Задания
Версия для печати и копирования в MS Word
Задания Д1 № 622 
Ученик набирает сочинение по литературе на компьютере, используя кодировку KOI-8. Определите какой объём памяти займёт следующая фраза:
Пушкин — это наше всё!
Каждый символ в кодировке KOI-8 занимает 8 бит памяти.
1) 22 бита
2) 88 байт
3) 44 байт
4) 176 бит
Спрятать решение
Решение.
Каждый символ кодируется 8 битами. Всего символов 22, включая пробелы. Следовательно, ответ 176 бит.
Правильный ответ указан под номером 4.
Спрятать решение
·
·
Сообщить об ошибке · Помощь
![]()
Ученик набирает сочинение по литературе на компьютере, используя кодировку KOI-8. Каждый символ в кодировке KOI-8 занимает 8 бит памяти. Определите какой объём памяти в байтах займёт следующая фраза:
Пушкин — это наше всё!
поделиться знаниями или
запомнить страничку
- Все категории
-
экономические
43,623 -
гуманитарные
33,648 -
юридические
17,917 -
школьный раздел
611,572 -
разное
16,897
Популярное на сайте:
Как быстро выучить стихотворение наизусть? Запоминание стихов является стандартным заданием во многих школах.
Как научится читать по диагонали? Скорость чтения зависит от скорости восприятия каждого отдельного слова в тексте.
Как быстро и эффективно исправить почерк? Люди часто предполагают, что каллиграфия и почерк являются синонимами, но это не так.
Как научится говорить грамотно и правильно? Общение на хорошем, уверенном и естественном русском языке является достижимой целью.
Ученик набирает сочинение по литературе на компьютере, используя кодировку KOI-8. Определите какой объём памяти в байтах займёт следующая фраза:
Каждый символ в кодировке KOI-8 занимает 8 бит памяти.
Ответ:
![]()
1) 22 бита
2) 88 байт
3) 44 байт
4) 176 бит
Пояснение.
Каждый символ кодируется 8 битами. Всего символов 22, включая пробелы. Следовательно, ответ 176 бит.
Правильный ответ указан под номером 4.
![]()
![]()
![]()
![]()
![]()
var a:array [1..15] of integer;
for i:=1 to 15 do a[i]:=i*2;
var a:array [1..10] of integer;
writeln (‘Введите 10 элементов массива через пробел.Потом нажмите Enter.’);
for i:=1 to 10 do read(a[i]);
write (‘Элементы с нечётными индексами: ‘);
for i:=1 to 10 do if i mod 2 <> 0 then write (a[i],’ ‘);
write (‘Элементы с чётными индексами: ‘);
for i:=1 to 10 do if i mod 2 = 0 then write (a[i],’ ‘)
Источник
-
- 0
-
Ученик набирает сочинение по литературе на компьютере, используя кодировку KOI-8. Определите какой объём памяти займёт следующая фраза:
Молекулы состоят из атомов!
-
Комментариев (0)
-
- 0
-
Дано: Решение:
k=27
i=8 бит = 1 байт I=K*I=27*1=27 байт
————————-
Найти I ?
Ответ: 27 байт или 216 бит
-
Комментариев (0)
Ученик набирает сочинение по литературе ** компьютере, используя кодировку…
0 голосов
Ученик набирает сочинение по литературе на компьютере, используя кодировку KOI-8. Определите какой объём памяти займёт следующая фраза: Молекулы состоят из атомов! Каждый символ в кодировке KOI-8 занимает 8 бит памяти. 1) 27 бит 2) 108 бит 3) 26 байт 4) 216 бит
![]()
спросил
19 Май, 20
от
Qween3883_zn
(45 баллов)
в категории Информатика
1 Ответ
0 голосов
![]()
ответил
19 Май, 20
от
yamochkaxyyamochka_zn
(44 баллов)
«Молекулы состоят из атомов!» — 27 символов, включая пробелы.
27 * 8 бит = 216 бит = 27 байт.
Похожие вопросы
- как называется простая геометрическая фигура для построения которой в графическом…
- Укажите наибольшее четырёхзначное шестнадцатеричное число, двоичная запись которого…
- Укажите наибольшее четырёхзначное шестнадцатеричное число, двоичная запись которого…
- Как нарисовать флаг Лаоса в Паскаль? помогите пожалуйста
- Как нарисовать флаг Лаоса в Паскаль? помогите пожалуйста
…
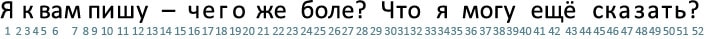
Цифровое искусство: музыка и IT
Способен ли искусственный интеллект сочинять музыку? Как работают современные музыкальные сервисы? Как алгоритмы рекомендуют? Может ли компьютер понимать музыку? Ответы на эти и другие вопросы узнай в этом уроке!
В IT-лабораториях по всему миру ведутся разработки искусственного интеллекта для самых разных сфер жизни, в том числе для работы с большими объемами данных. Например, с музыкой.
Главная сложность в том, что компьютер должен услышать песню, узнать её и предложить другие, исходя из твоих музыкальных интересов в режиме реального времени, то есть в течении нескольких секунд. А значит, простые алгоритмы уже давно ушли в прошлое, уступая место самым прогрессивным и интересным решениям. И, как продолжение IT-инноваций в музыке, — это самостоятельное «сочинение». Но как запрограммировать творчество?
На уроке вы познакомитесь со специалистом IT-лаборатории и группой стажеров, задача которых — научить Робота слышать песни и узнавать их, а на основе полученных данных находить для пользователей те музыкальные композиции, которые им, скорее всего, понравятся.
А самым увлеченным доступен бонус — понять, как искусственный интеллект генерирует музыку, и испытать свои силы в сочинении небольшой мелодии.
РЕШЕНИЕ
Перед решением данной задачи ОГЭ по информатике, разберем коротко, как кодируется текст.
Для того чтобы в компьютере можно было хранить текстовые данные, необходимо предварительно закодировать все символы, которые могут использоваться в тексте. Текст может содержать цифры, прописные и строчные буквы, пробелы, знаки препинания и специальные символы (например, +, =, *, $). Если буквы, входящие в текст, могут быть только латинскими или русскими, то для кодирования одного символа достаточно использовать 8 битовых ячеек памяти, т. е. 1 байт памяти 2^8 = 256 различных символов.
В задаче необходимо посчитать общее количество символов, включая пробелы и знаки препинания. Перед и после знака тире тоже стоит пробел.
![]()
Всего получилось 52 символа. Каждый символ кодируется 16 битами, поэтому умножаем:
52 * 16 = 832 бита.
В варианте ответа, такое число находится по номером 2. Это и будет ответом в нашей задаче. Обратите внимание, что в некоторых задачах, данного варианта ответа может и не быть. Например, вместо 832 бит стоит число 104 байт. Нужно помнить, что 1 байт = 8 бит. Делим число 832 / 8 = 104 байта.
ASCII как первый стандарт кодирования информации
Телетайп и терминал
Параллельно с этим развивались телетайпы. Телетайп — это система передачи текстовой информации на расстоянии. Два принтера и две клавиатуры (на самом деле электромеханические печатные машинки) попарно соединялись друг с другом проводами. Текст, набранный на клавиатуре у первого пользователя, печатается на принтере у второго пользователя и наоборот. Таким образом, например, была организована «горячая линия» между президентом США и руководством СССР вплоть до начала 1970-х годов.
Телетайпы также преобразуют текстовую информацию в некоторые сигналы, которые передаются по проводам. При этом не всегда используется бинарный код, например, в азбуке Морзе используются 3 символа — точка, тире и пауза. Для телетайпов необходимы таблицы символов, соответствие в которых строится между символами и сигналами в проводах. При этом для каждого телетайпа (пары, соединённых телетайпов) таблицы символов могли быть свои, исходя из задач, которые они решали. Отличаться, например, мог язык, а значит и сам набор символов, который отправлялся с помощью устройства. Для оптимизации работы телетайпа самые популярные (часто встречающиеся) символы кодировались наиболее коротким набором сигналов, а значит и в рамках одного языка, набор символов мог быть разным.
На основе телетайпов разработали терминалы доступа к компьютерам. Такой телетайп отправлял сообщения не второму пользователю, а информация вводилась на некоторый удалённый компьютер, который после обработки указанных команд, возвращал результат в виде ответного сообщения. Это нововведение позволило использовать тогда ещё очень дорогие вычислительные мощности компьютеров, не имея физического доступа к самому компьютеру. Например, компьютер мог размещаться в отдельном вычислительном центре корпорации или института, а сотрудники из других филиалов или городов получали доступ к вычислительным мощностями компьютера посредством установленных у них терминалов.
ASCII
Повсеместное распространение компьютеров и средств обмена текстовой информацией потребовало разработки единого стандарта кодирования для передачи и хранения информации. Такой стандарт разработали в США в 1963 году. Таблицу из 128 символов назвали ASCII — American standard code for information interchange (Американский стандарт кодов для обмена информацией).
Первые 32 символа в ASCII являются управляющими. Они использовались для того, чтобы, например, управлять печатающим устройством телетайпа и получать некоторые составные символы. Например:
- символ Ø можно было получить так: печатаем O, затем с помощью управляющего кода BS (BackSpace) передвигаем печатную головку на один символ назад и печатаем символ /,
- символ à получался как a BS `
- символ Ç получался как C BS ,
Введение управляющих символов позволяло получать новые символы как комбинацию существующих, не вводя дополнительные таблицы символов.
Однако введение стандарта ASCII решило вопрос только в англоговорящих странах. В странах с другой письменностью, например, с кириллической в СССР, проблема оставалась.
Кодировки для других языков
В течение более чем 20 лет вопрос решали введением собственных локальных стандартов, например, в СССР на основе таблицы ASCII разработали собственные варианты кодировок КОИ 7 и КОИ 8, где 7 и 8 указывают на количество бит, необходимых для кодирования одного символа, а КОИ расшифровывается как Коды Обмена Информацией.
С дальнейшим развитием систем начали использовать восьмибитные кодировки. Это позволило использовать наборы, содержащие по 256 символов. Достаточно распространён был подход, при котором первые 128 символов брали из стандарта ASCII, а оставшиеся 128 дополнялись собственными символами. Такое решение, в частности, было использовано в кодировке KOI 8.
Однако единым стандартом указанные кодировки так и не стали. Например, в MS-DOS для русских локализаций использовалась кодировка cp866, а далее в среде MS Windows стали использоваться кодировки cp1251. Для греческого языка применялись кодировки cp851 и cp1253. В результате документы, подготовленные с использованием старой кодировки, становились нечитаемыми на новых.
Свои кодировки необходимы и для других стран с уникальным набором символов. Это приводило к путанице и сложностям в обмене информацией. Ниже приведён пример текста, который написали в кодировке KOI8-R, а читают в cp851.
| KOI8-R | cp851 |
|---|---|
| English text. | English text. |
| Это — русский текст :-). | ΰΨΣ — ΦΩΧΧ╦╔╩ Ψ┼╦ΧΨ :-). |
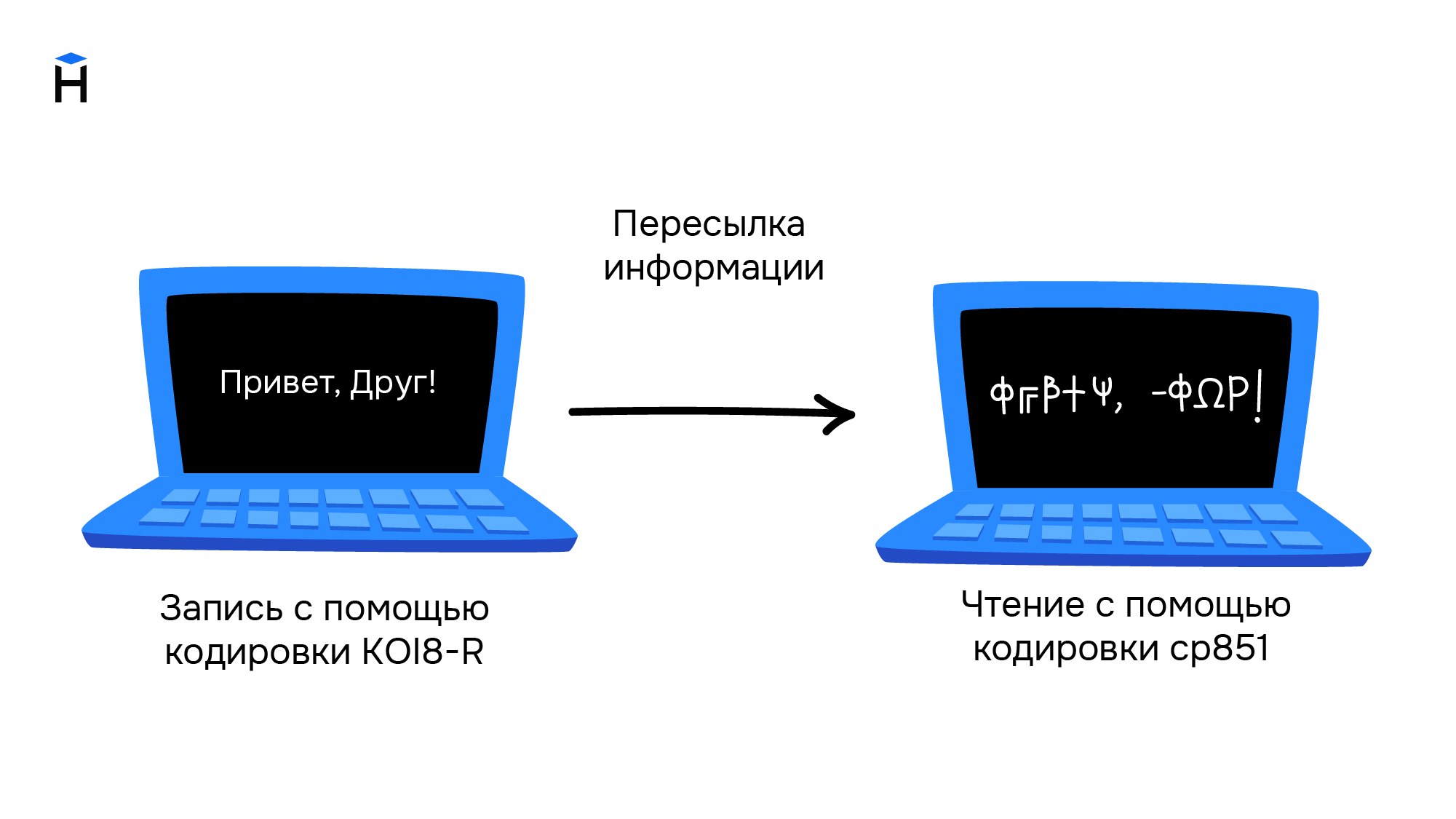
Обе кодировки основаны на стандарте ASCII, поэтому знаки препинания и буквы английского алфавита в обеих кодировках выглядят одинаково. Кириллический текст при этом становится совершенно нечитаемым.
При этом компьютерная память была дорогой, а связь между компьютерами медленной. Поэтому выгоднее было использовать кодировки, в которых размер в битах каждого символа был небольшим. Таблица символов состоит из 256 символов. Это значит, что нам достаточно 8 бит для кодирования любого из них (2^8 = 256).
Ресурсы ФЦИОР

(Внимание! Для воспроизведения модуля необходимо установить на компьютере проигрыватель ресурсов.) Скачать проигрыватель ресурсов ФЦИОР

1) информационный модуль по теме «Представление текста в различных кодировках»;
2) практический модуль теме «Представление текста в различных кодировках»;
3) контрольный модуль по теме «Представление текста в различных кодировках».
Документы MS WORD
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx . Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
Есть неск. путей решения:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы (с 2020г. дополнение с офиц. сайта удалено) . Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично) ;
- использовать аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии (2019+);
- если речь идет о документы TXT — открыть его в Notepad++.
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая.
Переключение кодировки в Word при открытии документа
Как сохранить онлайн видео в формате MP4 в HD качестве
Вы можете смотреть видео онлайн, когда у вас есть высокоскоростное подключение к Интернету, но иногда вам приходится смотреть их автономно.
Наш онлайн загрузчик поможет вам сохранить видео в формате MP4 в HD качестве без каких-либо потерь и смотреть в удобное для вас время.
Примеры решения задач
1. С помощью кодировки Unicode закодирована следующая фраза: Я хочу поступить в университет!
Оцените информационный объем этой фразы.
Решение:
В данной фразе содержится 31 символ (включая пробелы и знак препинания). Поскольку в кодировке Unicode каждому символу отводится 2 байта памяти, для всей фразы понадобится 31*2 = 62 байта или 31*2*8 = 496 битов.
2. Статья, набранная на компьютере, содержит 8 страниц, на каждой странице 40 строк, в каждой строке 64 символа. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объем статьи в этом варианте Unicode. Выберите верный ответ из предложенных: а) 320 байт, б) 35 Кбайт , в) 640 байт, г) 40 Кбайт.
Определим количество символов: 8*40*64 = 20480. Поскольку в кодировке Unicode каждому символу отводится 16 битов памяти, для всей фразы понадобится 20480*16 = 327680 битов.