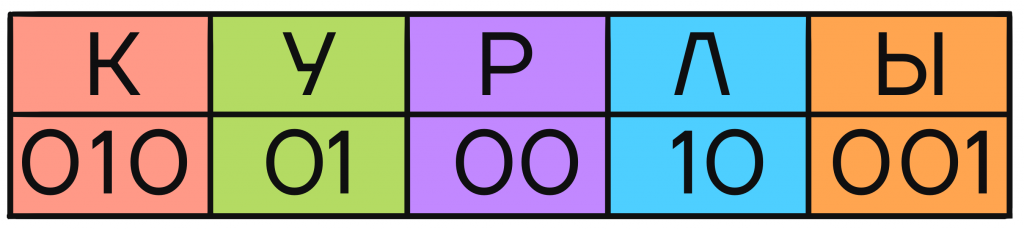
Каждой букве в табличке сопоставлено несколько символов, в нашем случае цифр. Эти символы — кодовое слово буквы, позволяющее отличить ее от других букв в закодированном сообщении.
С помощью кодовых слов каждой отдельной буквы закодируем сообщение КУРЛЫК, для этого на место каждой буквы будем подставлять соответствующее ей кодовое слово:

С проблемой мы столкнемся при попытке расшифровать сообщение. Чтобы это сделать, надо выделить в коде сообщения отдельные кодовые слова и подставить на их место соответствующие буквы. Но при расшифровке этого кода можно получить другой вариант:
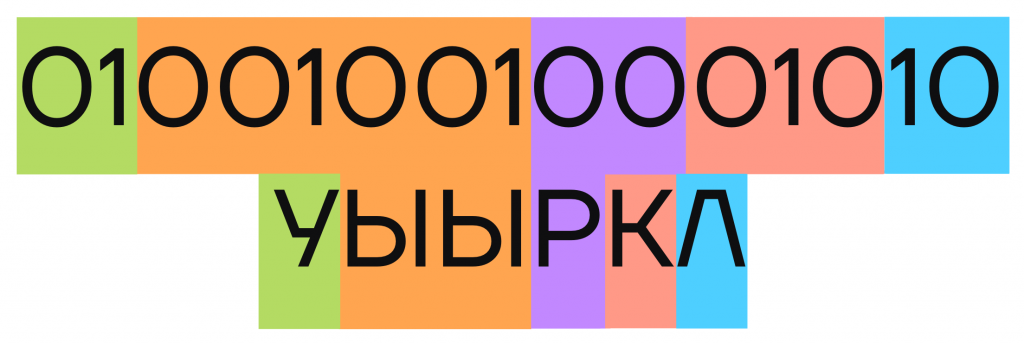
Чтобы кодирование считалось качественным и надежным, код должен удовлетворять условию однозначного декодирования — после кодирования сообщений у них должен быть единственный вариант расшифровки.
Равномерное кодирование
Но как можно соблюдать это условие? Или еще круче — как строить кодовые слова, которые заранее будут этому условию удовлетворять?
Это первый вариант подхода к однозначному декодированию.Он подразумевает кодирование отдельных элементов кодами, имеющими одинаковую длину.
И такой подход действительно спасает ситуацию. Если каждое кодовое слово будет иметь одинаковую длину, и при этом все они будут различны, выделять в зашифрованном сообщении отдельные кодовые слова не составит труда, как и сопоставлять их с соответствующими им буквами.
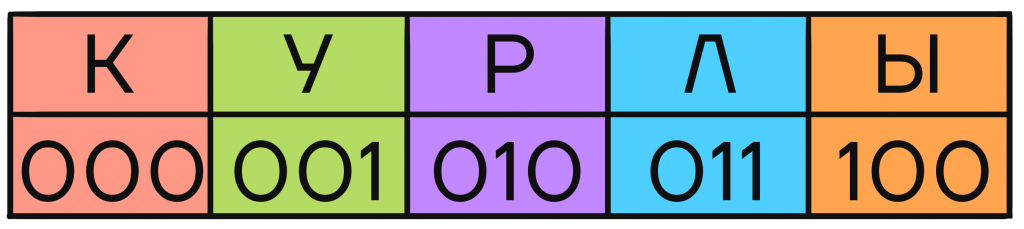
Кодируем сообщение КУРЛЫК:

И при попытке декодирования, поочередно выделяя кодовые слова одинаковой длины, мы не имеем никаких проблем с сопоставлением и получаем исходное сообщение без альтернативных вариантов.

Такой метод действительно прост и в освоении, и при составлении кодовых слов, и при расшифровке. Но есть один минус — он не всегда эффективен.
Выбирая длину одного кодового слова, мы можем заранее определить количество возможных кодов: так как на каждой позиции может быть либо 0, либо 1, количество возможных кодов N длины i будет равно
(N = 2^i).
Выбрав длину 3 для наших кодовых слов, мы имеем 8 различных кодов, хотя кодируем всего 5 букв.
В других ситуациях потери могут быть плачевнее: для кодирования, например, 33 букв русского алфавита длина кодового слова должна быть не меньше 6 (если выберем 5, получим максимум 25 = 32 кодового слова, но тогда 1 буква останется незакодированной).
Но имея 26 = 64 кодовых слова для 33-х букв алфавита, мы явно взяли кодов больше, чем нужно.
Почему это плохо? Рассмотрим следующую ситуацию.
Вася собирает вещи для переезда и ему надо упаковать какой-то набор вещей в коробку. Если в ней много свободного места — это плохо, потому что Вася может взять коробку поменьше и ему будет легче нести маленькую коробку. Также и здесь, если в нашей кодировке много неиспользованных кодов — это плохо, потому что можно оптимальнее перекодировать необходимый набор символов, и зашифрованные сообщения станут занимать меньше места на компьютере или быстрее передаваться по интернету.
Естественно, равномерное кодирование — все еще возможный вариант, при котором код будет однозначно декодируемым, но нет ли более рационального подхода?
Условие Фано и дерево вариантов
Хороший вариант — составление кодовых слов, которые удовлетворяют условию Фано.
Условие Фано гласит: «ни одно кодовое слово не должно быть началом другого кодового слова».
В составленных нами в самом начале статьи кодовых словах это условие нарушалось — код буквы К (010) начинался с кода буквы У (01), а код Ы (001) — с кода Р (00). Из-за этого мы не могли быть точно уверены, где закончилось кодовое слово, а где оно продолжается.
Очень просто строить код, который будет удовлетворять условию Фано, с помощью дерева вариантов — структуры, в нашем случае помогающей получить кодовые слова максимально просто и понятно. Принцип работы дерева состоит в том, что в его узлах будут находиться кодовые слова, а из узла могут выходить два ребра, соответствующие добавлению в конец кодового слова 0 и 1, таким образом заменяя одно кодовое слово на два новых, которые длиннее на один символ.
1. Начальный узел — пустой.
2. К любому узлу могут быть добавлены ребра, создающие два новых узла, в каждом из которых находится новое кодовое слово на 1 символ длиннее предыдущего (с добавленным в конец символом 0 и 1, соответственно).
3. Шаг 2 выполняется до тех пор, пока не будет получено необходимое количество конечных узлов (самых последних, из которых не выходит ни одного ребра).
Давайте попробуем таким образом получить ровно 5 кодовых слов, чтобы закодировать наши буквы К, У, Р, Л, Ы.
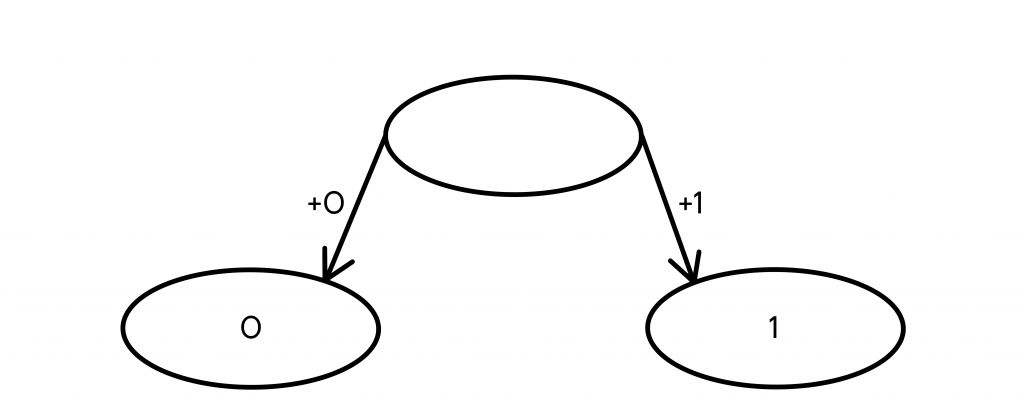
- Первые два кодовых слова, которые мы можем получить из ничего — 0 и 1.
Чтобы продолжить построение дерева, выбираем любой из конечных узлов и также добавляем ему 0 и 1 в конец.
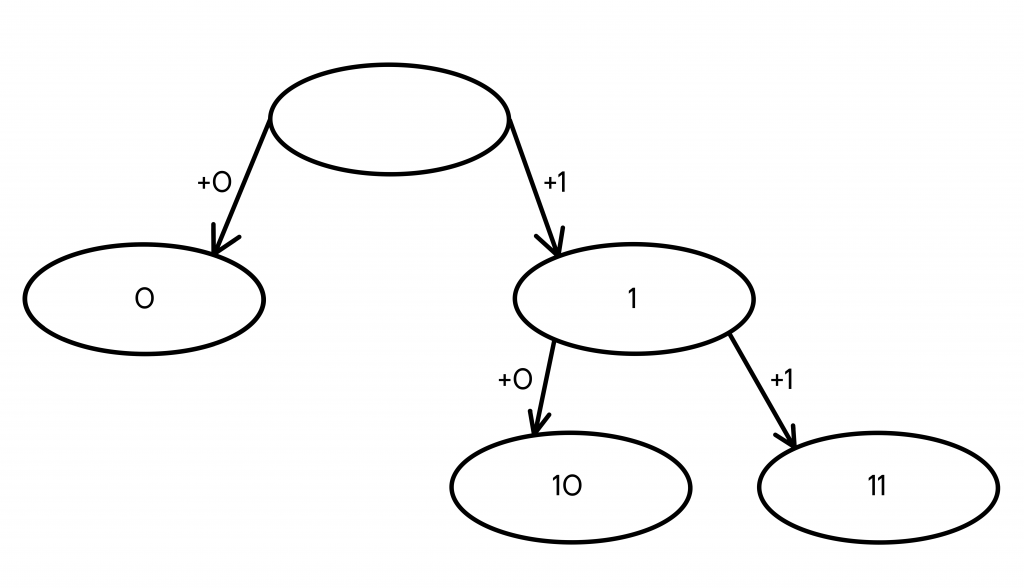
- Допустим, мы добавим 0 и 1 к кодовому слову 1, и вместо него теперь получим два новых — 10 и 11. Теперь кодовых слов у нас уже три — 0, 10 и 11.
Все еще мало, продолжаем построение дерева.
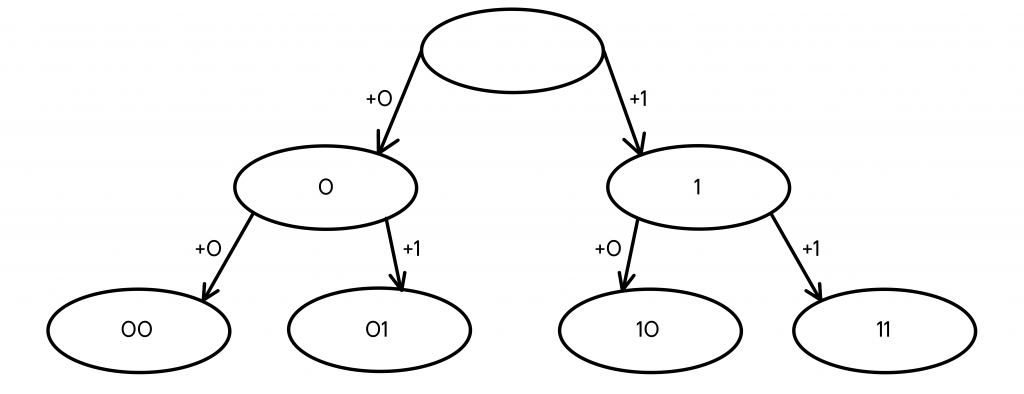
- Мы проделали ту же операцию с кодовым словом 0, заменив его на 2 новых — 00 и 01.
Кодовых слов стало 4, этого все еще мало, нужно продолжить построение дерева.
- Из конечных узлов можно выбрать любой для продолжения построения, например — 01, продолжив это кодовое слово, получаем два новых — 010 и 011.
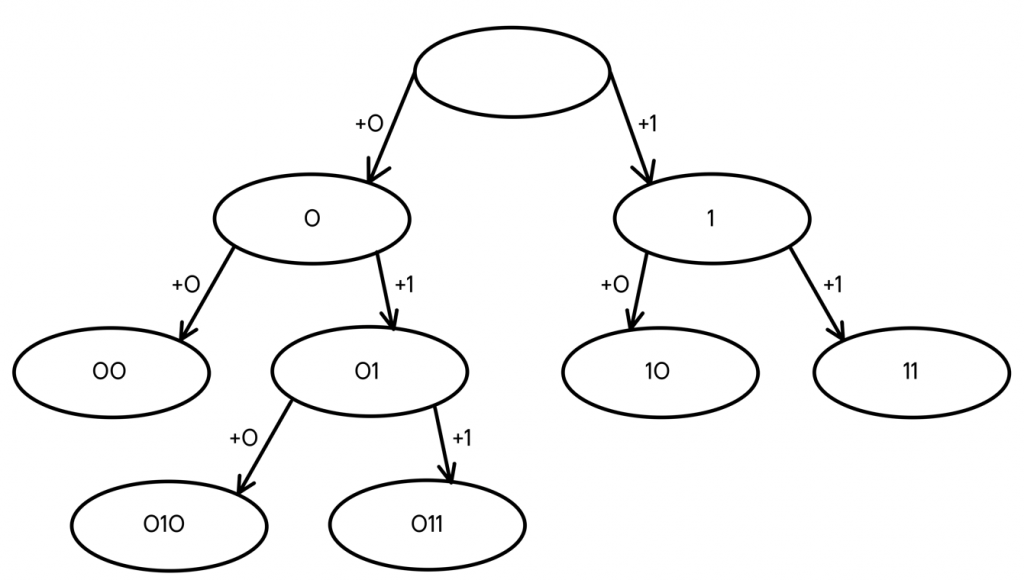
В итоге мы имеем 5 конечных узлов В них находятся кодовые слова, которые можно распределить любым удобным или необходимым способом между кодируемыми буквами. Например, так:
Такой код будет однозначно декодируемым, так как ни одно слово не заканчивается посередине другого, и мы всегда можем быть уверены, что одно кодовое слово закончилось и началось новое.
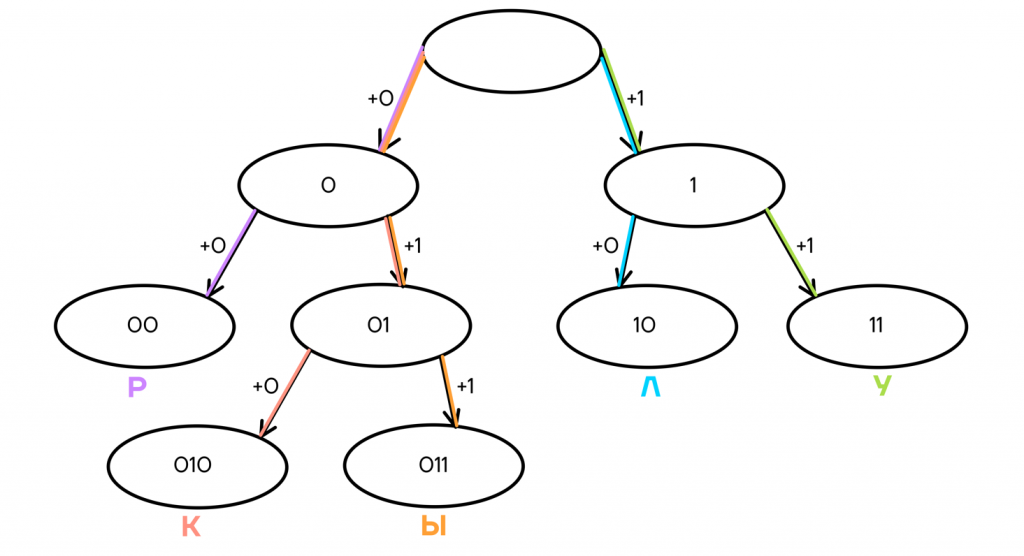
Так, код 010110010011010 мы можем однозначно декодировать, читая его слева направо:
Его формулировка немного отличается: «ни одно кодовое слово не должно быть окончанием другого». Такая формулировка уже допустит сосуществование кодовых слов 011 и 01, но не допустит 110 и 10, так как второе совпадает с окончанием первого.
Здесь построение дерева вариантов и чтение кодов происходит в точности до наоборот — при построении мы добавляем символы не в конец, а в начало предыдущего кодового слова и читаем код справа налево.
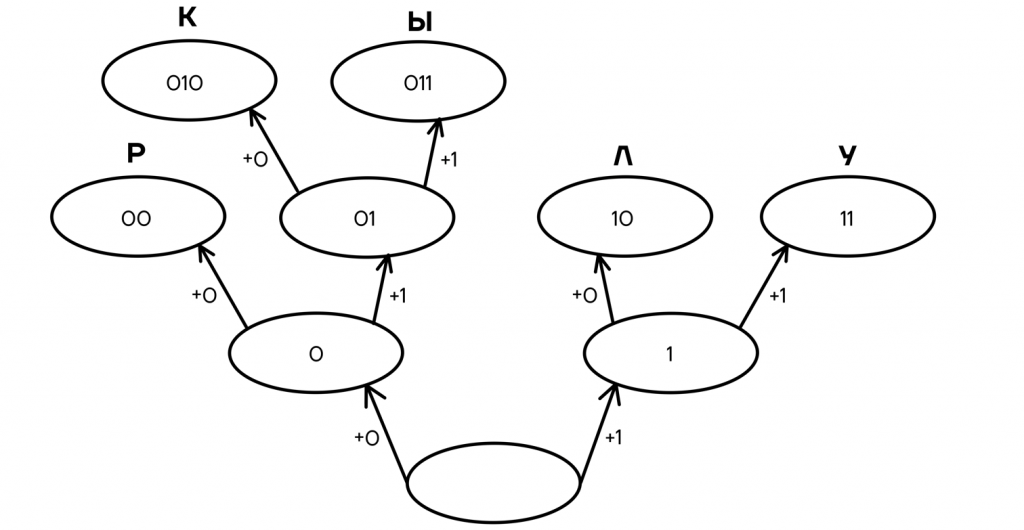
И код 010110001110010 будет читаться уже в другую сторону – из конца в начало:
![]()
Практика
В жизни чаще всего используются равномерные кодировки в силу многих причин, таких как:
- Большая устойчивость.
Представим, что мы передаем слово КУРЛЫК разными вариантами, но при передаче допускаем ошибку в четвертом бите (в четвертом символе нашего кода). Посмотрим, что получится в итоге.

Выводы:
- В первом случае из-за одного неправильного бита сломалась половина символов текста, и даже поменялось количество этих символов.
- Во втором случае текст отличается от первоначального только тем символом, на который влиял сломанный бит.
Таким образом, мы видим большую устойчивость равномерного кодирования.
2. Простота расширения.
Мы обсуждали, что проблема равномерного кодирования — в большом количестве «пустых мест». Но эти пустые места могут быть полезны. Например, захочет разработчик добавить в код несколько новых эмодзи. У него как раз есть незанятые коды для этих символов. Согласитесь, это удобнее, чем переписывать всю кодировку целиком.
Неравномерные же кодировки часто применялись еще до появления компьютеров. Например, одной из самых известных неравномерных кодировок являлась азбука Морзе, применявшаяся в работе телеграфов, передаче радиосигналов и других способах передачи информации.
Также применение неравномерной кодировки есть в 4 задаче ЕГЭ и во 2 задаче ОГЭ.
Разберем задачу №4 ЕГЭ:
По каналу связи передаются закодированные сообщения о состоянии системы, состоящие из пяти символов: A, B, C, D, E. При передаче сообщений используется двоичный код, при этом он допускает однозначное декодирование. Для символов A, B, C используются эти кодовые слова: 1, 010 и 001 (соответственно).
В ответе нужно указать наименьшее по длине кодовое слово для буквы D. Если таких кодов несколько, то в ответе укажите наименьший по значению.
Решение.
Шаг 1. Построим дерево вариантов кодовых слов и отметим на нем уже известные коды букв:
Шаг 2. Заметим, что раз для символа A кодовое слово 1, то в дальнейшем нам не подойдут любые коды, начинающиеся с 1, так как для них и символа A не будет выполняться условие однозначного декодирования.
Шаг 3. Начнем разбирать по возрастанию кодовые слова, начинающиеся с 0:
- 0 — не подойдет, будет началом для кодовых слов 001 и 010.
- 00 — не подойдет, будет началом слова 001.
- 01 — не подойдет, будет началом слова 010.
- 000 — подойдет.
- 001 — не подойдет, буква C.
- 010 — не подойдет, буква B.
- 011 — подойдет.
Шаг 4. Получаем два недостающих кодовых слова равной длины: 000 и 011. Значит, можем использовать их для букв Е и D, при этом сохранив однозначное декодирование. Для D нужно слово, меньшее по значению, тогда верным ответом будет 000.
Ответ: 000
В этой статье мы познакомились с условием Фано и научились правильно кодировать и декодировать сообщения. Но различные виды информации требуют собственных уникальных подходов. Приглашаем вас продолжить изучение темы в статьях «Кодирование изображения» и «Кодирование звука».
Фактчек
- Условие однозначного декодирования необходимо для того, чтобы у закодированного сообщения был ровно один вариант расшифровки — исходный.
- Однозначное декодирование может давать равномерное кодирование, при котором все кодовые слова имеют одинаковую длину, или кодовые слова, составленные по условию Фано, которое гласит: «ни одно кодовое слово не должно совпадать с началом другого кодового слова».
- Существует другая вариация этого условия — обратное условие Фано, оно гласит: «ни одно кодовое слово не должно совпадать с окончанием другого кодового слова».
- Для составления кодовых слов, удовлетворяющих условию Фано, используется дерево вариантов.
Проверь себя
Задание 1.
Для чего необходимо условие однозначного декодирования?
- Для более удобной шифровки сообщений.
- Для построения минимально возможных кодовых слов.
- Для сохранения возможности абсолютно точно получить исходное сообщение из закодированного.
- Для красоты.
Задание 2.
Выберите верные утверждения:
- При равномерном кодировании все кодовые слова имеют одну длину.
- При равномерном кодировании кодовые слова не могут начинаться на один и тот же символ.
- Для соблюдения условия Фано необходимо, чтобы ни одно кодовое слово не совпадало с окончанием другого кодового слова.
- Обратное условие Фано не гарантирует однозначное декодирование.
- Для составления кодовых слов, удовлетворяющих обратному условию Фано, используется дерево вариантов.
Задание 3.
Выберите наборы кодовых слов, которые удовлетворяют условию однозначного декодирования по любому из критериев, описанных в статье:
- 1, 11, 111, 1111, 11111, 0.
- 01, 001, 0001, 00001, 1
- 000, 111, 100, 001
- 10, 11, 00, 1001
- 10, 100, 1000, 10000
Задание 4.
Для передачи сообщений используются буквы А, Б, В, Г, Д. Известны некоторые кодовые слова: А = 01, Б = 111, В = 00, Г = 110. Какое кодовое слово может соответствовать кодовому слову для буквы Д, чтобы весь код удовлетворял условию Фано?
- 0
- 11
- 101
- 1100
Ответы: 1. — 3; 2. — 1, 5; 3. — 2, 3, 4, 5; 4. — 3.
ЕГЭ – 2021, задание 4. Кодирование и декодирование информации
Для передачи, обработки и хранения информации необходимо ее зафиксировать с помощью определенной знаковой системы (алфавита), т. е. закодировать.
Кодирование – это процесс представления информации в виде последовательности условных обозначений. Декодирование – это процесс, обратный кодированию.
Кодирование информации всегда происходит по определенным правилам. Правило кодирования называется кодом.
Последовательность символов известной длины из конечного набора знаков (алфавита) используемых для кодирования, называется кодовым словом (например, кодовое слово для буквы «O» в азбуке Морзе имеет длину равную трем и представляет последовательность из трех символов тире «— — —»).
Способы кодирования информации зависят от конкретной задачи.
Для решения таких задач полезно знать и использовать условия Фано, выполнение которых служит достаточными для однозначного декодирования заданного сообщения, то есть перебора различных вариантов при декодировании не потребуется. Это позволяет избежать ошибок и сэкономить время для решения задачи.
Прямое условие Фано гласит, что ни одно кодовое слово не может служить началом другого кодового слова.
Обратное условие Фано гласит, что ни одно кодовое слово не может служить концом другого кодового слова.
Например, в кодовых словах 01, 011, 010, 110, 100 нарушено прямое условие Фано, так как кодовое слово 01 является началом кодового слова 011. Обратное условие не нарушено, поэтому задачу по раскодированию с такими кодовыми словами рекомендуется решать с конца сообщения, что обеспечит его однозначное декодирование.
В кодовых словах 01, 001, 100, 101, 110 нарушено обратное условие Фано, так как кодовое слово 01 является концом кодовых слов 001 и 101. Прямое условие не нарушено, поэтому задачу с такими заданными кодовыми словами для однозначного декодирования рекомендуется решать с начала сообщения.
В кодовых словах 01, 001, 010, 100, 110 нарушены оба условия Фано, так как кодовое слово 01 служит началом кодового слова 010 и концом кодового слова 001. Тогда при решении такой задачи однозначное декодирование невозможно, решать можно с любой стороны – все равно придется перебирать варианты.
Один символ исходного сообщения может заменяться одним символом нового кода или несколькими символами, а может быть и наоборот – несколько символов исходного сообщения заменяются одним символом в новом коде (китайские иероглифы обозначают целые слова и понятия)
Кодирование может быть равномерное и неравномерное;
-
при равномерном кодировании все символы кодируются кодами равной длины;
-
при неравномерном кодировании разные символы могут кодироваться кодами разной длины, это затрудняет декодирование
При решении задач по декодированию достаточно умения логически мыслить и строить кодовые деревья, быть внимательным и аккуратным – и все получится!
ПРИМЕРЫ РЕШЕНИЯ ЗАДАЧ
Задача 1 (демо-2021)
Для кодирования некоторой последовательности, состоящей из букв Л, М, Н, П, Р, решили использовать неравномерный двоичный код, удовлетворяющий условию, что никакое кодовое слово не является началом другого кодового слова. Это условие обеспечивает возможность однозначной расшифровки закодированных сообщений. Для букв Л, М, Н использовали соответственно кодовые слова 00, 01, 11. Для двух оставшихся букв – П и Р – кодовые слова неизвестны. Укажите кратчайшее возможное кодовое слово для буквы П, при котором код будет удовлетворять указанному условию. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Решение.
При решении задачи нужно учесть, что хотя в ответе нужно привести код одной буквы П, но неизвестными по условию остаются два кодовых слова — для букв П и Р, поэтому в данной задаче ищем два доступных кодовых слова, а в ответе выбираем из них код с меньшим числовым значением. При этом из двух бит можно построить всего 4 кода, а нам задано пять букв, то есть искомый код должен быть трехзначным. Из двузначных кодов не занят код 10, тогда из него можно построить два трехзначных кода, не нарушающих условие Фано – 100 и 101. Тогда ответом будет меньшее число – 100.
Самое наглядное решение таких задач — это построение кодовых деревьев, хотя можно обойтись и записью последовательно получаемых кодов или простыми рассуждениями. В данном случае мы так и поступили.
Ответ: 100
Задача 2.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для букв А, Б, В, Г использовали соответственно кодовые слова 000, 001, 10, 11. Укажите кратчайшее возможное кодовое слово для буквы Д, при котором код будет допускать однозначное декодирование. Если таких кодов несколько, укажите код с наименьшим числовым значением.
Решение.
При решении задачи нужно учесть, что хотя в ответе нужно привести код одной буквы Д, но неизвестными по условию остаются два кодовых слова — для букв Д и Е, поэтому в данной задаче ищем два доступных кодовых слова, а в ответе выбираем из них код с меньшим числовым значением. При этом здесь используется неравномерное кодирование, причем условия Фано не нарушены. Из двузначных кодов свободны 00 и 01, при этом 00 нарушает и начало, и конец, поэтому использоваться не может. Тогда остается только один двузначный код – 10 и возможность использовать трехзначные коды: 010, 011, 100, 101, 110. Выбираем из них наименьшее число – 010.
Ответ: 010
Задача 3.
По каналу связи с помощью равномерного двоичного кода передаются сообщения, содержащие только 4 буквы: X, Y, Z, W; для кодировки букв используются кодовые слова длины 5. При этом для набора кодовых слов выполнено такое свойство: любые два слова из набора отличаются не менее чем в трёх позициях. Это свойство важно для расшифровки сообщений при наличии помех. Для кодирования букв X, Y, Z используются 5-битовые кодовые слова: X: 01111, Y: 00001, Z: 11000. Определите 5-битовое кодовое слово для буквы W, если известно, что оно начинается с 1 и заканчивается 0.
Решение.
Из заданного условия имеем один код буквы Z в требуемом диапазоне – 11000. Тогда для получения кода, который отличается тремя позициями (две остаются на месте, и больше трех их отличий быть не может) достаточно поменять оставшиеся три бита на противоположные, получим код 10110. При этом отличия с заданными буквами: Х – 3, Y – 4.
Ответ: 10110
Задача 4.
Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г, Д, Е, решили использовать неравномерный двоичный код, удовлетворяющий условию Фано. Для буквы А использовали кодовое слово 0; для буквы Б – кодовое слово 10. Какова наименьшая возможная сумма длин всех шести кодовых слов?
Примечание. Условие Фано означает, что никакое кодовое слово не является началом другого кодового слова. Это обеспечивает возможность однозначной расшифровки закодированных сообщений.
Решение.
В двух заданных кодах нарушено обратное условие Фано, поэтому будем составлять коды, не нарушая начала. Запишем подряд все возможные коды и вычеркнем из них не подходящие нам, получим: 11, 100, 101, 110, 111, 1000, 1001, 1010, 1011, 1100, 1101, 1110, 1111. Тогда здесь подходят только четыре последних кода, и сумма длин всех шести кодов будет равна 1 + 2 + 4 *4 = 19.
Ответ: 19
Задача 5.
По каналу связи передаются сообщения, каждое из которых содержит 16 букв А, 8 букв Б, 4 буквы В и 4 буквы Г (других букв в сообщениях нет). Каждую букву кодируют двоичной последовательностью. При выборе кода учитывались два требования:
а) ни одно кодовое слово не является началом другого (это нужно, чтобы код допускал однозначное декодирование);
б) общая длина закодированного сообщения должна быть как можно меньше.
Какой код из приведённых ниже следует выбрать для кодирования букв А, Б, В и Г?
1) А:0, Б:10, В:110, Г:111
2) А:0, Б:10, В:01, Г:11
3) А:1, Б:01, В:011, Г:001
4) А:00, Б:01, В:10, Г:11
Решение.
Варианты ответов 2 и 3 отпадают, так как в них нарушено заданное условие Фано (буквы А:0, В:01 и Б:01, В:011 соответственно).
В варианте 1 получаем последовательность длиной 16*1 + 8*2 + 4*3 + 4*3 = 56 бит,
в варианте 4 – (16 + 8 + 4*2) * 2 = 64 бита, тогда верный ответ – 1.
Ответ: 1
Задача 6.
В любом сообщении больше всего букв А, следующая по частоте буква – С, затем – И. Буква Т встречается реже, чем любая другая. Для передачи сообщений нужно использовать неравномерный двоичный код, допускающий однозначное декодирование; при этом сообщения должны быть как можно короче. Шифровальщик может использовать один из перечисленных ниже кодов. Какой код ему следует выбрать?
1) А – 0, И – 1, С – 00, Т – 11 2) С – 1, И – 0, А – 01, Т – 10
3) А – 1, И – 01, С – 001, Т – 000 4) С – 0, И – 11, А – 101, Т – 100
Решение.
Варианты ответов 1 и 2 отпадают, так как в них нарушены оба условия Фано.
Из первого условия задачи о частоте встречающихся букв подходит вариант 3.
Ответ: 3
Задача 7.
Для 5 букв латинского алфавита заданы их двоичные коды (для некоторых букв – из двух бит, для некоторых – из трех). Эти коды представлены в таблице:
|
A |
B |
C |
D |
E |
|
000 |
01 |
100 |
10 |
011 |
Определить, какой набор букв закодирован двоичной строкой 0110100011000.
Решение.
Из таблицы видим, что нарушено начало кодов (буквы В и Е, с и D), тогда декодирование строки следует начинать с конца. Однозначно получаем:
01 10 100 011 000 — ВDСЕА
Ответ: ВDСЕА
Задача 7.
Для передачи чисел по каналу с помехами используется код проверки четности. Каждая его цифра записывается в двоичном представлении, с добавлением ведущих нулей до длины 4, и к получившейся последовательности дописывается сумма её элементов по модулю 2 (например, если передаём 23, то получим последовательность 0010100110).
Определите, какое число передавалось по каналу в виде 01010100100111100011.
Решение.
Разобьем заданную последовательность по 5 бит, удалим каждый пятый бит и получим последовательность
01010100100111100011 = 01010 10010 01111 00011
что соответствует цифрам 5, 9, 7 и 1.
Ответ: 5971
Слайд 1
Однозначное декодирование Прямое и обратное условие Фано Учитель информатики и ИКТ МБОУ СОШ № 7 г. Оха Сахалинской области Сергиенко Татьяна Геннадьевна
Слайд 2
Задача 1 Пусть для кодирования фразы «Доброе утро» выбран такой код: Д О Б Р Е У Т Пробел 111 000 00 1 01 0 10 11
Слайд 3
Коды букв «сцепляются» в единую битовую строку и передаются, например, по сети: Доброе утро→ 11100000100001110101000 В пункте назначения возникает проблема – как восстановить исходное сообщение, и возможно ли это.
Слайд 4
11100000100001110101000 Раскодировать данное сообщение можно разными способами. В том числе предположим, что оно состоит только из букв Р – 1 и У – 0. Тогда получим РРРУУУУУРУУУУРРРУРУРУУУ, т.е. бессмысленный набор букв .
Слайд 5
Код называется однозначно декодируемым , если любое кодовое сообщение можно расшифровать единственным способом (однозначно ).
Слайд 6
Значит, код не является однозначно декодируемым.
Слайд 7
Задача 2 Равномерные коды. Для той же фразы используем равномерный код: Д О Б Р Е У Т Пробел 111 000 001 101 011 010 100 110
Слайд 8
Равномерные коды неэкономичны – гораздо длиннее неравномерных. Это приводит к усложнению кодирования, но при этом они раскодируются однозначно, что, естественно, облегчает задачу.
Слайд 9
Задача 3 Чтобы сократить длину сообщения, можно попробовать применить неравномерный код, т.е. код, в котором кодовые слова, соответствующие разным символам исходного алфавита, могут иметь разную длину, от одного до нескольких символов.
Слайд 10
Используем следующий код: 0100101110000101011111101111010000 Эта битовая цепочка декодируется однозначно. Д О Б Р Е У Т Пробел 01 00 1011 100 1010 1101 1110 1111
Слайд 11
Первая буква — Д (код 01), т.к. ни одно другое кодовое слово не начинается с 01. Вторая буква – О (код 00). Никакое другое слово не начинается с 00. Это же свойство, которое называется условием Фано , выполняется и для кодовых слов других букв.
Слайд 12
УСЛОВИЕ ФАНО Никакое кодовое слово не совпадает с началом другого кодового слова. Такие коды называются префиксными (раскодируются с начала сообщения) и декодируются однозначно.
Слайд 13
Задача 4 Рассмотрим ещё один код: Он не является префиксным, т.к. код буквы Д (10 ) совпадает с началом кода буквы Б (1011), У(1000) и код буквы О(00) совпадает с началом кода буквы Р (001 ). Д О Б Р Е У Т Пробел 10 00 1011 001 0101 1000 0111 1111
Слайд 14
Закодируем наше сообщение: ДОБРОЕ УТРО→ 10 00 1011 001 00 0101 1111 1000 0111 001 00 Начнём раскодировать с начала. Первая – Д, или У, а дальше идут вообще разные варианты : Р или Б… Т.е. надо «заглядывать» вперёд, что очень неудобно.
Слайд 15
Попробуем раскодировать сообщение с конца – оно однозначно декодируется! Выполняется обратное условие Фано : никакое кодовое слово не совпадает с окончанием другого кодового слова.
Слайд 16
Коды , для которых выполняется обратное условие Фано , называются постфиксными.
Слайд 17
Сделаем вывод: Сообщение декодируется однозначно, если для используемого кода выполняется прямое или обратное условие Фано .
Слайд 18
Условие Фано — это достаточное, но не необходимое условие однозначной декодируемости Это значит, что: — для однозначной декодируемости достаточно выполнения хотя бы одного из двух условий — прямого или обратного. — могут существовать коды, для которых не выполняется ни прямое, ни обратное условие Фано , но тем не менее обеспечивается однозначное декодирование, т.к. иначе теряется смысл выражения.
Слайд 19
Задача 5 Для кодирования некоторой последовательности, состоящей из букв А, Б, В, Г и Д используется неравномерный двоичный код, позволяющий однозначно декодировать полученную двоичную последовательность. Вот этот код: А – 00, Б – 01, В – 100, Г – 101, Д – 110.
Слайд 20
Можно ли сократить для одной из букв длину кодового слова так, чтобы код по-прежнему можно было декодировать однозначно? Коды остальных букв меняться не должны. Выберите правильный вариант ответа: 1) для буквы Д -11 2) это невозможно 3) для буквы Г — 10 4) для буквы Д -10
Слайд 21
РЕШЕНИЕ: Исходный код – префиксный. Для него выполняется условие Фано – ни один из трёхбитных кодов не начинается ни с 00 (А), ни с 01 (Б). (При этом обратное условие Фано не выполняется – код А (00) совпадает с окончанием В (100), а код Б (01) совпадает с окончанием Г (101 ).)
Слайд 22
Теперь проверим ответы. Сократим Д до 11. Если полученный код нарушит прямое условие Фано , то свойство однозначного декодирования будет нарушено. Но этого не произошло, нет других кодов, начинающихся с 11. Это и есть верное решение. Проверим остальные варианты.
Слайд 23
Вариант 2 сразу не рассматриваем – ответ у нас найден. Вариант 3 нарушает прямое условие Фано – с 10 начинается код буквы В (101). Вариант 4 – так же нарушает прямое условие Фано . Т.е. ответ однозначный, других вариантов нет.
Слайд 24
Спасибо за внимание!