Вопросы к экзамену по дисциплине «Базы данных»
-
История
развития баз данных.
До
1968 года была только обработка файлов,
она предшествовала обработке баз данных.
Данные хранились в виде списков. Характер
обработки определялся всеобщим
использованием в качестве носителя
магнитной ленты.
В
1968-1980 используются иерархические и
сетевые модели. Это эра обработки
нереаляционных баз данных. Выдающейся
иерархической моделью данных была DL/I
фирмы IBM.Первая
СУБД называлась IMS.
С
коммерческим успехом хранилищ на дисках
в середине 1960-х стало возможным получение
непоследовательного, или прямого,
доступа к записям.
Реляционная
модель впервые была предложена Е. Ф.
Коддом в 1970 году. Наиболее известным из
этих продуктов является DB2 — СУБД,
которая активно используется и поныне.
SQL
Server был разработан в Sybase и в конце
восьмидесятых годов продан Microsoft. Сегодня
DB2, Oracle и SQL Server являются наиболее
выдающимися коммерческими СУБД.
В
1982 году стали применяться первые СУБД
для микропроцессоров. Фирма Ashton-Tate
разработала dBase,
Microrim
– R:Base,
a
Borland
– Paradox.
С
1985 года начинает развиваться интерес
к объектно-ориентированным СУБД (ООСУБД).
С развитием объектно-ориентированного
программирования были предложены
ООСУБД.
В
1991 году компания Microsoft
выпустила Access.
Персональная СУБД. Созданная как элемент
Windows
постепенно вытеснила с рынка все другие
персональные СУБД.
В
1995 году выпускаются первые приложения
баз данных для Интернета. Базы данных
стали ключевыми компонентами
Интернет-приложений. Популярность
Интернета существенно повысила
необходимость в базах данных и требования
к ним.
С
1997 года началось применение XML
к обработке баз данных. Использование
XML
решило проблемы, которые долго стояли
перед базами данных. Ведущие производители
стали интегрировать XML
в свои СУБД.
-
Основные
понятия теории баз данных.
Данные – информационное представление
в виде, позволяющем автоматизировать
ее сбор, хранение, обработку человеком
или информационным средством.
База данных (БД) – именованная совокупность
данных отражающая состояние объекта и
их отношение в рассматриваемой предметной
области. Это взаимосвязанные данные,
при такой минимальной избыточности,
которая допускает и использование
оптимальным образом для одного или
нескольких приложений.
Автоматизированная информационная
система – система реализующая
автоматический сбор, обработку и
манипулирование данными, функционирующая
на основе ЭВМ и других технических
средств, и включающее соответствующее
ПО и персонал.
Под задачами обработки данных обычно
понимается специальный класс решаемых
с помощью компьютера задач, связанных
с видом, хранением, сортировкой, отбором
по заданному условию и группировкой
записей однородной структуры.
Каждая информационная структура(БД) в
зависимости от ее предназначения имеют
дело с той или иной частью реального
мира, которую принято называть предметной
областью БД.
Под БД возможно понимать совместно
использованный набор логически связанных
данных, обеспечивающий выполнение
информационных потребностей пользователя.
СУБД(система управления БД) – ПО с
помощью которого пользователи могут
определять, создавать и поддерживать
БД, а так же получать к ней контролируемый
доступ.
Ключевую роль при обеспечении эффективного
хранения данных имеют методы поддержания
логических связей между данными.
В зависимости от способов организации
связей выделяют различные модели данных:
иерархическую, сетевую, реляционную.
Программы с помощью которых пользователи
работают с БД называют приложениями.
-
Развитие
систем обработки данных. Современные
тенденции в обработке данных.
Первый
этап развития СУБД связан с организацией
баз данных на больших машинах.
Базы
данных хранились во внешней памяти
центральной ЭВМ, пользователями этих
баз данных были задачи, запускаемые в
основном в пакетном режиме. Интерактивный
режим доступа обеспечивался с помощью
консольных терминалов, которые не
обладали собственными вычислительными
ресурсами (процессором, внешней памятью)
и служили только устройствами ввода-вывода
для центральной ЭВМ. Программы доступа
к БД писались на различных языках и
запускались как обычные числовые
программы. Мощные операционные системы
обеспечивали возможность условно
параллельного выполнения всего множества
задач.
Особенности
этого этапа развития выражаются в
следующем:
-
Все
СУБД базируются на мощных мультипрограммных
операционных системах (MVS, SVM, RTE, OSRV, RSX,
UNIX), поэтому в основном поддерживается
работа с централизованной базой данных
в режиме распределенного доступа. -
Функции
управления распределением ресурсов в
основном осуществляются операционной
системой (ОС). -
Поддерживаются
языки низкого уровня манипулирования
данными, ориентированные на навигационные
методы доступа к данным. -
Значительная
роль отводится администрированию
данных. -
Проводятся
серьезные работы по обоснованию и
формализации реляционной модели данных,
и была создана первая система (System R),
реализующая идеологию реляционной
модели данных. -
Проводятся
теоретические работы по оптимизации
запросов и управлению распределенным
доступом к централизованной БД, было
введено понятие транзакции. -
Результаты
научных исследований открыто обсуждаются
в печати, идет мощный поток общедоступных
публикаций, касающихся всех аспектов
теории и практики баз данных, и результаты
теоретических исследований активно
внедряются в коммерческие СУБД.
Появляются
первые языки высокого уровня для работы
с реляционной моделью данных. Однако
отсутствуют стандарты для этих первых
языков.
Особенности
этапа персональных компьютеров:
-
Все
СУБД были рассчитаны на создание БД в
основном с монопольным доступом. И это
понятно. Компьютер персональный, он не
был подсоединен к сети, и база данных
на нем создавалась для работы одного
пользователя. В редких случаях
предполагалась последовательная работа
нескольких пользователей, например,
сначала оператор, который вводил
бухгалтерские документы, а потом
главбух, который определял проводки,
соответствующие первичным документам. -
Большинство
СУБД имели развитый и удобный
пользовательский интерфейс. В большинстве
существовал интерактивный режим работы
с БД как в рамках описания БД, так и в
рамках проектирования запросов. Кроме
того, большинство СУБД предлагали
развитый и удобный инструментарий для
разработки готовых приложений без
программирования. Инструментальная
среда состояла из готовых элементов
приложения в виде шаблонов экранных
форм, отчетов, этикеток (Labels), графических
конструкторов запросов, которые
достаточно просто могли быть собраны
в единый комплекс. -
Во
всех настольных СУБД поддерживался
только внешний уровень представления
реляционной модели, то есть только
внешний табличный вид структур данных. -
При
наличии высокоуровневых языков
манипулирования данными типа реляционной
алгебры и SQL в настольных СУБД
поддерживались низкоуровневые языки
манипулирования данными на уровне
отдельных строк таблиц. -
В
настольных СУБД отсутствовали средства
поддержки ссылочной и структурной
целостности базы данных. Эти функции
должны были выполнять приложения,
однако скудость средств разработки
приложений иногда не позволяла это
сделать, и в этом случае эти функции
должны были выполняться пользователем,
требуя от него дополнительного контроля
при вводе и изменении информации,
хранящейся в БД. -
Наличие
монопольного режима работы фактически
привело к вырождению функций
администрирования БД и в связи с этим
— к отсутствию инструментальных средств
администрирования БД. -
И,
наконец, последняя и в настоящий момент
весьма положительная особенность —
это сравнительно скромные требования
к аппаратному обеспечению со стороны
настольных СУБД. Вполне работоспособные
приложения, разработанные, например,
на Clipper, работали на PC 286. -
В
принципе, их даже трудно назвать
полноценными СУБД. Яркие представители
этого семейства — очень широко
использовавшиеся до недавнего времени
СУБД Dbase (DbaseIII+, DbaseIV), FoxPro, Clipper, Paradox.
Особенности
этапа распределенных БД:
-
Практически
все современные СУБД обеспечивают
поддержку полной реляционной модели,
а именно:-
О
структурной целостности — допустимыми
являются только данные, представленные
в виде отношений реляционной модели; -
О
языковой целостности, то есть языков
манипулирования данными высокого
уровня (в основном SQL); -
О
ссылочной целостности, контроля за
соблюдением ссылочной целостности в
течение всего времени функционирования
системы, и гарантий невозможности со
стороны СУБД нарушить эти ограничения.
-
-
Большинство
современных СУБД рассчитаны на
многоплатформенную архитектуру, то
есть они могут работать на компьютерах
с разной архитектурой и под разными
операционными системами, при этом для
пользователей доступ к данным, управляемым
СУБД на разных платформах, практически
неразличим. -
Необходимость
поддержки многопользовательской работы
с базой данных и возможность
децентрализованного хранения данных
потребовали развития средств
администрирования БД с реализацией
общей концепции средств защиты данных. -
Потребность
в новых реализациях вызвала создание
серьезных теоретических трудов по
оптимизации реализаций распределенных
БД и работе с распределенными транзакциями
и запросами с внедрением полученных
результатов в коммерческие СУБД. -
Для
того чтобы не потерять клиентов, которые
ранее работали на настольных СУБД,
практически все современные СУБД имеют
средства подключения клиентских
приложений, разработанных с использованием
настольных СУБД, и средства экспорта
данных из форматов настольных СУБД
второго этапа развития. -
Именно
к этому этапу можно отнести разработку
ряда стандартов в рамках языков описания
и манипулирования данными начиная с
SQL89, SQL92, SQL99 и технологий по обмену
данными между различными СУБД, к которым
можно отнести и протокол ODBC (Open DataBase
Connectivity), предложенный фирмой Microsoft. -
Именно
к этому этапу можно отнести начало
работ, связанных с концепцией
объектно-ориентированных БД — ООБД.
Представителями СУБД, относящимся к
второму этапу, можно считать MS Access 97 и
все современные серверы баз данных
Oracle7.3,Oracle 8.4 MS SQL6.5, MS SQL7.0, System 10, System 11,
Informix, DB2, SQL Base и другие современные
серверы баз данных, которых в настоящий
момент насчитывается несколько десятков.
Перспективы
развития СУБД. Этот этап характеризуется
появлением новой технологии доступа к
данным — интранет. Основное
отличие этого подхода от технологии
клиент-сервер состоит в том, что отпадает
необходимость использования
специализированного клиентского
программного обеспечения. Для работы
с удаленной базой данных используется
стандартный браузер Интернета, например
Microsoft Internet Explorer или Netscape Navigator, и для
конечного пользователя процесс обращения
к данным происходит аналогично скольжению
по Всемирной Паутине. При этом встроенный
в загружаемые пользователем HTML-страницы
код, написанный обычно на языке Java,
Java-script, Perl и других, отслеживает все
действия пользователя и транслирует
их в низкоуровневые SQL-запросы к базе
данных, выполняя, таким образом, ту
работу, которой в технологии клиент-сервер
занимается клиентская программа.
Удобство данного подхода привело к
тому, что он стал использоваться не
только для удаленного доступа к базам
данных, но и для пользователей локальной
сети предприятия. Простые задачи
обработки данных, не связанные со
сложными алгоритмами, требующими
согласованного изменения данных во
многих взаимосвязанных объектах,
достаточно просто и эффективно могут
быть построены по данной архитектуре.
В этом случае для подключения нового
пользователя к возможности использовать
данную задачу не требуется установка
дополнительного клиентского программного
обеспечения. Однако алгоритмически
сложные задачи рекомендуется реализовывать
в архитектуре «клиент-сервер» с
разработкой специального клиентского
программного обеспечения.
-
Типовая
организация современной СУБД.
Логически в современной СУБД можно
выделить:
-
Ядро СУБД
-
Компилятор языка БД
-
Подсистему поддержки времени выполнения
-
Набор утилит
Ядро СУБД отвечает за (функции):
-
Управление данными во внешней памяти
(выгрузка загрузка файлов) -
Управление буферами оперативной памяти
-
Управление транзакциями и журнализацией
Транзакция – последовательность
операций над БД рассматриваемое СУБД
как
единое целое.
Журнал – особая часть БД, недоступная
пользователю и отображающая все изменения
основной части БД.
Ядро СУБД содержит 4 менеджера:
-
Менеджер данных
-
Менеджер буфера
-
Менеджер транзакции
-
Менеджер журнала
Компилятор языка БД. Основная функция
компилятора языка БД является компиляция
операторов языка БД в некоторую
выполненную программу.
Языки БД являются непроцедурными, т.е.
оператор языка определяет некоторые
действия к БД, но при этом не является
процедурой. Поэтому именно компилятор
языка должен решить каким образом
выполняется команда.
Результатом компиляции в любом случает
должно выполненная программа представленная
в машинном коде.
Операция компиляции производится с
помощью подсистемы поддержки времени
выполнения представляют собой
интерпретатор внутреннего языка.
-
Модели
данных. Классификация моделей данных.

Концептуальное
(инфологическое) проектирование —
построение семантической модели
предметной области, то есть информационной
модели наиболее высокого уровня
абстракции. Такая модель создаётся без
ориентации на какую-либо
конкретную СУБД и модель
данных.
Такая модель является как образом
реальности, так и образом проектируемой
базы данных для этой реальности.
Конкретный
вид и содержание концептуальной модели
базы данных определяется выбранным для
этого формальным аппаратом.
Диаграмма
Бахмена – ориентированный граф,
предназначающийся для того чтобы
отображать отношения к БД и состоящий
из вершин соответствующих типов записи
и дуг соответствующих отношениям.
Чаще
всего концептуальная модель базы данных
включает в себя:
-
описание
информационных объектов, или понятий
предметной области и связей между ними. -
описание
ограничений целостности, т.е. требований
к допустимым значениям данных и к связям
между ними.
Логическое
(даталогическое) проектирование —
создание схемы
базы данных на
основе конкретной модели
данных,
например, реляционной
модели данных.
Для реляционной модели данных
даталогическая модель — набор
схем отношений,
обычно с указанием первичных
ключей,
а также «связей» между отношениями,
представляющих собой внешние
ключи.
Преобразование
концептуальной модели в логическую
модель как правило осуществляется по
формальным правилам. Этот этап может
быть в значительной степени автоматизирован.
На
этапе логического проектирования
учитывается специфика конкретной модели
данных, но может не учитываться специфика
конкретной СУБД.
Физическое
проектирование —
создание схемы
базы данных для
конкретной СУБД.
Специфика конкретной СУБД может включать
в себя ограничения на именование объектов
базы данных, ограничения на поддерживаемые
типы данных и т.п. Кроме того, специфика
конкретной СУБД при физическом
проектировании включает выбор решений,
связанных с физической средой хранения
данных (выбор методов управления дисковой
памятью, разделение БД по файлам и
устройствам, методов доступа к данным),
создание индексов и т.д.
-
Теоретико
– множественные модели данных.
Появление
теоретико-множественных моделей в
системах баз данных было предопределено
настоятельной потребностью пользователей
в переходе от работы с
элементами
данных, как это делается и графовых
моделях, к работе с некоторыми
макрообъсктамн. Основной моделью в этом
классе является реляционная модель
данных. Простота и наглядность модели
для пользователей-непрограммистов, с
одной стороны, и серьезное теоретическое
обоснование, с другой стороны, определили
большую популярность этой модели. Кроме
того, развитие формального аппарата
представления и манипулирования данными
в рамках реляционной модели сделали се
наиболее перспективной для использования
в системах представления знаний, что
обеспечивает качественно иной подход
к обработке данных в больших информационных
системах.
-
Теоретико
– графовые модели данных.
Эти
модели отражают совокупность объектов
реального мира в виде графа взаимосвязанных
информационных объектов, В зависимости
от типа графа выделяют иерархическую
или сетевую модели. Исторически эти
модели появились раньше, и в настоящий
момент они используются реже, чем более
современная реляционная модель данных.
Однако до сих пор существуют системы,
работающие на основе этих моделей, а
одна из концепций развития
объектно-ориентированных баз данных
предполагает объединение принципов
сетевой модели с концепцией реляционной.
-
Сетевая
модель. Сетевой граф базы данных.
Достоинства и недостатки.
Стандарт
сетевой модели впервые был определен
в 1975 году организацией
CODASYL
(Conference of Data System Languages), которая
определила
базовые
понятия
модели и формальный язык описания.
Базовыми
объектами модели являются:
-
элемент
данных; -
агрегат
данных; -
запись;
-
набор
данных.
Элемент
данных —
то же, что и в иерархической модели, то
есть минимальная
информационная
единица, доступная пользователю с
использованием СУБД.
Агрегат
данных соответствует
следующему уровню обобщения в модели.
В модели определены агрегаты двух типов:
агрегат типа вектор
и
агрегат типа повторяющаяся
группа.
Агрегат
данных имеет имя, и в системе допустимо
обращение к агрегату по имени. Агрегат
типа’ вектор соответствует линейному
набору элементов данных.
Записью
называется совокупность агрегатов или
элементов данных, моделирующая некоторый
класс объектов реального мира. Понятие
записи соответствует понятию ≪сегмент≫
в иерархической модели. Для записи, так
же как и для сегмента, вводятся понятия
типа записи и экземпляра записи.
Следующим
базовым понятием в сетевой модели
является понятие ≪Набор≫.
Набором
называется двухуровневый граф, связывающий
отношением ≪один-ко-многим≫
два типа записи.
Набор
фактически отражает иерархическую
связь между двумя типами записей.
Родительский
тип записи в данном наборе называется
владельцем набора, а дочерний тип записи
— членом того же набора.
-
Иерархическая
модель данных. Достоинства и недостатки.
Иерархическая
модель данных является
наиболее простой среди всех даталогических
моделей. Исторически она появилась
первой среди всех диалогических моделей:
именно эту модель поддерживает первая
из зарегистрированных промышленных
СУБД IMS фирмы IBM.
Появление
иерархической модели связано с тем, что
в реальном мире очень многие связи
соответствуют иерархии, когда один
объект выступает как родительский, а с
ним может быть связано множество
подчиненных объектов. Иерархия проста
и естественна в отображении взаимосвязи
между классами объектов.
Основными
информационными единицами в иерархической
модели являются: база
данных (БД), Сегмент и поле, Поле
данных определяется как минимальная,
неделимая единица данных, доступная
пользователю с помощью СУБД.
Сегмент
называется
записью,
при
этом в рамках иерархической модели
определяются два понятия: тип
сегмента или
тип
записи и
экземпляр
сегмента
или
экземпляр
записи.
Тип
сегмента — это
поименованная совокупность типов
элементов данных, в него
входящих.
Экземпляр
сегмента образуется
из конкретных значений полей или
элементов данных, в него входящих. Каждый
тип сегмента в рамках иерархической
модели образует некоторый набор
однородных записей. Для возможности
различия отдельных записей в данном
наборе каждый тип сегмента должен иметь
ключ или набор ключевых атрибутов
(полей, элементов данных). Ключом
называется набор элементов данных,
однозначно идентифицирующих экземпляр
сегмента.
В
иерархической модели сегменты объединяются
в ориентированный древовидный граф.
При этом полагают, что направленные
ребра графа отражают иерархические
связи между сегментами: каждому экземпляру
сегмента, стоящему выше по иерархии и
соединенному с данным типом сегмента,
соответствует несколько (множество)
экземпляров данного (подчиненного) типа
сегмента.
Тип
сегмента, находящийся на более высоком
уровне иерархии, называется логически
исходным по отношению к типам сегментов,
соединенным с данным направленными
иерархическими ребрами, которые в свою
очередь называются логически подчиненными
по отношению к этому типу сегмента.
Иногда исходные сегменты называют
сегментами-предками, а подчиненные
сегменты называют сегментами-потомками.
Схема
иерархической БД представляет собой
совокупность отдельных деревьев,
каждое
дерево в рамках модели называется
физической
базой данных. Каждая
физическая
БД удовлетворяет следующим иерархическим
ограничениям:
-
в
каждой физической БД существует один
корневой сегмент, то есть сегмент, у
которого нет логически исходного
(родительского) типа сегмента; -
каждый
логически исходный сегмент может быть
связан с произвольным числом логически
подчиненных сегментов; -
каждый
логически подчиненный сегмент может
быть связан только с одним логически
исходным (родительским ) сегментом.
Очень
важно понимать различие между сегментом
и типом сегмента — оно такое же, как
между типом переменной и самой переменной:
сегмент является экземпляром типа
сегмента.
Каждый
тип сегмента может иметь множество
соответствующих ему экземпляров. Между
экземплярами сегментов также существуют
иерархические связи.
-
Трехуровневая
архитектура базы данных.
В основу СУБД была положена:

Уровень внешних моделей – самый верхний
уровень, где каждая модель имеет свое
видение данных. На внешнем уровне каждое
приложение обрабатывает необходимые
только ему данные.
Концептуальный уровень – логическая
организация всех имеющихся на внешнем
уровне моделей, в единую обобщенную
модель предметной области.
Физический уровень – данные (БД) в виде
файлов и т.д. на внешних носителях
информации.
-
Свойства
проектируемой СУБД.
СУБД
для хранилищ данных представляет собой
целостную систему, которая обеспечивает
поддержку и управление одной или
несколькими логическими БД. В дополнение
к поддержке реляционной модели данных,
СУБД должны обеспечивать доступ к данным
со стороны внешних независимых приложений
и включать механизмы контроля различных
параметров доступа пользователей.
Важным также является тот факт, что сама
СУБД не является хранилищем данных, а
только предоставляет платформу для его
развертывания.
В свою очередь, хранилище
данных представляет собой информационную
базу, объединяющую в единое целое
несколько разнородных источников
данных. Структура хранилища позволяет
добавлять дополнительные источники
данных без необходимости перепроектирования.
Хранилище данных может быть любого
размера.
В первую очередь, важно
грамотно оценить основные технические
характеристики СУБД, такие как
масштабируемость, управляемость,
безопасность, высокий уровень доступности
и послеаварийного восстановления,
поддержка смешанных нагрузок,
дополнительных структур данных и
возможностей по их загрузке. Подобный
продукт должен обладать рядом свойств,
позволяющих управлять значительными
объемами разнородных данных, поддерживать
сложные модели данных, быть независимым
от конкретных приложений и иметь очень
высокую надежность.
Одним из основных
критериев при выборе СУБД является
полнота и завершенность продукта.
Необходимо, чтобы система отвечала
фундаментальным требованиям
масштабируемости и управления рабочими
нагрузками. Очень важным фактором
является возможность СУБД работать на
нескольких платформах при поддержке
различных операционных систем и
масштабироваться в соответствии с
используемыми инструментальными
средствами. Необходимо определить,
способна ли система эффективно
использовать мощности операционной
платформы, чтобы обеспечить оптимальную
производительность сложного хранилища
данных.
-
Функции
СУБД.
-
Управление данными во внешней памяти:
-
Транзакция успешно выполняет в СУБД
фиксированные изменения БД -
Если какое-либо из изменений не
состоялось, то эта транзакция не
отображается на БД.
Механизм транзакций является обязательным
условием работы любой СУБД.
-
Управление буферами оперативными
памяти.
СУБД работает с БД значительного объема,
поэтому все классические СУБД имеют
свои собственные буферы оперативной
памяти, в которые и выполняют подгрузку
данных.
-
Управление транзакциями
Функции включают в себя обеспечение
необходимой структур внешней памяти
как для хранения данных, непосредственно
входящих в БД.
Пользователь не обязан знать, какую
файловую систему использует СУБД.
-
Журнализация
Журнал – особая часть СУБД, которая
фиксирует все изменения БД, надежность
хранения БД, СУБД должно восстановить
последнее согласованное состояние
рабочей БД после аппаратного или
программного сбоя.
Аппаратные сбои:
-
Мягкие сбои (внезапная остановка
работоспособности) -
Жесткие сбои (потеря информации на
носителе)
Программные сбои:
-
Аварийное выключение СУБД
-
Завершение работы приложения (аварийное)
-
Жизненный
цикл баз данных. Этап анализа и
проектирования.
Как и любой программный продукт БД
создаются, функционируют и устаревают.
Поэтому в любом жизненном цикле БД можно
выделить 3 основных этапа:
-
Анализ и проектирование БД
-
Формулирование задачи и анализ
требований -
Концептуальное проектирование
-
Проектирование реализаций
-
Реализация БД
-
Непосредственная реализация
-
Физическое проектирование
-
Тестирование
-
-
Поддержка БД
-
Анализ функционирования и поддержка
исходного варианта БД -
Адаптация, модернизация и поддержка
переработанных вариантов БД.
-
На первом этапе осуществляется
предварительное планирование системы
Бд. Строится общая информационная
модель, осуществляется сбор информации
по предметной области для которой
разрабатывается БД. Важной частью
данного этапа является проверка
осуществимости проекта:
-
Технологическая осуществимость.
Выясняется существует ли оборудование
или ПО, необходимое для проектирования
БД, наличие необходимых ресурсов. -
Операционная осуществимость. Выясняется
наличие экспертов и персонала, необходимое
для работы БД, анализируются требования
к квалификации и опыту специалистов. -
Проверка экономической целесообразности.
-
Влияние БД на стратегию
Результат работы данного этапа заключается
в выполнении следующих 4 задач:
-
Определить цели системы БД путем анализа
информации потребности пользователя(с
привлечением знаний эксперта) -
Определение пользовательских требований
и построение концептуальной модели -
Определение общих требований к
оборудованию и ПО -
Разработка поэтапного плана создания
системы.
-
Логическое
проектирование базы данных.
Логическое
проектирование базы данных. Процесс
создания модели используемой на
предприятии информации на основе
выбранной модели организации данных,
но без учета типа целевой СУБД и других
физических аспектов реализации.
Второй
этап проектирования базы данных
называется логическим проектированием
базы данных. Его цель состоит в создании
логической модели данных для исследуемой
части предприятия. Концептуальная
модель данных, созданная на предыдущем
этапе, уточняется и преобразуется в
логическую модель данных.Логическая
модель данных учитывает особенности
выбранной модели организации данных в
целевой СУБД (например, реляционная
модель).
Если
концептуальная модель данных не зависит
от любых физических аспектов реализации,
то логическая модель данных создается
на основе выбранной модели организации
данных целевой СУБД. Иначе говоря, на
этом этапе уже должно быть известно,
какая СУБД будет использоваться в
качестве целевой — реляционная, сетевая,
иерархическая или объектно-ориентированная.
Однако на этом этапе игнорируются все
остальные характеристики выбранной
СУБД, например, любые особенности
физической организации ее структур
хранения данных и построения индексов.
В
процессе разработки логическая модель
данных постоянно тестируется и проверяется
на соответствие требованиям пользователей.
Для проверки правильносги логической
модели данных используется метод
нормализации. Нормализация гарантирует,
что отношения, выведенные из существующей
модели данных, не будут обладать
избыточностью данных, способной вызвать
нарушения в процессе обновления данных
после их физической реализации. Помимо
всего прочего, логическая модель данных
должна обеспечивать поддержку всех
необходимых пользователям транзакций.
Созданная
логическая модель данных является
источником информации для этапа
физического проектирования и обеспечивает
разработчика физической базы данных
средствами поиска компромиссов,
необходимых для достижения поставленных
целей, что очень важно для эффективного
проектирования. Логическая модель
данных играет также важную роль на этапе
эксплуатации и сопровождения уже готовой
системы. При правильно организованном
сопровождении поддерживаемая в актуальном
состоянии модель данных позволяет точно
и наглядно представить любые вносимые
в базу данных изменения, а также оценить
их влияние на прикладные программы и
использование данных, уже имеющихся в
базе.
-
Жизненный
цикл баз данных. Концептуальное
проектирование базы данных.
Как и любой программный продукт БД
создаются, функционируют и устаревают.
Поэтому в любом жизненном цикле БД можно
выделить 3 основных этапа:
-
Анализ и проектирование БД
-
Формулирование задачи и анализ
требований -
Концептуальное проектирование
-
Проектирование реализаций
-
Реализация БД
-
Непосредственная реализация
-
Физическое проектирование
-
Тестирование
-
-
Поддержка БД
-
Анализ функционирования и поддержка
исходного варианта БД -
Адаптация, модернизация и поддержка
переработанных вариантов БД.
-
В процессе концептуального проектирования
строится концептуальная схема БД.
Построение:
-
Выделение локальных представлений,
соответствие относительно независимых
данных. -
Формулирование объектов, описывающих
локальную предметную область проектируемой
БД, описание атрибутов составляющих
каждый объект -
Выделение ключевых атрибутов
-
Спецификация связей между объектами
-
Анализ и добавление не ключевых атрибутов
-
Объединение локальных представлений
-
Концептуальное
проектирование базы данных. Объекты.
Атрибуты. Конкретизация и обобщение.
В процессе концептуального проектирования
предметная область рассматривается
как объектная система, состоящая из
объектного множества, объектов, атрибутов
объектов, и связи между ними.
Объект – это то, о чем накапливается
информация в любой информационной
системе. Каждый объект в определенный
момент времени может характеризоваться
своим состоянием. Фактические объекты
– предметы и вещи, которые пользователь
считает наиболее важными в моделированной
области.
Объектное множество – используется
для обозначения множества вещей одного
типа, объект-элемент – обозначает один
элемент объектного множества. На
концептуальной схеме обозначается
прямоугольником объектного множества.
Объект-элемент соответствует записи
объектного множества средствами
конкретной СУБД. Два объектных множества
могут быть связанны между собой.
Атрибут – именованная характеристика
объекта, с помощью которой моделируются
его свойства. Атрибуты одинаковы для
объектного множества, но имеют разное
значение для объектов объектного
множества. Значение атрибутов могут
меняться в процессе эксплуатации БД.
Атрибут обозначается овалом на
концептуальной схеме. Помимо описания
свойств объекта, выделяют один атрибут
с помощью которого можно однозначно
идентифицировать объект. Данный атрибут
будет являться ключевым.
-
Концептуальное
проектирование базы данных. Связи между
объектами. Мощность связи.
Между
сущностями могут быть установлены связи
~~ бинарные
ассоциации, показывающие, каким образом
сущности соотносятся или взаимодействуют
между
собой.
Связь может существовать между двумя
разными сущностями пли между
сущностью
и ей же самой (рекурсивная
связь). Она
показывает, как связаны экземпляры
сущностей между собой. Если связь
устанавливается между двумя сущностями,
то она определяет взаимосвязь между
экземплярами одной и другой сущности.
Связи
делятся на три типа по множественности:
одип-к-одному
(1:1),
один-ко-многим
(1:М),
многие-ко~миогим
(М:М).
Связь один-к-одному означает, что
экземпляр одной сущности связан только
с одним экземпляром другой сущности.
Связь 1: М означает, что один экземпляр
сущности, расположенный слева по связи,
может быть связан с несколькими
экземплярами сущности, расположенными
справа по связи. Связь ≪один-к-одному≫
(1:1) означает, что один экземпляр одной
сущности связан только с одним экземпляром
другой сущности, а связь ≪многие-ко-многим≫
(М:М) означает, что один экземпляр первой
сущности может быть связан с несколькими
экземплярами второй сущности, и наоборот,
один экземпляр второй сущности может
быть связан с несколькими экземплярами
первой сущности.
-
Между
двумя сущностями может быть задано
сколько угодно связей с раз-
ными
смысловыми нагрузками
-
Связь
любого из этих типов может быть
обязательной,
если
в данной связи
должен
участвовать каждый экземпляр сущности,
необязательной
— если
не каждый экземпляр сущности должен
участвовать в дайной связи. При этом
связь может быть обязательной
с одной стороны и необязательной с
другой стороны. Обязательность
связи тоже по-разному обозначается в
разных нотациях.
-
Концептуальное
проектирование базы данных. Моделирование
предметной области.
Основные
цели моделирования данных состоят в
изучении значения (семантики) данных и
упрощении процедур описания требований
к данным. При создании модели данных
необходимо получить ответы на определенные
вопросы об отдельных сущностях, связях
и атрибутах. Полученные дополнительные
сведения помогут разработчикам раскрыть
особенности семантики корпоративных
данных, которые существуют независимо
от того, отмечены они в формальной модели
данных или нет. Сущности, связи и атрибуты
являются фундаментальными информационными
объектами любого предприятия. Однако
их реальный смысл будет оставаться не
вполне понятным до тех пор, пока они не
будут должным образом описаны в
документации. Моделирование данных
упрощает понимание смысла элементов
данных, поэтому создание модели необходимо
для того, чтобы гарантировать понимание
следующих аспектов данных:
требования
к данным отдельных пользователей;
характер
самих данных независимо от их физического
представления;
использование
данных в пределах области применения
приложения.
Модели
данных могут использоваться для
демонстрации понимания разработчиком
тех требований к данным, которые
существуют на предприятии. Если обе
стороны знакомы с системой обозначений,
используемой для создания модели, то
наличие модели данных будет способствовать
более плодотворному общению пользователей
и разработчиков. На предприятиях все
шире применяются средства стандартизации
для моделирования данных путем выбора
определенного метода моделирования и
использования его во всех проектах
разработки базы данных. Самая популярная
технология высокоуровневого моделирования
данных, чаще всего используемая при
разработке реальных баз данных, построена
на концепции модели «сущность-связь»
(Entity-Relationship model — ER-модель).
-
Концептуальное
проектирование базы данных. Составные
объекты.
В
процессе концептуального проектирования
предметная область рассматривается
как объектная система, состоящая из
объектного множества, объектов, атрибутов
объектов, и связи между ними.
Объекты
представляются в виде существительных.
Отношения в виде глаголов. Объекты –
это то, что пользователь считает
важными.
Составное объектное множество
– это объекты, связанные отношениями.
-
Жизненный
цикл баз данных. Этап реализации.
На этапе реализации инфологическая
модель БД описывается с помощью средств
выбранной СУБД. Специфицируются форматы
представления данных, ограничение
целостности, создается физическая
модель БД, с помощью среды программирования
создается приложение, позволяющее
пользователю формулировать требуемые
запросы к БД и манипулировать данными.
Готовая БД тестируется на соответствие
предъявленным пользователем требовании
и имеющимся спецификациям.
Поэтапно этап реализации можно представить
следующим образом:
-
Выбор и приобретение СУБД
-
Преобразование концептуальной модели
в физическую -
Заполнение БД
-
Создание прикладных программ
-
Тестирование
-
Физическое
проектирование базы данных.
Физическое
проектирование базы данных —
процесс подготовки описания реализации
базы данных на вторичных запоминающих
устройствах; на этом этапе рассматриваются
основные отношения, организация файлов
и индексов, предназначенных для
обеспечения эффективного доступа к
данным, а также все связанные с этим
ограничения целостности и средства
защиты.
Физическое
проектирование является третьим и
последним этапом создания проекта базы
данных, при выполнении которого
проектировщик принимает решения о
способах реализации разрабатываемой
базы данных. Во время предыдущего этапа
проектирования была определена логическая
структура базы данных (которая описывает
отношения и ограничения в рассматриваемой
прикладной области). Хотя эта структура
не зависит от конкретной целевой СУБД,
она создается с учетом выбранной модели
хранения данных, например реляционной,
сетевой или иерархической. Однако,
приступая к физическому проектированию
базы данных, прежде всего необходимо
выбрать конкретную целевую СУБД. Поэтому
физическое проектирование неразрывно
связано с конкретной СУБД. Между
логическим и физическим проектированием
существует постоянная обратная связь,
так как решения, принимаемые на этапе
физического проектирования с целью
повышения производительности системы,
способны повлиять на структуру логической
модели данных.
Как
правило, основной целью физического
проектирования базы данных является
описание способа физической реализации
логического проекта базы данных.
В
случае реляционной модели данных под
этим подразумевается следующее:
-
создание
набора реляционных таблиц и ограничений
для них на основе информации, представленной
в глобальной логической модели данных; -
определение
конкретных структур хранения данных
и методов доступа к ним, обеспечивающих
оптимальную производительность СУБД; -
разработка
средств защиты создаваемой системы.
Этапы
концептуального и логического
проектирования больших систем следует
отделять от этапов физического
проектирования. На это есть несколько
причин.
-
Они
связаны с совершенно разными аспектами
системы, поскольку отвечают на вопрос,
что делать, а не как делать. -
Они
выполняются в разное время, поскольку
понять, что надо сделать, следует прежде,
чем решить, как это сделать. -
Они
требуют совершенно разных навыков и
опыта, поэтому требуют привлечения
специалистов различного профиля.
Проектирование
базы данных — это итерационный процесс,
который имеет свое начало, но не имеет
конца и состоит из бесконечного ряда
уточнений. Его следует рассматривать
прежде всего как процесс познания. Как
только проектировщик приходит к пониманию
работы предприятия и смысла обрабатываемых
данных, а также выражает это понимание
средствами выбранной модели данных,
приобретенные знания могут показать,
что требуется уточнение и в других
частях проекта. Особо важную роль в
общем процессе успешного создания
системы играет концептуальное и
логическое проектирование базы данных.
Если на этих этапах не удастся получить
полное представление о деятельности
предприятия, то задача определения всех
необходимых пользовательских представлений
или обеспечения защиты базы данных
становится чрезмерно сложной или даже
неосуществимой. К тому же может оказаться
затруднительным определение способов
физической реализации или достижения
приемлемой производительности системы.
С другой стороны, способность адаптироваться
к изменениям является одним из признаков
удачного проекта базы данных. Поэтому
вполне имеет смысл затратить время и
энергию, необходимые для подготовки
наилучшего возможного проекта.
-
Разработка
приложений. Тестирование.
Главные составляющие разработки
приложений – это проектирование
транзакций и пользовательского
интерфейса.
Транзакции представляют собой некоторые
события реального мира. Все транзакции
должны обращаться к базе данных с той
целью, чтобы хранимые в ней данные всегда
гарантированно соответствовали текущей
ситуации в реальном мире.
Проектирование транзакций заключается
в определении:
-
Данные, которые используются транзакцией
-
Функциональные характеристики транзакций
-
Выходных данных, формируемых транзакцией
-
Степени важности и интенсивности
использования транзакций
Транзакции могут представлять собой
сложные операции, которые раскладываются
на несколько более простых операций,
каждая из которых представляет собой
отдельную транзакцию.
Пользовательский интерфейс приложений
БД является одним из важнейших компонентов
системы. Интерфейс должен быть удобным
и обеспечивать все функциональные
возможности, предусмотренные в
спецификациях требований пользователей.
Специалисты рекомендуют при проектировании
пользовательского интерфейса использовать
следующие элементы и их характеристики:
-
Содержательное название
-
Ясные и понятные инструкции
-
Логически обоснованные группировки и
последовательности полей -
Визуально привлекательный вид окна
формы или поля отчета -
Легкоузнаваемые названия полей
-
Согласованную терминологию и сокращения
-
Согласованное использование цветов
-
Визуальное выделение пространства и
границ полей ввода данных -
Удобные средства перемещения курсора
-
Средства исправления отдельных ошибочных
символов и целых полей -
Средства вывода сообщений об ошибках
при вводе недопустимых значений -
Особое выделение необязательных для
ввода полей -
Средства вывода сообщения об окончании
заполнения формы.
Обязательное тестирование должен
проходить любой программный продукт,
тем более такой, как прикладные программы
ИС. Стратегия тестирования должна
предполагать использование реальных
данных и должна быть построена таким
образом, чтобы весь выполнялся строго
последовательно и методически правильно.
Пользователи новой системы должны
принимать в процессе ее тестирования
самое активное участие с целью выяснения
их неучтенных информационных потребностей.
Если такие обнаружатся, в случае
необходимости осуществляется откат
назад в процессе проектирования на те
стадии, где возможно внести необходимые
изменения.
Для оценки законченности и корректности
выполнения приложения БД может
использоваться несколько различных
стратегий тестирования:
-
Нисходящее тестирование
-
Восходящее тестирование
-
Тестирование потоков
-
Интенсивное тестирование.
-
Оценка
работы и поддержка базы данных,
эксплуатация и сопровождение.
Оценка работы включает опрос пользователя
с целью выяснение какие информационные
потребности остались неучтенными. В
случае необходимости вносится изменение
в БД. Поддержка БД предполагает разрешение
проблем, возникающих в процессе
эксплуатации БД и связанных как с
ошибками реализации БД, так и с изменением
в самой предметной области, создание
дополнительных программных компонент
или модернизаций самой БД.
-
Реляционная
модель данных.
Реляционной называется БД в которой
все данные, доступные пользователю
организованны в виде таблиц, а все
операции над данными сводятся к операциям
над этими таблицами.
Основными элементами реляционной БД
являются таблицы и связи между ними.
Таблица – некоторая регулярная структура,
состоящая из конечного набора однотипных
записей. Таблица отображает тип объекта
реального мира, который называют еще
сущностью.
Строки соответствуют экземпляру объекта,
конкретному событию или явлению.
Столбцы соответствуют атрибуту,
признакам, характеристикам, параметрам.
У каждой таблицы имеется уникальное
имя внутри БД, каждый столбец обладает
именем, которое служит заголовком
столбца. Все столбцы одной таблицы
уникальны, но их имена могут повторяться
в разных таблицах.
В реляционной таблице данных атрибуты
отношений неупорядочены, т.е. обращены
к полям всегда происходит по имени, а
не по расположению. Таблицы всегда
содержат минимум один столбец.
В реляционной модели данных для
обозначения строки отношения используется
понятие кортеж. Представление кортежа
на физическом уровне является строка
таблицы БД.
Строки таблицы не имеют определенного
порядка, в таблице может содержаться
любое количество строк, допустимо
существование таблицы с нулевым
количеством строк.
Поскольку строки не упорядочены нельзя
выбрать строку по ее номеру в таблице,
в таблице нет первой или последней
строки, для идентификации строки в
таблице используется понятие ключевого
атрибута.
Ключевым элементом данных называется
такой элемент по значению которого
можно однозначно идентифицировать
строку таблицы.
Первичный ключ – атрибут или группа
атрибутов, который единственным образом
идентифицирует каждую строку в таблице.
Если в таблице нет полей значения которых
уникальны, то для создания первичного
ключа в ней вводят дополнительное поле,
необходимое для корректной работы самой
СУБД, если первичный ключ представляет
собой несколько столбцов, то такой ключ
называют составным.
Вторичный ключ устанавливается над
полями, которые часто используются при
поиске и сортировке данных, в отличие
от первичного ключа, поле для вторичного
ключа могут содержать не уникальные
таблицы.
Столбец одной таблицы, значения которого
совпадают со значениями столбца –
первичного ключа, называют внешнем
ключом.
В качестве первичного и внешнего ключи
используется столбцы значения которых
одинаковы для двух различных таблиц.
Внешний и первичный ключ могут представлять
собой комбинацию столбцов.
-
12
правил реляционного подхода.
1 Правило информации. Вся информация
в базе данных должна быть представлена
исключительно на логическом уровне
и только одним
способом — в виде значений, содержащихся
в таблицах.
2 Правило гарантированного доступа.
Логический доступ ко всем и к каждому
элементу данных (атомарному значению)
в реляционной базе
данных должен обеспечиваться путём
использования комбинации имени
таблицы, первичного ключа и имени
столбца.
3 Правило поддержки недействительных
значений. В настоящей
реляционной базе данных должна быть
реализована поддержка
недействительных значений, которые
отличаются от строки символов
нулевой длины, строки пробельных
символов и от нуля или любого
другого числа и используются для
представления отсутствующих данных
независимо от типа этих данных.
4 Правило динамического каталога,
основанного на реляционной модели.
Описание базы данных на логическом
уровне должно быть представлено в том
же виде, что и основные данные, чтобы
пользователи, обладающие соответствующими
правами, могли работать с ним с помощью
того же реляционного языка, который они
применяют для работы с основными данными.
5 Правило исчерпывающего подъязыка
данных. Реляционная система может
поддерживать различные языки и режимы
взаимодействия с
пользователем (например, режим вопросов
и ответов). Однако должен
существовать, по крайней мере, один
язык, операторы которого можно
представить в виде строк символов, в
соответствии с некоторым четко
определенным синтаксисом и который
в полной мере поддерживает
следующие элементы:
— определение данных;
— определение представлений;
— обработку данных (интерактивную и
программную);
— условия целостности;
— идентификация прав доступа;
— границы транзакций (начало, завершение
и отмена).
6 Правило обновления представлений.
Все представления, которые
теоретически можно обновить, должны
быть доступны для обновления.
7 Правило добавления, обновления и
удаления. Возможность работать с
отношением (таблицей) как с одним
операндом должна существовать не только
при чтении данных, но и при добавлении,
обновлении и удалении данных.
8 Правило независимости физических
данных. Прикладные программы и утилиты
для работы с данными должны на логическом
уровне оставаться нетронутыми при
любых изменениях способов хранения
данных или методов доступа к ним.
9 Правило независимости логических
данных. Прикладные программы и утилиты
для работы с данными должны на логическом
уровне оставаться нетронутыми при
внесении в базовые таблицы любых
изменений, которые теоретически позволяют
сохранить нетронутыми содержащиеся в
этих таблицах данные.
10 Правило независимости условий
целостности. Должна существовать
возможность определять условия
целостности, специфические для
конкретной реляционной базы данных, на
подъязыке реляционной базы данных и
хранить их в каталоге, а не в прикладной
программе.
11 Правило независимости распространения.
Реляционная СУБД не должна зависеть от
потребностей конкретного пользователя.
12 Правило единственности. Если в
реляционной системе есть
низкоуровневый язык (обрабатывающий
одну запись за один раз), то
должна отсутствовать возможность
использования его для того, чтобы
обойти правила и условия целостности,
выраженные на реляционном
языке высокого уровня (обрабатывающем
несколько записей за один раз).
-
Функциональные
зависимости и ключи.
Поскольку строки в реляционной таблице
не упорядочены, нельзя выбрать строку
по ее номеру в таблице. Ключевым элементом
данных называется такой элемент, по
которому можно определить значения
других элементов данных. В реляционной
базе данных в каждой таблице есть один
или несколько столбцов, значения в
которых во всех строках разные. Этот
столбец (столбцы) называется первичным
ключом таблицы.
Первичныйключ– это атрибут
или группа атрибутов, которые единственным
образом идентифицируют каждую строку
в таблице. Если в таблице нет полей,
значения в которых уникальны, для
создания первичного ключа в нее обычно
вводят дополнительное поле, значениями
которого СУБД может распоряжаться по
своему усмотрению. Если первичный ключ
представляет собой комбинацию столбцов,
то такой первичный ключ называетсясоставным.
Вторичные ключи устанавливаются
по полям, которые часто используются
при поиске или сортировке данных. В
отличие от первичных ключей, поля для
вторичных ключей могут содержать не
уникальные значения.
Внешние ключи. Столбец одной таблицы,
значения в котором совпадают со значениями
столбца, являющегося первичным ключом
другой таблицы, называется внешним
ключом. Обычно в качестве первичного и
внешнего ключей используются столбцы
с одинаковыми именами из двух различных
таблиц. Внешний ключ, как и первичный
ключ, тоже может представлять собой
комбинацию столбцов. Если таблица
связана с несколькими другими таблицами,
она может иметь несколько внешних
ключей. Внешние ключи являются неотъемлемой
частью реляционной модели, поскольку
реализуют отношения между таблицами
базы данных.
По определению «функциональная
зависимость – это такая связь между
атрибутами В и А одного и того же
отношения, когда каждому значению А
соответствует только одно значение В».
Атрибут А называют детерминантом.
Детерминанты могут быть составными,
т.е. представлять собой не единичные
атрибуты, а группы, состоящие из двух и
более атрибутов.
Функциональные зависимости являются
ограничениями целостности и определяют
семантику хранящихся в БД данных. При
каждом обновлении СУБДдолжна проверять их соблюдение.
Следовательно, наличие большого
количества функциональных зависимостей
нежелательно, иначе происходит замедление
работы. Для упрощения задачи необходимо
сократить набор функциональных
зависимостей до минимально необходимого.
-
Нормализация
отношений и аномалии модификации.
Под нормализациейотношения
подразумевается процесс приведения
отношения к одной из так называемыхнормальных форм(или в дальнейшем
НФ). При проектировании баз данных упор
в первую очередь делается на достоверность
и непротиворечивость хранимых данных,
причем эти свойства не должны утрачиваться
в процессе работы с данными, т.е. после
многочисленных изменений, удалений и
дополнений данных по отношению к
первоначальному состоянию БД.
Для
поддержания БД в устойчивом состоянии
используется ряд механизмов, которые
получили обобщенное название средств
поддержки целостности. Эти механизмы
применяются как статически (на этапе
проектирования БД), так и динамически
(в процессе работы с БД). БД должна
удовлетворять некоторым ограничениям
в процессе создания, независимо от ее
наполнения данными. Приведение структуры
БД в соответствие этим ограничениям —
это и есть нормализация.
В целом суть
этих ограничений весьма проста: каждый
факт, хранимый в БД, должен храниться
один-единственный раз, поскольку
дублирование может привести к
несогласованности между копиями одной
и той же информации. Следует избегать
любых неоднозначностей, а также
избыточности хранимой информации.
Важным критерием качества разрабатываемой
схемы БД является скорость выполнения
операций обновления данных (вставки,
модификации, удаления записей). Выбор
схемы БД определяет возникновение в
процессе ее эксплуатации тех или иных
аномалий обновления.
Аномалия обновления– появление в
базе данных несогласованности данных
при выполнении операций вставки,
удаления, модификации записей.
Аномалии модификации– появление
записей с противоречащими значениями
в некоторых столбцах при изменении
значений соответствующих полей одной
записи.
Пример. Для отношения Студент (ФИО,
Группа, Староста), где в столбце Группа
хранится полное название группы, а
столбец Староста содержит ФИО старосты
группы, изменение значения Староста
(например, для устранения ошибки) может
привести к существованию более одного
старосты одной и той же группы.
Аномалии удаления– удаление лишней
информации при удалении записи.
Пример. Для отношения Студент (ФИО,
Группа, Староста), удаление студента
может привести к удалению из БД и ФИО
старосты группы (в том случае, если для
данной группы запись – единственная).
Аномалии вставки– добавление
лишней информации или возникновение
противоречащих значений в некоторых
столбцах при вставке новой записи.
Пример. Для отношения Студент (ФИО,
Группа, Староста), где в столбце Группа
хранится полное название группы, а
столбец Староста содержит ФИО старосты
группы, добавление названия новой группы
повлечет обязательное определение ФИО
студента и старосты, в то время как эти
данные могут быть пока не известны. В
то же время, при добавлении нового
студента значение поля Староста в новой
записи может не совпадать со значением
данного поля для другого студента этой
же группы.
Для сохранения корректности БД необходимо
устранять данные аномалии, выполняя
дополнительные операции по просмотру
и модификации данных. Потери в
производительности, вызванные выполнением
действий по устранению аномалий, могут
быть весьма существенными, при этом
данные потери, в большинстве случаев,
не являются неизбежными, а определяются
неудачным выбором схемы БД.
Указанные аномалии связаны с избыточностью
данных в БД. Следует различать избыточное
и неизбыточное дублирование данных.
Неизбыточноедублирование возникает
из необходимости хранить идентичные
данные, поскольку важен сам факт их
идентичности, и удаление хотя бы одного
представителя идентичных данных приведет
к невосполнимой потере информации.
Избыточноедублирование (избыточность)
обычно связано с необходимостью задания
значения всех атрибутов отношения, при
этом дублируемые данные не являются
необходимыми, и в случае потери (удаления)
могут быть восстановлены по данным
одного или нескольких отношений БД.
Определить дублирование данных в БД, а
значит и предсказать возможность
возникновения аномалий обновления
можно на этапе проектирования структуры
базы данных. Одним из наиболее
алгоритмически и понятийно простых
методов устранения избыточности хранения
данных является метод нормальных форм,
который основан на анализе функциональных
зависимостей (ФЗ) атрибутов отношений.
-
Свойства
отношений. Обновления отношений.
Свойства:
1. В отношении нет одинаковых кортежей.
Действительно, тело отношения есть
множество кортежей и, как всякое
множество, не может содержать неразличимые
элементы. Таблицы в отличие от отношений
могут содержать одинаковые строки.
2. Кортежи не упорядочены (сверху вниз).
Тело отношения есть множество, а множество
не упорядочено. Это вторая причина, по
которой нельзя отождествить отношения
и таблицы — строки в таблицах упорядочены.
Одно и то же отношение может быть
изображено разными таблицами, в которых
строки идут в различном порядке.
3. Атрибуты не упорядочены (слева направо).
Т.к. каждый атрибут имеет уникальное
имя в пределах отношения, то порядок
атрибутов не имеет значения. Это свойство
несколько отличает отношение от
математического определения отношения.
Это также третья причина, по которой
нельзя отождествить отношения и таблицы
— столбцы в таблице упорядочены. Одно и
то же отношение может быть изображено
разными таблицами, в которых столбцы
идут в различном порядке.
4. Все значения атрибутов атомарны. Это
следует из того, что лежащие в их основе
атрибуты имеют атомарные значения. Это
четвертое отличие отношений от таблиц
— в ячейки таблиц можно поместить что
угодно — массивы, структуры, и даже другие
таблицы.
-
Проектирование
нормализованной БД.
Процесс в ходе, которого решается, какой
вид будет иметь созданная база данных,
называется проектированием базы
данных.
Работа по проектированию базы данных
включает реализацию следующих структур:
-
Базы данных;
-
Таблиц, которые будут входить в базу
данных; -
Столбцов, принадлежащих каждой таблице;
-
Взаимосвязей между таблицами и столбцами.
Процесс
преобразования отношений базы данных
к виду, отвечающему нормальным формам,
называется нормализацией. Нормализация
предназначена для приведения структуры
базы данных к виду, обеспечивающему
минимальную логическую избыточность,
и не имеет целью уменьшение или увеличение
производительности работы или же
уменьшение или увеличение физического
объёмаБД.
Конечной целью нормализации является
уменьшение потенциальной противоречивости
хранимой вБДинформации. Как отмечаетК.
Дейт, общее назначение процесса
нормализации заключается в следующем:
-
исключение
некоторых типов избыточности; -
устранение
некоторых аномалий обновления; -
разработка
проекта базы данных, который является
достаточно «качественным» представлением
реального мира, интуитивно понятен и
может служить хорошей основой для
последующего расширения; -
упрощение
процедуры применения необходимых
ограничений целостности.
Процесс
проектирования базы данных принято
разделять на три основные фазы:
-
— концептуальное
проектирование— построение модели
на основе информации, полученной при
изучении анализируемой области
независимо от ее реализации. Основой
модели является определение типов
важнейших сущностей и существующих
между ними связей. -
—
логическое проектирование—
преобразование концептуального
представления в логическую структуру
базы данных, включая проектирование
отношений; -
—
физическое проектирование—
создание описания конкретной реализации
базы данных (с помощью выбранной СУБД):
описание структуры хранения данных и
методов доступа.
-
Первая
нормальная форма.
Отношение
находится в первой нормальной форме
тогда и только тогда, когда в любом
допустимом значении отношения каждый
его кортежсодержит только одно значение для
каждого из атрибутов.
В реляционной
модели отношение всегда находится в
первой нормальной форме по определению
понятия отношение.
Что же касается
различных таблиц, то они могут не
быть правильными представлениями
отношений и, соответственно, могут не
находиться в 1NF. В соответствии с
определениемК.
Дж. Дейтадля такого случая,
таблица нормализована (эквивалентно —
находится в первой нормальной форме)
тогда и только тогда, когда она является
прямым и верным представлением некоторого
отношения. Конкретнее, рассматриваемая
таблица должна удовлетворять следующим
пяти условиям:
-
Нет
упорядочивания строк сверху-вниз. -
Нет
упорядочивания столбцов слева-направо. -
Нет
повторяющихся строк. -
Каждое
пересечение строки и столбца содержит
ровно одно значение из соответствующего
домена (и больше ничего). -
Все
столбцы являются обычными.
«Обычность»
всех столбцов таблицы означает, что в
таблице нет «скрытых» компонентов,
которые могут быть доступны только в
вызове некоторого специального оператора
взамен ссылок на имена регулярных
столбцов, или которые приводят к побочным
эффектам для строк или таблиц при вызове
стандартных операторов. Таким образом,
например, строки не имеют идентификаторов
кроме обычных значений потенциальных
ключей (без скрытых «идентификаторов
строк» или «идентификаторов объектов»).
Они также не имеют скрытых временных
меток.
-
Вторая
нормальная форма.
Вторая нормальная форма основана на
понятии полной функциональной зависимости.
Атрибут В называется полностью
функционально зависимым от атрибута
А, если атрибут В функционально зависит
от полного значения атрибута А и не
зависит от какого-либо подмножества
атрибута А. Отношение находится во 2НФ,
если оно находится в 1НФ и каждый его
атрибут, не входящий в состав первичного
ключа, функционально полно зависит от
первичного ключа. Другими словами,
второе правило нормализации требует,
чтобы любой неключевой столбец зависел
от всего первичного ключа, а не от его
отдельных компонентов. Это правило
относится к случаю, когда первичный
ключ образован из нескольких столбцов.
Первичные ключи всех таблиц из учебной
базы данных являются простыми (состоят
из одного столбца), поэтому все таблицы
находятся не только в 1НФ, но и однозначно
во 2НФ.
-
Третья
нормальная форма.
Третья нормальная форма основана на
понятии транзитивной зависимости. Если
для атрибутов А, В и С некоторого отношения
существуют зависимости С от В и В от А,
то говорят, что атрибут С транзитивно
зависит от атрибута А через атрибут В.
Отношение находится в 3НФ, если оно
находится в 1НФ и 2НФ, и в нем не существует
транзитивных зависимостей неключевых
атрибутов от первичного ключа. Другими
словами, третья нормальная форма требует,
чтобы ни один неключевой столбец не
зависел бы от другого неключевого
столбца. Любой неключевой столбец должен
зависеть только от столбца первичного
ключа.
-
Нормализация
на основе декомпозиции. Нормальная
форма Бойса — Кодда.
Нормальная форма Бойса-Кодда учитывает
функциональные зависимости, в которых
участвуют все потенциальные ключи
отношения, а не только его первичный
ключ. Для отношения с единственным
потенциальным ключом 3НФ и НФБК
эквивалентны. Отношение находится в
НФБК тогда и только тогда, когда каждый
его детерминант является потенциальным
ключом.
-
Четвертая
нормальная форма. Пятая нормальная
форма.
Четвертая нормальная форма связана
с понятием многозначной зависимости.
В случае многозначной зависимости,
существующей между атрибутами А, В и С
некоторого отношения, для каждого
значения А имеется набор значений
атрибута В и набор значений атрибута
С. Однако входящие в эти наборы значения
атрибутов В и С не зависят друг от друга.
Отношение находится в 4НФ, если оно
находится в НФБК и не содержит многозначных
зависимостей.
Пятой нормальной формойназывается
отношение, которое не содержит зависимостей
соединения. Зависимость соединения –
это такая ситуация, при которой
декомпозиция отношения может сопровождаться
генерацией ложных строк при обратном
соединении декомпозированных отношений
с помощью операции естественного
соединения.
-
Представление
связей. Рекурсивная связь.
Модель
Сущность-Связь(ER-модель)—модель
данных, позволяющая описыватьконцептуальные
схемы. Представляет собой графическую
нотацию, основанную на блоках и соединяющих
их линиях, с помощью которых можно
описывать объекты и отношения между
ними какой-либо другой модели данных.
В этом смысле ER-модель является
мета-моделью данных, то есть средством
описания моделей данных.
ER-модель
удобна при прототипировании (проектировании)
информационных систем, баз
данных, архитектур компьютерных
приложений, и других систем (далее,
моделей). С её помощью можно выделить
ключевые сущности, присутствующие в
модели, и обозначить отношения, которые
могут устанавливаться между этими
сущностями.
ER-модель
является одной из самых простых визуальных
моделей данных (графических нотаций).
Она позволяет обозначить структуру
«крупными мазками», в общих чертах.
Рекурсия(илирекурсивная связь) – это
связь класса сущностей с самим собой.
Иерархической
рекурсивной связью(или простоиерархической рекурсией)
называется любая рекурсивная связь
типа «не более одного ко многим».
Иерархическая рекурсия чаще всего
используется для того, чтобы хранить
данные древовидной структуры. При
задании иерархической рекурсивной
связи первичный ключ родительского
класса сущностей должен мигрировать в
качестве внешнего ключа в состав
обязательно неключевых атрибутов того
же класса сущностей. Все это необходимо
для поддержания логической целостности
самого понятия «иерархическая рекурсия».
Таким
образом, с учетом всего вышесказанного,
можно сделать вывод, что иерархическая
рекурсивная связь может быть только не
обязательно не идентифицирующейи никакой другой, потому что в случае
использования любого другого вида
связи, Null-значения для внешнего ключа
были бы недопустимы, и рекурсия была бы
бесконечной. Важно также помнить, что
атрибуты не могут появляться дважды в
одном и том же классе сущностей под
одним и тем же именем. Поэтому атрибуты
мигрировавшего ключа обязательно должны
получить так называемое имя роли.
Таким
образом, в иерархической рекурсивной
связи атрибуты узла расширяются внешним
ключом, представляющим необязательную
ссылку на первичный ключ узла, являющийся
его непосредственным предком.
Сетевая
рекурсивная связьклассов сущностей
между собой является как бы многомерным
аналогом иерархической рекурсивной
связи. Только если иерархическая рекурсия
определялась как рекурсивная связь
типа «не более одного ко многим», тосетевая рекурсияпредставляет
собой такую же рекурсивную связь, только
уже типа «многие ко многим». Связи вида
сетевой рекурсии предназначены для
представления графовых структур данных
(тогда как иерархические связи применяются,
как мы помним, исключительно для
реализации древовидных структур).
Но,
так как в связи вида сетевой рекурсии
заданы связи типа именно «многие ко
многим», без их дополнительной детализации
не обойтись. Поэтому для уточнения всех
имеющихся в схеме связей типа «многие
ко многим» становится необходимым
создать новый самостоятельный класс
сущностей, содержащий все ссылки на
предка или потомка связи «Предок –
Потомок». Такой класс в общем случае
называется классом ассоциативных
сущностей.
Таким
образом, первичный ключ класса сущностей,
представляющего узлы сети, должен дважды
мигрировать в классы ассоциативных
сущностей. В этом классе мигрировавшие
ключи в совокупности должны образовывать
составной первичный ключ. Из всего
вышесказанного можно сделать вывод,
что устанавливающие связи при использовании
сетевой рекурсии должны быть не полностью
идентифицирующими и никакими другими.
Так же как и при использовании иерархической
рекурсивной связи, при применении в
качестве связи сетевой рекурсии ни один
атрибут не может появляться дважды в
одном классе сущностей под одним и тем
же именем. Поэтому, как и в прошлый раз,
специально оговаривается, что все
атрибуты мигрирующего ключа обязательно
должны получить имя роли.
-
Преобразование
концептуальной модели в реляционную
модель.
Концептуальная
модель данных состоит из связанных
между собой сущностей. Основными
характеристиками сущности является
атрибут и ПК сущности. Связь характеризуется
степенью и классом принадлежности.
Существует алгоритм, по которому
концептуальная модель может быть
переведена в реляционную, причем
гарантирована по крайней мере 3НФ.
Преобразование
сущностей
1.
Каждой сущности ставится в соответствие
отношение.
2.
Каждый атрибут сущности становится
атрибутом отношения, которому приписывают
тип данных и свойство допустимости/недопустимости
для него значения NULL (не определен).
3.
Первичный ключ сущности становится ПК
отношения (PRIMARY KEY). Атрибуты, входящие
в ПК, получают свойство обязательности
(NOT NULL) и уникальности (UNIQUE).
Преобразование
связей
Преобразование
связи производится согласно значениям
ее характеристик:
1:1,
КЛАСС ПРИНАДЛЕЖНОСТИ (КП) ОБЕИХ СУЩНОСТЕЙ
ОБЯЗАТЕЛЬНЫЙ.
Требуется
одно отношение, его первичным ключом
может стать ключ любой из сущностей.
1:1,
КП ОДНОЙ СУЩНОСТИ ОБЯЗАТЕЛЬНЫЙ, ДРУГОЙ
— НЕОБЯЗАТЕЛЬНЫЙ. Требуется два отношения,
по одному на каждую сущность. Ключ каждой
сущности становится ПК соответствующих
отношений. Кроме того, ключ сущности, у
которой КП необязательный, добавляется
в качестве атрибута (FOREING KEY) в отношение,
выделенное для сущности с обязательным
КП. В отношение, выделенное для сущности
с обязательным КП, включаются также
атрибуты, принадлежащие связи (если они
есть).
1:1,
КП ОБЕИХ СУЩНОСТЕЙ НЕОБЯЗАТЕЛЬНЫЙ.
Требуется
три отношения, по одному на каждую
сущность, и отношение связи. Ключ каждой
сущности становится ПК соответствующих
отношений. Отношение связи содержит в
качестве ключевых атрибутов (FOREINGKEYS)
ключи обеих сущностей. В отношение связи
включаются также атрибуты, принадлежащие
связи (если они есть).
1:*,
КП МНОГОСВЯЗНОЙ СУЩНОСТИ ЯВЛЯЕТСЯ
ОБЯЗАТЕЛЬНЫМ.
Требуется
два отношения, по одному на каждую
сущность. Ключ каждой сущности становится
ПК соответствующих отношений. Кроме
того, ключ односвязной сущности
добавляется в качестве атрибута
(FOREINGKEY) в отношение, выделенное для
многосвязной сущности. Атрибуты связи
(если они есть) добавляются в таблицу
для многосвязной сущности.
1:*,
КП МНОГОСВЯЗНОЙ СУЩНОСТИ ЯВЛЯЕТСЯ
НЕОБЯЗАТЕЛЬНЫМ.
Требуется
три отношения, по одному на каждую
сущность, и отношение связи. Ключ каждой
сущности становится ПК соответствующих
отношений. Отношение связи содержит в
качестве ключевых атрибутов (FOREING KEYS)
ключи обеих сущностей. В отношение связи
включаются также атрибуты, принадлежащие
связи (если они есть).
*:*,
КП ОБЕИХ СУЩНОСТЕЙ НЕ ИМЕЕТ ЗНАЧЕНИЯ.
Требуется
три отношения, по одному на каждую
сущность, и отношение связи. Ключ каждой
сущности становится ПК соответствующих
отношений. Отношение связи содержит в
качестве ключевых атрибутов (FOREING KEYS)
ключи обеих сущностей. В отношение связи
включаются также атрибуты, принадлежащие
связи (если они есть).
ПРЕОБРАЗОВАНИЕ
РЕКУРСИВНЫХ СВЯЗЕЙ.
Отношение, имеющее рекурсивную связь,
в качестве ПК имеет ключ сущности, а
также включает в себя этот же ключ
сущности в качестве неключевого атрибута
(FOREING KEY).
-
Целостность
данных.
Для пользователей информационной
системы недостаточно, чтобы база данных
просто отражала объекты реального мира.
Важно, чтобы такое отражение было
однозначным и непротиворечивым. В этом
случае говорят, что база данных
удовлетворяет условию целостности. Для
того чтобы гарантировать корректность
и взаимную непротиворечивость данных,
на базу данных накладываются ограничения,
называющиеся ограничениями целостности.
Ограничения целостности (целостная
составляющая) реляционной модели можно
разделить на две группы – требование
целостности сущностей и требование
целостности ссылок. Первое из требований
— требование целостности сущности —
означает, что первичный ключ должен
полностью идентифицировать каждую
сущность, а поэтому не допускается
наличие неопределенных (null) значений в
составе первичного ключа. Требование
целостности сущностей также подразумевает
отсутствие полей с множественным
характером значений атрибута, что
обеспечивается нормализацией
таблиц-отношений. Требование целостности
ссылок заключается в том, что внешний
ключ не может быть указателем на
несуществующую строку в таблице, т.е.
для любой записи с конкретным значением
внешнего ключа должна обязательно
существовать связанная запись в
родительской таблице с соответствующим
значением первичного ключа.
-
Архитектура
клиент – сервер.
Архитектура «клиент-сервер» была
разработана с целью устранения
недостатков, имеющихся в модели файлового
сервера. «Клиент-сервер» – это модель
взаимодействия компьютеров в сети.
В
зависимости от того, как распределены
логические компоненты приложения между
клиентами и серверами, различают четыре
модели архитектуры клиент-сервер:
—
модель «файл-сервер»;
— модель
«сервер базы данных»;
— модель
«сервер транзакций»;
— модель
«сервер приложений».
Существуют два варианта архитектуры
«клиент-сервер»: традиционная двухуровневая
и трехуровневая, более пригодная для
работы в среде Web.
Двухуровневая
архитектура — архитектура приложения,
в которой прикладные и пользовательские
сервисы реализованы на клиентской
рабочей станции, а данные централизованно
хранятся на сервере. В этой модели
клиенты подключаются непосредственно
к серверу, на все время работы приложения.
Трёхуровневая архитектура предполагает
наличие следующих компонентов приложения:
клиентское приложение (обычно говорят
«тонкий
клиент» или терминал), подключенное
к серверу приложений, который в свою
очередь подключен к серверубазы
данных.
Основной
принцип технологии «клиент-сервер»
заключается в разделении функций
приложения на три группы:
-
ввод
и отображение данных (взаимодействие
с пользователем); -
прикладные
функции, характерные для данной
предметной области; -
функции
управления ресурсами (файловой системой,
базой даных и т.д.)
Поэтому,
в любом приложении выделяются следующие
компоненты:
-
компонент
представления данных -
прикладной
компонент -
компонент
управления ресурсом
Связь между компонентами осуществляется
по определенным правилам, которые
называют «протокол взаимодействия».
-
Язык
SQL.
Функции языка. Достоинства языка.
SQLявляется инструментом,
предназначенным для обработки и чтения
данных, содержащихся в компьютерной
базе данных.SQL- это
сокращенное название структурированного
языка запросов (StructuredQueryLanguage).
Как следует из названия,SQLявляется языком программирования,
который применяется для организации
взаимодействия пользователя с базой
данных. На самом делеSQLработает только с базами данных одного
определенного типа, называемых
реляционными.
Сейчас этот язык используется для
реализации всех функциональных
возможностей, которые СУБД предоставляет
пользователю, а именно:
-
Организация данных.SQLдает пользователю возможность изменять
структуру представления данных, а также
устанавливать отношения между элементами
базы данных. -
Чтение данных.SQLдает пользователю или приложению
возможность читать из базы данных
содержащиеся в ней данные и пользоваться
ими.
-
Обработка ванных.SQL
дает пользователю или приложению
возможность изменять базу данных, т.е.
добавлять в нее новые данные, а также
удалять или обновлять уже имеющиеся в
ней данные. -
Управление доступом.С помощьюSQLможно ограничить
возможности пользователя по чтению и
изменению данных и защитить их от
несанкционированного доступа. -
Совместное использование данных.SQLкоординирует совместное
использование данных пользователями,
работающими параллельно, чтобы они не
мешали друг другу. -
Целостность данных.SQLпозволяет обеспечить целостность базы
данных, защищая ее от разрушения из-за
несогласованных изменений или отказа
системы.
SQL —это
легкий для понимания язык и в то же время
универсальное программное средство
управления данными.
Успех языку SQLпринесли
следующие его особенности:
• независимость от конкретных СУБД;
• переносимость с одной вычислительной
системы на другую;
• наличие стандартов;
• одобрение компанией IBM(СУБДDB2);
• поддержка со стороны компании Microsoft(протоколODBC);
• реляционная основа;
• высокоуровневая структура, напоминающая
английский язык;
• возможность выполнения специальных
интерактивных запросов:
• обеспечение программного доступа к
базам данных;
• возможность различного представления
данных;
• полноценность как языка, предназначенного
для работы с базами данных;
• возможность динамического определения
данных;
• поддержка архитектуры клиент/сервер.
Все перечисленные выше факторы явились
причиной того, что SQLстал
стандартным инструментом для управления
данными на персональных компьютерах,
мини-компьютерах и больших ЭВМ
-
Перечислите
наиболее важные объекты Microsoft
SQL
Server.
-
Базы данных.
-
Индексы.
-
Журналы транзакций.
-
Сборки.
-
Таблицы.
-
Отчеты.
-
Файловые группы.
-
Каталоги полнотекстового поиска.
-
Диаграммы.
-
Определяемые пользователем типы данных.
-
Представления.
-
Роли.
-
Хранимые процедуры.
-
Пользователи.
-
Пользовательские функции.
-
Что
понимается под объектом базы данных
Microsoft
SQL
Server.
Любая база данных по существу представляет
собой объект наиболее высокого уровня,
доступ к которому можно получить с
помощью какой-либо конкретной СУБД SQLServer. Большая часть всех
прочих объектовSQLServer(но не все) являются дочерними по отношению
к объекту базы данных.
База данных, как правило,
представляет собой группу объектов,
которая включает по крайней мере набор
объектов таблиц, а также чаще всего
другие объекты, такие как хранимые
процедуры и представления, относящиеся
к определенной совокупности данных,
которые хранятся в таблицах базы данных.
-
Перечислите
системные базы данных, входящие в состав
СУБД.
Непосредственно после инсталляции СУБД
SQLServerв
состав программного обеспечения СУБД
входят следующие системные базы данных:
-
master- база данных содержит
специальный набор таблиц (системные
таблицы), которые позволяют отслеживать
функционирование всей системы. -
model- используется как
шаблон для любой вновь создаваемой
базы данных -
msdb- предназначена
исключительно для хранения информации
обо всех системных задачах, выполняемых
программойSQL Agent. -
tempdb- представляет собой
одну из основных рабочих областей для
сервера. После вызова на выполнение
любого сложного или крупного запроса,
для осуществления которого в СУБДSQLServerпотребуется создать
промежуточные таблицы, такие таблицы
создаются в базе данныхtempdb.
Для того чтобы сервер функционировал
должным образом, необходимо инсталлировать
все эти базы данных (в действительности
эксплуатация сервера без некоторых
из этих баз данных вообще невозможна).
Кроме указанных баз данных, могут быть
также установлены другие базы данных,
в зависимости от того, в каких целях
была выполнена инсталляция СУБД SQLServer. Чаще всего можно
встретить примеры применения следующих
баз данных:
-
AdventureWorks(образцовая база
данных); -
AdventureWorksDW(образец базы
данных, применяемый в сочетании со
службамиAnalysisServices).
Дополнительно к этим базам данных,
которые могут быть установлены в
процессе инсталляции системы
рассматриваются также образцовые базы
данных, относящиеся к более старым
версиям, которые перечислены ниже.
-
pubs- предназначена
исключительно для использования в
качестве постоянной отправной точки
для обучения и экспериментирования.
-
Northwind-
-
Дайте
определение журналу транзакций.
Функционирование СУБД организовано
так, что запись модифицированных данных
не осуществляется непосредственно в
файл базы данных. Безусловно, данные
считываются из файлов базы данных, но
любые изменения и дополнения в данных
не передаются сразу же в саму базу
данных. Вместо этого информация обо
всех изменениях и дополнениях
записывается в журнал транзакций. В
какой-то последующий момент времени
применительно к базе данных выполняетсяконтрольная точка, и в этот момент
времени все изменения и дополнения,
зафиксированные в журнале, переносятся
в физический файл (файлы) базы данных.
База данных представляет собой среду
произвольного доступа, а журнал по своей
организации является последовательным.
Дело в том, что благодаря возможности
применения к файлу базы данных операций
произвольного доступа выборка данных
ускоряется, а благодаря последовательному
устройству журнала обеспечивается
отслеживание операций обновления и
вставки данных в должном порядке. Журнал
накапливает информацию об изменениях
и дополнениях, которые предназначены
для дальнейшей фиксации, а затем время
от времени осуществляется запись части
накопленной информации в физический
файл (файлы) базы данных
-
Охарактеризуйте
таблицу как основной компонент базы
данных. Дайте определение индексу.
Какие категории индексов вам известны?
Базы данных состоят из объектов многих
разных типов, но ни один из этих объектов
не является более важным для организации
работы базы данных, чем таблица. Таблицу
можно рассматривать как электронные
таблицы Excel. Таблица
состоит из так называемых данных
заголовка (определений столбцов) и
данных тела (самих строк). Все прикладные
данные базы данных хранятся в таблицах.
Определение каждой таблицы содержит
не только определения столбцов, но и
метаданные (информацию, характеризующую
данные), которые определяют характер
данных, содержащихся в таблице. Определение
каждого столбца представляет собой
отдельный набор правил, касающийся
того, что может храниться в этом столбце.
Попытка нарушить правила, относящиеся
к любому столбцу, может вынудить систему
запретить выполнение операции вставки
строки или обновления существующей
строки или же предотвратить удаление
строки.
Индекс — это объект, который
существует только в пределах инфраструктуры
конкретной таблицы или представления.
Индекс во многом аналогичен индексу
(предметному указателю) научной
книги. Он представляет собой набор
поисковых (или ключевых) значений,
отсортированных определенным образом.
После создания индекса появляется
возможность использования его в качестве
ключа для поиска требуемой информации.
Индексы предназначены прежде всего для
ускорения поиска информации. Индексы,
применяемые в СУБД SQLServer, подразделяются на
две описанные ниже категории.
Кластеризованный. На каждой таблице
может быть задан только один
кластеризованный индекс. Если на
таблице задан кластеризованный индекс,
это означает, что строки таблицы с
кластеризованным индексом отсортированы
физически в соответствии с этим индексом.
Например, если как индекс рассматривается
предметный указатель научной книги, то
подобный кластеризованный индекс
состоит из номеров страниц, поскольку
они показывают местонахождение
различных сведений в научной книге на
конкретных страницах.
Некластеризованный. На каждой
таблице может быть задано несколько
не-кластеризованных индексов. Определение
индекса этого типа еще больше соответствует
тому, что представляет собой предметный
указатель научной книги, поскольку
индекс такого типа содержит информацию
о дополнительных критериях, которые
могут применяться для поиска данных.
Применительно к рассматриваемому
примеру с научной книгой в качестве
индекса может рассматриваться
предметный указатель, состоящий из
ключевых слов.
Следует отметить, что представления,
имеющие индексы (называемые также
индексированными представлениями),
должны иметь по меньшей мере один
кластеризованный индекс, чтобы можно
было определить на представлениях
какие-либо некластеризованные индексы.
-
Что
такое ядро базы данных? Что такое
устройство баз данных?
Ядро базы данныхявляется сердцевиной
СУБД, оно отвечает за физическое
структурирование и запись данных на
диск, а также за физическое чтение данных
с диска. Кроме того, оно принимает
SQL-запросыот других компонентов
СУБД, от пользовательских приложений
и даже от других вычислительных систем.

Базы данных размещаются на устройствах.
Устройства – это файлы жесткого диска,
которые помимо БД могут содержать
журналы транзакций и резервные копии
БД. Одна БД может размещаться на нескольких
устройствах, разнесенных по нескольким
жестким дискам. Одно устройство может
включать в себя несколько баз данных
или их фрагментов. Устройство, даже не
содержащее ни одной базы данных, тем не
менее занимает место на диске. Минимальный
размер устройства – 1 Мб.
-
Приведите
синтаксис команды создания устройства.
Таблицы – главное хранилище информации
на сервере. Их размещение обычно начинают
с создания устройства, которое будет
обслуживать необходимые БД. Размер
устройства в дальнейшем можно будет
изменить.
В процессе установки MicrosoftSQLServerавтоматически создаются 3 устройства
баз данных –MASTER.DAT,MSDB.DAT,MSDBLOG.DAT. Все
остальные устройства создает администратор.
Вот синтаксис команды создания устройства:
Материалы к экзамену
по учебной дисциплине
«Базы данных»
Пояснительная записка
Цель: оценка уровня освоения
учебной дисциплины «Базы данных».
В результате изучения студент
должен:
иметь представление:
·
о роли и
месте знаний по дисциплине при освоении смежных дисциплин по выбранной
специальности и в сфере профессиональной деятельности;
знать:
·
состав
информационной модели данных;
·
типы
логических моделей;
·
этапы
проектирования базы данных;
·
общую
теорию проектирования прикладной программы;
уметь:
·
строить
информационную модель данных для конкретной задачи;
·
выполнять
нормализацию базы данных;
·
подбирать
наилучшую систему управления базами данных (СУБД);
·
проектировать
прикладную программу.
Форма экзамена: устный опрос, выполнение
практического задания.
Структура экзаменационного билета:
Экзаменационный билет содержит два
вопроса: первый вопрос – теоретический вопрос, второй вопрос – выполнение
практического задания.
Разделы учебной дисциплины, выносимые
на экзамен:
·
Теория
проектирования баз данных.
·
Организация баз данных.
·
Организация
интерфейса с пользователем.
·
Организация
запросов SQL.
Критерии и нормы оценки:
Оценка за экзамен ставится как
среднее арифметическое двух оценок (одна оценка за теоретический вопрос и одна –
за практическое задание).
Критерии и нормы оценки за устный опрос:
Оценка «отлично» ставится, если студент
показал полный объем, высокий уровень и качество знаний по данному вопросу,
владеет культурой общения и навыками научного изложения материала,
устанавливает связь между теоретическими знаниями и способами практической
деятельности; ясно, точно и логично отвечает на заданные вопросы.
Оценка «хорошо» ставится, если студент логично
и научно изложил материал, но недостаточно полно определяет практическую
значимость теоретических знаний; не высказывает своей точки зрения по данному
вопросу, не смог дать достаточно полного ответа на поставленные вопросы.
Оценка «удовлетворительно» ставится, если студент
при раскрытии вопроса допустил содержательные ошибки, не соотнес теоретические
знания и собственную практическую деятельность, испытывает затруднения при
ответе на большинство вопросов.
Оценка
«неудовлетворительно» ставится, если студент показал слабые теоретические и
практические знания, допустил грубые ошибки при раскрытии вопроса, не смог
ответить на заданные вопросы.
Критерии и нормы оценки за практическое задание:
Оценка
«отлично»
ставится, если студент выполнил работу в
полном объеме с соблюдением необходимой последовательности действий; проводит работу в условиях, обеспечивающих
получение правильных результатов и выводов; соблюдает правила техники
безопасности; в ответе правильно и аккуратно выполняет все записи, вычисления; правильно выполняет анализ ошибок.
Оценка
«хорошо»
ставится, если выполнены требования к оценке отлично, но допущены 2-3 недочёта,
не более одной ошибки и одного недочёта.
Оценка «удовлетворительно» ставится, если работа выполнена не
полностью, но объем выполненной части таков, что позволяет получить правильные
результаты и выводы; в ходе проведения
работы были допущены ошибки.
Оценка «неудовлетворительно»
ставится, если
работа выполнена не полностью и объем выполненной работы не позволяет сделать
правильных выводов; работа проводилась неправильно.
Оборудование
и программное обеспечение:
1. Персональный
компьютер.
2. Программное
обеспечение: MS Office
Access 2007.
3. Готовые базы
данных:
·
Фирма,
торгующая комплектующими для компьютеров.accdb;
·
Фирма.accdb;
·
Кинотеатр.accdb;
·
Flats.mdb;
·
Notes.mdb;
·
Kosmos.mdb.
Вопросы к экзамену по учебной
дисциплине «Базы данных»
1.
Базы
данных: понятие, примеры, классификация.
2.
Модель
данных: понятие, примеры, типы, схемы.
3.
Связи в
моделях данных: типы, схемы, примеры.
4.
Сущность:
понятие, типы, источники информации о сущностях.
5.
Ключи и
реляционный подход к построению модели: понятие ключ, классификация,
назначение, примеры, суть подхода.
6.
Требования, предъявляемые к проектируемой
базе данных.
7.
Суть теоретической разработки базы данных.
8.
Этапы проектирования базы данных.
9.
Системы управления базами данных: понятие,
назначение, функции, классификация, отличительные особенности.
10. Основные компоненты и типы
данных системы управления базами
данных.
11.
Алгоритм проектирования базы данных.
12.
Способы и алгоритм создания таблиц базы
данных.
13. Алгоритм
управления записями в базе данных: добавление, редактирование, удаление и
навигация.
14. Индексы: понятие, типы,
функции, достоинства и недостатки, алгоритм создания простого индекса, выбор
полей для индексирования.
15. Сортировка данных: понятие,
алгоритм сортировки данных.
16. Способы поиска информации в
базе данных: виды, алгоритмы поиска данных.
17.
Взаимосвязи между таблицами: условия для установления
взаимосвязи, способы
объединение таблиц, алгоритм
установления и удаления взаимосвязей между таблицами.
18.
Создание
программных файлов: операторы цикла и ветвления.
19. Модульность программ. Область
действия переменных.
20. Типы меню: классификация,
алгоритм создания.
21. Работа с окнами: основные
понятия, характеристики, режимы работы, создание и управление рабочим окном.
22. Объект базы данных: понятие,
типы, характеристики, класс и подкласс объекта.
23. Полиморфизм, инкапсуляция и
наследование объекта базы данных.
24. Форма как специальный объект:
понятие, способы и алгоритм создания, редактирование.
25. Элементы управления: понятие,
свойства, классы, события и методы.
26. Запросы к базе данных:
понятие, виды, отличительные особенности, назначение.
27. Запросы к базе данных:
принципы организации запросов, алгоритмы составления и редактирования запросов.
28. Отчёты к базе данных:
понятие, виды, отличительные особенности, назначение.
29. Отчёты к базе данных: способы
формирования отчетов, алгоритмы составления и редактирования отчётов.
30. Хранимые процедуры и триггеры
в базе данных: понятие, назначение.
31. Обеспечение достоверности,
целостности и непротиворечивости данных. Каскадные воздействия.
32.
Практические задания к
экзамену по учебной дисциплине «Базы данных»
1.
Разработайте
базу данных «Сотрудники» с использованием следующих типов полей: счётчик, текстовое,
дата/время, денежный. Заполните текстовыми данными.
Для работы потребуются следующие сведения: номер сотрудника,
организация, фамилия, имя, отчество, должность, дата рождения, зарплата.
2.
Создайте
таблицы базы данных:
1.
Поставщики
(КодП, Название);
2. Товары (КодТ, Наименование, ед. изм., КодП);
3. Закупки (№п/п, КодТ, Дата, цена, количество).
Установите реляционные отношения между таблицами. Заполните
текстовыми данными.
3.
Создайте
базу данных для фирмы, торгующей комплектующими для компьютеров в виде 3-х
таблиц:
1. Таблица1 – «Продажи»,
характеризуется атрибутами: Учетный № (тип счетчик), Дата заказа (Дата/время),
Номер заказа (тип текстовый), Артикул (уникальный номер единицы товара, тип
текстовый).
2. Таблица2 – «Комплектующие»
включает атрибуты: Артикул (тип текстовый), Наименование (тип текстовый),
Описание комплектующих (тип текстовый).
3. Таблица3 – «Цены»
характеризуется атрибутами: Артикул (тип текстовый), Цена (тип числовой),
Скидка (тип числовой).
В таблицах
Комплектующие и Цены в качестве ключевого поля используйте атрибут артикул.
Таблица Продажи не должна иметь ключевого поля.
Для создания
таблиц используйте режим конструктора.
Введите 4 записи
в таблицу Комплектующие. Таблицу Цены заполните с помощью мастера подстановки,
используя артикул из таблицы Комплектующие. В таблицу Продажи введите 6
записей. Сохраните базу данных под именем Фирма, торгующая комплектующими для
компьютеров.accdb.
4. Для базы данных Фирма,
торгующая комплектующими для компьютеров.accdb создайте формы для заполнения каждой таблицы с помощью мастера форм и дополните
по 3 записи в формы. Количество записей в таблице Продажи должно превышать
количество записей в таблицах Комплектующие и Цены. В таблице Продажи должны
быть записи с одинаковыми артикулами.
5. В базе данных Фирма,
торгующая комплектующими для компьютеров.accdb, дополните предложенные таблицы и установите связи между таблицами. Эта
база данных включает в себя три отношения: Продажи, Комплектующие и Цены. Эти
отношения связать через атрибут Артикул. Для отношения Продажи это связь
«многие-к-одному».
6. В базе данных Фирма,
торгующая комплектующими для компьютеров.accdb, дополните предложенные таблицы и создайте запрос на выборку, который
должен содержать данные о наименовании и стоимости комплектующих по заказу 2 (в
режиме Конструктор запросов).
7. В базе данных Фирма,
торгующая комплектующими для компьютеров.accdb, дополните предложенные таблицы и составьте отчет по таблицам с помощью
мастера отчетов.
8. В базе данных Фирма,
торгующая комплектующими для компьютеров.accdb, дополните таблицы и создайте запрос вычисления суммарной стоимости
комплектующих одного наименования.
9.
Спроектируйте
БД в MS Access «Фирма».
Создайте таблицы:
1. Сотрудники (код сотрудника, фамилия, имя, отчество,
должность, телефон, адрес, дата рождения, заработная плата).
2. Клиенты (код клиента, название компании, адрес, номер
телефона, факс, адрес электронной почты).
3. Заказы (код заказа, код клиента, код сотрудника, дата
размещения, дата исполнения, сумма, отметка о выполнении).
Установите реляционные отношения между таблицами. Заполните
текстовыми данными.
10.
Создайте
запросы в СУБД MS Access. БД «Фирма»:
1. Запрос 1, в котором можно просмотреть телефоны сотрудников.
Сохраните запрос под именем «Телефоны».
2. Запрос 2, в котором можно просмотреть список сотрудников,
родившихся в апреле месяце. Сохраните запрос под именем «Апрель».
3. Измените запрос «Апрель» так, чтобы при его открытии появилось
диалоговое окно с текстом «Введите дату» и полем для ввода условия отбора.
4. Измените запрос «Телефоны» так, чтобы при его запуске
выводилось диалоговое окно с сообщением «Введите фамилию».
11.
Создайте
запросы в СУБД MS Access. БД «Фирма»:
1.
Запрос
«Выполненные заказы», содержащий следующие сведения: фамилия и имя сотрудника,
название компании, с которой он работает, отметка о выполнении и сумма заказа.
Данные запроса возьмите из нескольких таблиц.
2.
Запрос «Сумма
заказа», в котором будут отображаться заказы на сумму более 50 000 руб.
3.
Измените
запрос «Сумма заказа», чтобы сумма заказа была от 20 000 до 50 000 руб.
4.
В запросе
«Сумма заказа» посчитайте подоходный налог 13 % для каждой сделки.
12. Создайте в базе данных «Фирма» с
помощью Мастера формы Сотрудники, Клиенты, Заказы. В режиме конструктора
создайте на форме кнопки Выход из приложения, Поиск записи, Удаление записи. Данную
форму сохраните с именем Сотрудники фирмы.
13. Создайте в базе данных «Фирма» кнопочную
форму.
14. Разработайте СУБД «Абитуриент» для
автоматизации работы приемной комиссии колледжа. БД должна содержать три
таблицы: анкеты абитуриентов, данные о дисциплинах и результаты экзаменов.
Таблица «Анкеты абитуриентов»
включает следующие данные об абитуриенте:
·
регистрационный
номер (ключевое поле);
·
фамилия,
имя, отчество;
·
дата
рождения;
·
наличие
красного диплома или золотой/серебряной медали;
·
адрес
(город, улица, номер дома, телефон);
Таблица «Данные о дисциплинах: содержит:
·
шифр
дисциплины (ключевое поле).
·
название
дисциплины;
Таблица «Результаты экзаменов»
содержат:
·
регистрационный
номер абитуриента;
·
шифр
дисциплины;
·
экзаменационная
оценка.
Установите реляционные отношения между таблицами. Заполните
текстовыми данными.
15.
По данной
схеме данных создайте и заполните базу данных «Расписание»:

16.
По данной
схеме придумайте базу данных, создайте её и заполните соответствующими данными.

17.
Создайте базу
данных КИНОТЕАТР. База данных содержит следующие таблицы:
·
КИНОТЕАТРЫ:

·
ЗАЛЫ:

·
ФИЛЬМЫ:

·
СЕАНСЫ:

Заполните таблицу КИНОТЕАТРЫ данными:

Создайте схему данных, в которой
между таблицами установлены связи:


Заполните таблицу
ЗАЛЫ данными:

Для ввода данных
в таблицу ФИЛЬМЫ создайте автоформу в столбец АФИША.
С помощью формы АФИША
заполните таблицу ФИЛЬМЫ данными, ориентируясь на сопроводительные
карточки.
Для таблицы СЕАНСЫ
создайте одноименную автоформу. Заполните таблицу СЕАНСЫ данными на
свое усмотрение согласно правилам:
·
в разных
залах одного и того же кинотеатра в одно и то же время идут разные
фильмы;
·
для
неработающих залов сеансы не указывать;
·
для
заполнения выберите какой-нибудь один день.
18.
В базе
данных КИНОТЕАТР создайте следующие запросы:
·
Запрос
01КОМЕДИЯ на выборку всех фильмов комедийного жанра. В результирующую таблицу
включите все поля таблицы ФИЛЬМЫ.
·
Запрос
01КОМЕДИЯ на выборку всех фильмов комедийного жанра. В результирующую таблицу
включите все поля таблицы ФИЛЬМЫ.
·
Запрос 03СЕАНС10
на выборку всех фильмов, идущих во всех кинотеатрах на сеансе 10:00. В
результирующую таблицу включите поля Время, Фильм из таблицы СЕАНСЫ и поле
Название из таблицы КИНОТЕАТРЫ.
·
Запрос
11ГОД, определяющий количество фильмов каждого года выпуска (по таблице
ФИЛЬМЫ).
19. Создайте БД «Видеотека», содержащую следующие
поля: номер диска, название фильма, жанр, продолжительность, страна, дата
приобретения. Определите первичный ключ. Заполните БД следующими данными:
|
Номер |
Название фильма |
Жанр фильма |
Длительность фильма |
Страна |
Дата поступления |
|
1 |
Пятый элемент |
фантастика |
125 |
США |
31.01.2002 |
|
2 |
Титаник |
мелодрама |
185 |
США |
20.02.2004 |
|
3 |
Кавказская пленница |
комедия |
100 |
Россия |
28.02.2001 |
|
4 |
Драйв |
боевик |
115 |
США |
31.01.2005 |
|
5 |
По прозвищу Зверь… |
боевик |
85 |
Россия |
28.02.2004 |
|
6 |
Профессионал |
боевик |
125 |
Франция |
25.05.2005 |
|
7 |
Игрушка |
комедия |
85 |
Франция |
22.04.2006 |
|
8 |
Танцор диско |
мелодрама |
130 |
Индия |
14.04.2004 |
|
9 |
Патруль времени |
фантастика |
102 |
США |
28.02.2005 |
|
10 |
Только сильнейшие |
боевик |
96 |
США |
30.09.2006 |
Создайте:
·
запрос, с помощью которого на экран
будет выведено название, жанр и длительность для всех фильмов, произведённых в России
и США, отсортировав их по ключу «Страна (возр.)+название (убыв)»;
·
запрос для вывода на экран всех
фильмов, поступивших в видеотеку в 2004 и 2005 году. Данные отсортируйте по дате
поступления (по возрастанию).
20.
В музее имеется коллекция старинных монет, когда-то имевших хождение
в Беларуси. Масса каждой монеты известна. Определите, сколько золота и серебра
хранится в коллекции, для этого создайте файл базы данных Монета.accdb и создайте
итоговый запрос.
|
Название монеты |
Страна |
Материал |
Масса |
|
Денарий |
Рим |
серебро |
29 |
|
Дирхем |
Восток |
серебро |
27,2 |
|
Дукат |
Италия |
золото |
3,537 |
|
Златник |
Русь |
золото |
3,5 |
|
Империал |
Россия |
золото |
0,1 |
|
Милиарисий |
Византия |
серебро |
24,7 |
|
Полтинник |
Россия |
золото |
2,015 |
|
Полторак |
Речь Посполитая |
серебро |
11,61 |
|
Рубль |
Россия |
серебро |
4,68 |
|
Солид |
Рим |
золото |
0,72 |
|
Сребренник |
Россия |
серебро |
4,55 |
|
Талер |
Польша, Чехия |
серебро |
4,55 |
|
Третьяк |
Польша |
серебро |
4,2 |
|
Трояк |
Польша |
серебро |
4 |
|
Флорен |
Флоренция |
золото |
0,2 |
21.
Для файла базы данных Flats.mdb сформируйте условия
запроса, содержащие критерии отбора для вывода данных:
·
квартир, построенных после 1990 года;
·
всех однокомнатных квартир;
·
квартир дешевле 12000;
·
всех квартир с телефонами и балконами;
·
квартир, расположенных ниже пятого этажа и с общей площадью не
менее 50 м2;
·
квартир, находящихся на улице Слободская;
·
всех квартир, кроме расположенных на первом этаже.
22. Для файла базы
данных Notes.mdb сформируйте условия
запроса, с помощью которых из базы будут выбраны:
·
друзья, родившиеся в ноябре;
·
друзья с именем Андрей;
·
друзья, увлекающиеся музыкой или поэзией;
·
друзья, фамилии которых начинаются на букву «К»;
·
друзья, увлекающиеся спортом и родившиеся в 1987 году.
23. В файле базы
данных Kosmos.mdb сформируйте запросы,
после выполнения которых будут выведены на экран следующие записи:
·
о кораблях, совершивших 48 витков вокруг Земли;
·
о кораблях, летавших в октябре;
·
о кораблях «Союз», совершивших более 50 витков вокруг
Земли;
·
о полетах, совершенных Николаевым А. Г.;
·
о полетах, совершенных Комаровым В. И. и Волковым В. Н.
24. Для файла базы
данных Flats.mdb создайте кнопочную
форму.
25. Для файла базы
данных Notes.mdb создайте форму и отчёт.
26.
По данной
схеме данных создайте и заполните базу данных «Деканат»:

27.
В файле
базы данных Kosmos.mdb дополните таблицу данными, создайте
форму и отчёт.
28. Создайте базу данных «Лесничество»,
согласно следующим требованиям:
·
база данных состоит из четырех таблиц:
Список посадок, Список сел, Список видов и Список типов; соответствующие поля в таблицах Список
посадок и Список видов должны быть полями подстановок из других таблиц;
·
таблица Список посадок состоит из пяти полей: Посадка, Село, Площадь, Вид, Возраст. Поле Посадка является ключом. Таблица Список сел имеет поля: Село и Лесник, таблица Список видов — поля Вид
и Тип. В указанных таблицах поля Село и Вид
являются ключевыми. В таблице Список типов только одно поле Тип.
Создайте схему данных в соответствии с
рисунком.

Заполните таблицы Список сел, Список типов, Список видов, используя
следующие данные:
Список типов:
§ хвойные,
§
лиственные.
Список видов:
§ ель (хвойные),
§ сосна (хвойные),
§ береза (лиственные),
§ дуб (лиственные),
§ осина (лиственные),
§ клен (лиственные),
§ липа (лиственные),
§ кедр (хвойные),
§ пихта (хвойные),
§
граб (лиственные).
Список сел:

29.
По данной
схеме данных создайте и заполните базу данных «ЖКХ»:

30. Создайте базу данных
«Продукты». Данные для заполнения таблицы «Показатели качества конфет».
|
Код |
Наименование |
Калорийность |
Начинка |
Срок |
Производитель |
|
1 |
«Беловежская |
383 |
желейная |
4 |
«Коммунарка» |
|
2 |
«Березка» |
526 |
пралиновая |
2 |
«Коммунарка» |
|
3 |
«Коровка-неженка» |
364 |
глазированная |
6 |
ОАО |
|
4 |
«Лиса-плутовка» |
410 |
помадная |
1 |
«Коммунарка» |
|
5 |
«Желейная |
361 |
желейная |
4 |
ОАО |
|
6 |
«Красная |
529 |
глазированная |
12 |
«Спартак» |
|
7 |
«Сладкая |
369 |
помадная |
4 |
ОАО |
|
8 |
«Рябиновая |
358 |
желейная |
4 |
«Коммунарка» |
|
9 |
«Вишенка» |
512 |
помадная |
12 |
«Спартак» |
Создайте запросы
на выборку, выделяя условия отбора.
1.
Наименование
конфет, начинка помадная, запросу присвоить имя Начинка.
2.
Наименование
конфет, с желейной начинкой и производитель «Коммунарка», запросу присвоить имя
Начинка — Производитель.
3.
Наименование
конфет, производитель ОАО «Ивкон» и калорийность меньше 500, запросу присвоить
имя Калорийность — Производитель.
31.
Создайте
базу данных «Экзаменационная сессия» содержащую информацию о сдаче студентами
экзаменов. База данных должна содержать следующую информацию:
•
Таблицу
«Студенты», содержащую следующую информацию о студентах: ФИО, Группа, Номер
телефона.
•
Таблицу
«Группы», содержащую следующую информацию о группах: Имя группы, Количество
человек, Староста.
•
Таблицу
«Преподаватели», содержащую информацию о преподавателях: ФИО преподавателя,
Звание, Кафедра, Дисциплина.
•
Таблицу
«Дисциплины», содержащую информацию о дисциплинах: Название, Преподаватель.
•
Таблицу
«Экзамены», содержащую следующую информацию об экзаменах: Дисциплина, Группа,
Дата, Студент, Оценка.
Определить первичные и вторичные (внешние) ключи (если
необходимо добавьте поля). Ввод в поля с небольшим набором возможных значений
организуйте с помощью полей подстановки, а также предусмотрит маску ввода, где
это возможно.
Установите связь между таблицами, предусмотрев обеспечение
целостности данных, каскадное обновление связанных полей и каскадное удаление
связанных записей.
Введите не менее 4 записей в таблицы.
Создайте запрос, задав для него смысловое имя, отображающий
информацию о студентах, получивших оценку 5 хотя бы за один экзамен (на экран
вывести следующие поля: ФИО, Группа, Дата, Название дисциплины, Преподаватель,
Оценка).
Вопросы к экзамену. Вопросы к экзамену по дисциплине Базы данных
|
Единственный в мире Музей Смайликов |
|

 Скачать 45 Kb.
Скачать 45 Kb.
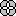 С этим файлом связано 1 файл(ов). Среди них: Курсовая работа.docx.
С этим файлом связано 1 файл(ов). Среди них: Курсовая работа.docx.
Показать все связанные файлы
Подборка по базе: Контрольная работа № 1 по дисциплине ‘Криминалистика’_ Контрольн, ОТВЕТЫ НА ВОПРОСЫ (30ВОПРОСОВ).docx, Бух учет вопросы.docx, Контрольные вопросы к зачету.docx, тестовые вопросы к разделу 5 экономика.docx, Физическая культура (ДО, ПНК, ПДО, 4 часть) тестовые вопросы к р, МУ к курсовой работе по дисциплине конституционное право России., Краткий курс лекций по дисциплине %22Основы проектирования баз д, 1-30 вопросы диф зачета.docx, 1-30 вопросы диф зачета.docx
Вопросы к экзамену по дисциплине «Базы данных»
- Базы данных: основные понятия. Введение в базы данных. Определения.
- Развитие технологий обработки данных. Современное состояние технологий баз данных.
- Базы данных и их свойства.
- Системы управления базами данных. Компоненты среды СУБД.
- Архитектура СУБД. Трехуровневая архитектура базы данных. Внешний уровень. Концептуальный уровень. Внутренний уровень.
- Функции СУБД. Управление данными во внешней памяти. Управление транзакциями. Восстановление базы данных.
- Функции СУБД. Поддержка языков БД. Словарь данных. Управление параллельным доступом. Управление буферами оперативной памяти.
- Функции СУБД. Контроль доступа к данным. Поддержка обмена данными. Поддержка целостности данных. Поддержка независимости от данных. Вспомогательные функции.
- Типовая организация современной СУБД.
- Языки баз данных. Язык определения данных. Языки манипулирования данными.
- Архитектура многопользовательских СУБД. Тенденции развития многопользовательских систем.
- Модели двухуровневой технологии «клиент-сервер». Файловый сервер. Модель удаленного доступа к данным.
- Модель сервера баз данных. Сервер приложений. Трехуровневая модель.
- Проектирование баз данных. Концепции проектирования. Жизненный цикл БД.
- Планирование разработки базы данных. Определение требований к системе. Сбор и анализ требований пользователей.
- Проектирование базы данных. Концептуальное проектирование базы данных. Логическое проектирование базы данных. Физическое проектирование базы данных.
- Разработка приложений. Загрузка данных. Тестирование. Эксплуатация и сопровождение.
- Концептуальное проектирование. Фундаментальные понятия. Объекты. Атрибуты. Ключи.
- Связи между объектами. Показатель кардинальности. Степень участия. Рекурсивная связь.
- Пример моделирования локальной ПрО.
- Специализация и генерализация. Категоризация. Составные объекты.
- Модели данных. Классификация моделей данных. Объектные модели данных. Модели данных на основе записей. Физическая модель данных.
- Сетевая модель. Структуры данных сетевой модели. Сетевой граф БД.
- Преобразование концептуальной модели в сетевую. Реализация наборов. Управляющая часть сетевой модели.
- Иерархическая модель данных. Структурная часть иерархической модели.
- Преобразование концептуальной модели в иерархическую модель данных.
- Управляющая часть иерархической модели. Описание данных. Манипулирование данными. Ограничения целостности.
- Достоинства и недостатки ранних СУБД.
- Реляционная модель данных. История вопроса. Структурная часть реляционной модели. Реляционное отношение. Свойства и виды отношений. Реляционные ключи.
- Обновление отношений. Целостность базы данных. Проектирование базы данных. Последовательная нормализация. Избыточность данных в БД.
- Аномалии обновления в базе данных. Аномалии включения. Аномалии удаления. Аномалии модификации.
- Процесс нормализации. Функциональные зависимости и ключи. Первая нормальная форма.
- Вторая нормальная форма. Третья нормальная форма.
- Нормализация на основе декомпозиции. Недостатки данной нормализации.
- Четвертая нормальная форма. Пятая нормальная форма.
- Проектирование реляционной базы данных. Логическое проектирование реляционной БД. Упрощение концептуальной модели данных.
- Методика преобразования концептуальных структур данных в реляционные структуры.
- Преобразование объектов и атрибутов. Преобразование бинарных связей. Преобразование связи типа «суперкласс/подкласс».
- Предварительные отношения для бинарных связей типа M:N. Преобразование составных объектов. Преобразование тернарных связей. Преобразование рекурсивных связей.
- Проверка модели с помощью концепций последовательной нормализации. Проверка модели в отношении транзакций пользователей. Проверка поддержки целостности данных.
- Управление реляционной базой данных.
- Реляционная алгебра. Основные операции реляционной алгебры. Дополнительные операции реляционной алгебры.
- Реляционное исчисление. Целевой список и определяющее выражение. Формулы исчисления кортежей. Квантор существования. Квантор всеобщности
- Язык SQL. Исторические аспекты развития SQL. Структура и типы данных языка SQL. Операторы языка SQL.
- Оператор выбора SELECT. Формирование запросов к базе данных. Агрегатные функции языка. Группирование результатов. Вложенные запросы.
- Оператор выбора SELECT. Многотабличные запросы. Множественные операции реляционной алгебры. Открытые соединения.
- Встроенный SQL. Однострочные и многострочные запросы.
- Управление транзакциями. Модель транзакции. Свойства транзакции. Журнализация. Проблемы многопользовательских систем. Блокировки.
- Триггеры. Основные сведения. Создание триггера. Триггер удаления.
- Хранимые процедуры. Назначение хранимых процедур. Создание и использование хранимых процедур.
- Администрирование баз данных. Управление учетными записями и правами доступа в MS SQL Server. Резервное копирование и восстановление баз данных.
|
Одобрено ПЦК «Техническое обслуживание средств Протокол № ______ от ___________ Председатель ПЦК ________________ К. Н. Зубкова |
Утверждаю Заместитель директора __________________ |
? 1
Банк данных это:
-комплекс языковых и программных средств, предназначенных
для создания, ведения и совместного использования БД многими пользователями
-разновидность ИС предназначенная для централизованного
хранения информации о структурах данных
-разновидность ИС, в которой реализованы функции
централизованного хранения и накопления обрабатываемой информации,
организованной в одну или несколько баз данных
-нет правильного ответа
? 2
База данных представляет собой:
-программу или комплекс программ, обеспечивающих
автоматизацию обработки информации для прикладной задачи
-комплекс языковых и программных средств
-совокупность специальным образом организованных данных,
хранимых в памяти вычислительной системы и отображающих состояние объектов
-нет правильного ответа
? 3
Система управления базами данных это:
-разновидность ИС, в которой реализованы функции
централизованного хранения и накопления обрабатываемой информации
-комплекс языковых и программных средств, в которой
реализованы функции централизованного хранения и накопления обрабатываемой
информации
-комплекс языковых и программных средств, предназначенных
для создания, ведения и совместного использования БД многими пользователями
-нет правильного ответа
? 4
Приложение представляет собой:
-подсистему БнД, предназначенную для централизованного
хранения информации о структурах данных
-компонент БД, в котором представлены функции
централизованного хранения информации
-программу или комплекс программ, обеспечивающих
автоматизацию обработки информации для прикладной задачи
-нет правильного ответа
? 5
Словарь данных это:
-подсистема БнД, предназначенная для создания, ведения и
совместного использования БД многими пользователями
-программа или комплекс программ, обеспечивающих
автоматизацию обработки информации для прикладной задачи
-подсистема БнД, предназначенная для централизованного
хранения информации о структурах данных, взаимосвязях файлов БД друг с другом,
типах данных и форматах их представления, принадлежности данных пользователям,
кодах защиты и разграничения доступа и т.д.
-нет правильного ответа
? 6
Администратор базы данных это:
-лицо или группа лиц, отвечающих за правильную работу
программных и технических средств
-лицо или группа лиц, которые проводят профилактические,
регламентные, восстановительные и другие работы по планам, а также по мере
необходимости
-лицо или группа лиц, отвечающих за выработку требований к
БД, ее проектирование, создание, эффективное использование и сопровождение
-нет правильного ответа
? 7
Вычислительная система это:
-совокупность программ, обеспечивающих автоматизацию
обработки информации для прикладной задачи
-совокупность взаимосвязанных и согласованно действующих
программ
-совокупность взаимосвязанных и согласованно действующих ЭВМ
или процессоров и других устройств
-нет правильного ответа
? 8
Сервер это:
-компьютер (программа), которая использует ресурс и
управляет им
-компьютер (программа), использующая ресурс
-компьютер (программа), управляющая ресурсом
-нет правильного ответа
? 9
К СУБД относятся следующие виды программ:
-полнофункциональные СУБД
-серверы СУБД
-клиенты СУБД
-средства разработки программ работы с БД
-нет правильного ответа
? 10
Транзакция это:
-операция над приложениями
-некоторая делимая последовательность операций над данными
БД
-некоторая неделимая последовательность операций над данными
БД
-нет правильного ответа
? 11
Целостность БД это:
-свойство особой базы данных, непосредственно не доступная
пользователю
-свойство банка данных, означающее, что в нем содержится
полная, непротиворечивая и адекватно отражающая предметную область информация
-свойство базы данных, означающее, что в ней содержится
полная, непротиворечивая и адекватно отражающая предметную область информация
-нет правильного ответа
? 12
К числу классических моделей СУБД относятся:
-иерархическая
-постреляционная
-сетевая
-многомерная
-реляционная
-объектно-ориентированная
? 13
Отношение это:
-таблица базы данных
-кортеж данных
-множество элементов, называемых кортежами
-нет правильного ответа
? 14
Что означает Полиморфизм
-способность изменять программный код
-способность работать с разнотипными данными
-означает способность одного и того же программного кода
работать с разнотипными данными
-нет правильного ответа
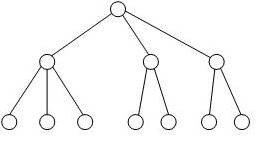 ? 15
? 15
Что показано на рисунке
-представление связей в сетевой модели
-представление связей в реляционной модели
-представление связей в иерархической модели
-представление связей в постреляционной модели
-представление связей в многомерной модели
-представление связей в объектно-ориентированной модели
-линии и кружочки
 ? 16
? 16
Что показано на рисунке
-представление связей в сетевой модели
-представление связей в реляционной модели
-представление связей в иерархической модели
-представление связей в постреляционной модели
-представление связей в многомерной модели
-представление связей в объектно-ориентированной модели
-три треугольника и пять кружочков
? 17
Основные типы данных:
-числовые
-символьные
-даты
-дата/время
-поле Мемо
-символьные переменной длины
-двоичные
? 18
Реляционная модель данных представляет собой:
-набор атрибутов, изменяющихся во времени
-набор значений атрибута, изменяющихся во времени
-набор отношений, изменяющихся во времени
-нет правильного ответа
? 19
Какие элементы РМД соответствуют формам представления
-схема отношения
 -отношение
-отношение
-кортеж
-сущность
-атрибут
-домен
-первичный ключ
-значение атрибута
-тип данных
? 20
Какая форма представления у отношения
-список имен атрибутов
-свойства, характеризующие сущность
-двумерная таблица, содержащая некоторые данные
-нет правильного ответа
? 21
Какая форма представления у домена
-объект любой природы, данные о котором хранятся в БД
-атрибут отношения, однозначно идентифицирующий каждый из
его кортежей
-множество всех возможных значений определенного атрибута
отношения
-нет правильного ответа
? 22
Какая форма представления у сущности
-список имен атрибутов
-атрибут отношения, однозначно идентифицирующий каждый из
его кортежей
-множество всех возможных значений определенного атрибута
отношения
-нет правильного ответа
 ? 23
? 23
Какого вида связь, изображенная на рисунке
-1:1
-1:М
-М:1
-М:М
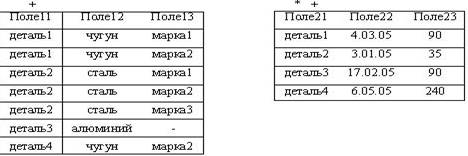 ? 24
? 24
Какого вида связь, изображенная на рисунке
-1:1
-1:М
-М:1
-М:М
? 25
Какая операция реляционной алгебры показана на рисунке
 -объединение
-объединение
-разность
-пересечение
-произведение
-выборка
-проекция
-деление
-соединение
? 26
 Какая операция
Какая операция
реляционной алгебры показана на рисунке
-объединение
-разность
-пересечение
-произведение
-выборка
-проекция
-деление
-соединение
? 27
В чем заключается логическое проектирование
-Логическое проектирование заключается в формировании
физической структуры БД, определении типов отчетных документов, разработке
алгоритмов обработки информации, создании форм для ввода и редактировании
данных в базе
-Логическое проектирование заключается в определении числа и
структуры таблиц, формировании физической структуры БД, определении типов
отчетных документов, создании форм для ввода и редактировании данных в базе
-Логическое проектирование заключается в определении числа и
структуры таблиц, формировании запросов к БД, определении типов отчетных
документов, разработке алгоритмов обработки информации
-Нет правильного ответа
? 28
При проектировании структур данных для автоматизированных
систем можно выделить три основных подхода:
-Сбор информации об объектах решаемой задачи в рамках одной
таблицы и последующая декомпозиция ее на несколько взаимосвязанных таблиц на
основе процедуры нормализации отношений
-Формулирование знаний о системе и требований к обработке
данных, получение с помощью системы готовой схемы БД или даже готовой
прикладной информационной системы
-Структурирование информации для использования в
информационной системе в процессе проведения системного анализа на основе
совокупности правил и рекомендаций
-Сбор информации о системе и требований к обработке данных,
получение с помощью системы готовой схемы БД или даже готовой прикладной
информационной системы
-Структурирование информации для объектов решаемой задачи в
рамках одной таблицы и последующая декомпозиция ее на несколько взаимосвязанных
таблиц на основе процедуры нормализации отношений
-Формулирование знаний для использования в информационной
системе в процессе проведения системного анализа на основе совокупности правил
и рекомендаций
? 29
Аномалия это:
-безысходное изменение БД
-необъяснимое поведение данных, которое приводит к сбою БД
-такая ситуация, которая приводит к противоречиям в БД либо
существенно усложняет обработку данных
-нет правильного ответа
? 30
Первая нормальная форма
-Отношение находится в 1НФ, если хотя бы один атрибут
являются простым
-Отношение находится в 1НФ, если хотя бы три атрибута
являются простыми
-Отношение находится в 1НФ, если все его атрибуты являются
простыми
-Нет правильного ответа
? 31
Третья нормальная форма
-отношение находится в 3НФ в том и только в том случае, если
все не ключевые атрибуты отношения взаимно независимы и полностью зависят от
первичного ключа
-отношение находится в 3НФ, если оно находится в 1НФ и
каждый не ключевой атрибут нетранзитивно зависит от первичного ключа
-отношение находится в 3НФ, если оно находится в 2НФ и
каждый не ключевой атрибут нетранзитивно зависит от первичного ключа
-Нет правильного ответа
? 32
Сколько видов нормальных форм
-1
-2
-3
-4
-5
-6
-7
-8
-9
? 33
Физическая целостность данных означает:
-наличие логического доступа к данным
-наличие не утраченных данных
-наличие физического доступа к данным и то, что данные не
утрачены
-Нет правильного ответа
? 34
Логическая целостность данных означает:
-наличие логической структуры данных в БД
-отсутствие физических ошибок в БД
-отсутствие логических ошибок в БД, к которым относятся
нарушение структуры БД или ее объектов
-Нет правильного ответа
? 35
Наиболее точным аналогом реляционной базы данных может
служить:
— неупорядоченное множество данных
— вектор
— генеалогическое дерево
— двумерная таблица
? 36
Таблицы в базах данных предназначены:
— для хранения данных базы
— для отбора и обработки данных базы
— для автоматического выполнения группы команд
— для выполнения сложных программных действий
? 37
Что из перечисленного не является объектом Access:
— модули
— таблицы
— макросы
— ключи
— формы
— отчеты
— запросы
? 38
Для чего предназначены запросы:
— для хранения данных базы
— для отбора и обработки данных базы
— для ввода данных базы и их просмотра
— для автоматического выполнения группы команд
— для выполнения сложных программных действий
— для вывода обработанных данных базы на принтер
? 39
Для чего предназначены макросы:
— для хранения данных базы
— для отбора и обработки данных базы
— для ввода данных базы и их просмотра
— для автоматического выполнения группы команд
— для выполнения сложных программных действий
? 40
В каком режиме работает с базой данных пользователь:
— в проектировочном
— в любительском
— в эксплутационном
— в заданном
? 41
В каком диалоговом окне создают связи между полями таблиц
базы данных:
— таблица связей
— схема связей
— схема данных
— таблица данных
? 42
Почему при закрытии таблиц программа Access не предлагает
выполнить сохранение внесенных данных:
— недоработка программы
— потому что данные сохраняются сразу после ввода в таблицу
— потому что данные сохраняются только после закрытия всей
базы данных
? 43
Без каких объектов не может существовать база данных:
— без модулей
— без отчетов
— без таблиц
— без форм
— без макросов
— без запросов
? 44
В каких элементах таблицы хранятся данные базы:
— в полях
— в строках
— в столбцах
— в записях
— в ячейках
? 45
Содержит ли какую-либо информацию таблица, в которой нет ни
одной записи:
— пустая таблица не содержит никакой информации
— пустая таблица содержит информацию о структуре базы данных
— пустая таблица содержит информацию о будущих записях
— таблица без записей существовать не может
? 46
В чем состоит особенность поля «счетчик»
— служит для ввода числовых данных
— служит для ввода действительных чисел
— данные хранятся не в поле, а в другом месте, а в поле
хранится только указатель на то, где расположен текст
— имеет свойство автоматического наращивания
— имеет ограниченный размер
? 47
В чем особенность поля «мемо»
— служит для ввода числовых данных
— служит для ввода действительных чисел
— данные хранятся не в поле, а в другом месте, а в поле
хранится только указатель на то, где расположен текст
— имеет свойство автоматического наращивания
— имеет ограниченный размер
? 48
Какое поле можно считать уникальным
— поле, значения в котором не могут повторяться
— поле, которое носит уникальное имя
— поле, значение которого имеют свойство наращивания
? 49
Ключами поиска в системах управления базами данных
называются:
— диапазон записей файла БД, в котором осуществляется поиск
— логические выражения, определяющие условия поиска
— поля, по значению которых осуществляется поиск
— номера записей, удовлетворяющих условиям поиска
— номер первой по порядку записи, удовлетворяющей условиям
поиска
? 50
Для чего предназначены формы:
— для хранения данных базы
— для отбора и обработки данных базы
— для ввода данных базы и их просмотра
— для автоматического выполнения группы команд
— для выполнения сложных программных действий
? 51
Содержит ли какую-либо информацию таблица, в которой нет
полей
— содержит информацию о структуре базы данных
— не содержит никакой информации
— таблица без полей существовать не может
— содержит информацию о будущих записях
Версия 2021 года
Теоретические основы баз данных.
1. Определение информационной системы, способы структурирования информации. Определения: база данных, СУБД, транзакция, согласованность данных, целостность и непротиворечивость данных. Функции и назначение СУБД. Технологии доступа к данным.
2. Этапы проектирования баз данных. Инфологическая, концептуальная, даталогическая, физическая модели. ER-модели, термины инфологического моделирования. Виды связей между сущностями. История развития СУБД. Модели данных: иерархическая, сетевая, реляционная, объектно-ориентированная.
3. Понятия реляционной модели: атом, домен, кортеж, отношение. Термины реляционной модели и теории множеств. Свойства реляционных баз данных. Реляционная алгебра. Операции над множествами.
4. Понятия ключа и ссылочной целостности данных. Первичный, альтернативный и внешний ключи, их свойства. Способы поддержания ссылочной целостности. Нормализация отношений в БД, необходимость нормализации, определение функциональной зависимости атрибутов. Типы и примеры нормальных форм. Недостатки и ограничения реляционной модели.
Язык SQL и СУБД PostgreSQL.
1. Основные характеристики, возможности и сравнительный анализ современных сетевых реляционных баз данных. СУБД PostgreSQL — общие сведения, характеристики, язык, особенности использования. Типы данных PostgreSQL.
2. История развития и стандарты языка SQL. Наборы команд SQL и примеры операторов. Оператор SELECT: синтаксис, ключевые слова и псевдонимы, разделы, постановка условий, предикаты, создание связей между таблицами, группировка, использование функций агрегирования, групповая фильтрация, сортировка, использование вложенных запросов, коррелируемые запросы, возможности записи результата, объединение таблиц. Операторы манипулирования данными (INSERT, UPDATE, DELETE).
3. Элементы PostgreSQL: представления, курсоры, хранимые процедуры, пользовательские функции, триггеры, временные таблицы – примеры создания, использования и удаления средствами языков SQL и PL/pgSQL. Использование пользовательских типов данных, объектно-реляционный подход.
4. Обеспечение безопасности и сохранности данных. Администрирование баз данных на примере PostgreSQL: интерфейсы администрирования. Роли, схемы данных. Управление доступом к данным. Команды GRANT, REVOKE — примеры использования. Методы и технологии защиты данных.
Реляционные, объектно-реляционные и объектно-ориентированные СУБД.
1. СУБД Microsoft SQL Server – общие сведения, типы данных, перспективы использования. Язык Transact-SQL. Элементы Microsoft SQL Server: временные таблицы, представления, курсоры, хранимые процедуры, пользовательские функции, ограничения, триггеры — создание, использование и удаление. Способы и средства управления и администрирования. Управление правами пользователей (команды GRANT, DENY, REVOKE). Конструкции PIVOT и WITH в Transact-SQL.
2. СУБД MySQL – общие сведения, типы данных, способы и средства управления и администрирования, особенности языка, примеры запросов, перспективы использования.
3. СУБД Microsoft Access. Общие сведения, типы данных, состав и функциональность. Средства программирования: язык VBA, язык SQL, макросы. Основы объектно-ориентированного программирования на VBA Microsoft Access. Основные синтаксические конструкции языка. Способы выполнения запросов к данным. Программирование в формах.
4. Суть объектно-реляционного подхода. Способы работы с объектами в реляционных базах данных в соответствии со стандартом SQL-3. СУБД Oracle – общие сведения, состав, типы данных, язык, примеры запросов. Пользовательские типы данных.
5. Концепция объектно-ориентированных баз данных. Преимущества и недостатки использования ООБД, примеры ООБД.
Работа с данными.
1. Слабоструктурированные данные: хранение информации в XML и JSON-форматах. Структура форматов. Организация хранения данных в XML-формате в СУБД Microsoft SQL Server. Примеры формирования выборок данных с использованием XML-элементов с помощью SQL-запросов. Язык XQuery. Работа с JSON-данными в PostgreSQL.
2. Концепция и терминология анализа данных, суть OLAP. Алгоритмы и идеи Data Mining. Многомерное представление данных: куб данных, измерения, меры, срезы. Принципы разработки и использования информационных хранилищ данных. Пример работы с Microsoft Analysis Services, организация запросов к многомерным данным на языке MDX.
3. Механизмы клиент-серверного взаимодействия с СУБД. Интерфейсы ODBC, JDBC, OLE DB, ADO.NET. Разработка клиентских приложений на языке Python. Объектно-реляционное отображение (ORM) и технология «Code First». Microsoft Visual Studio, C# и технология LINQ.
4. Способы организации Интернет-доступа к сетевым СУБД. Протокол HTTP. Примеры программирования активных серверных страниц для организации доступа к сетевым реляционным СУБД на языке PHP. Интернет-атаки на базы данных. SQL-инъекции: суть проблемы, примеры, методы защиты.

Вопросы к экзамену по цчебной дисциплине «Основы проектирования баз данных»
Скачать:
Предварительный просмотр:
- Какие ограничения накладываются на формат идентификатора?
- Перечислите этапы, составляющие жизненный цикл БД.
- Дайте определения понятиям: информационная система, предметная область.
- Для чего используется словарь данных?
- Какие типы данных поддерживаются в SQL?
- Укажите достоинства и недостатки иерархической модели данных.
- Дайте определение понятию SQL.
- Дайте определение CASE-средствам и CASE-технологии.
- Приведите общий синтаксис SQL-оператора для добавления записи в таблицу.
- Что представляет собой трехуровневая архитектура СУБД?
- В чем особенность уровня внешних моделей?
- Что означает логическая и физическая независимость данных?
- Приведите общий синтаксис SQL-оператора для добавления столбца в таблицу.
- Каково назначение систем управления базами данных?
- Назовите признаки классификации CASE-средств.
- Перечислите основные типы форм.
- Перечислите способы создания форм.
- Как проявляется иерархическая подчиненность в связи «один ко многим»?
- С помощью какого ключевого слова осуществляется группировка данных в операторе SELECT?
- В каких случаях модификация столбца невозможна?
- В чем особенность концептуального уровня?
- Что называется концептуальной моделью?
- Дайте определение понятию «метаязык».
- С помощью какого ключевого слова осуществляется сортировка данных в операторе SELECT?
- Приведите классификацию СУБД по различным признакам.
- Дайте краткую характеристику СУБД Access.
- Перечислите и охарактеризуйте операции реляционной алгебры. Приведите примеры.
- Что называется атрибутом сущности и экземпляром атрибута?
- В чем различие между данными и метаданными?
- Назовите достоинства и недостатки существующих многопользовательских технологий с базами данных.
- Какую роль в развитии технологии БД сыграло появление ПК?
- На какие факторы опираются правила генерации таблиц из ER-диаграмм?
- Перечислите категории команд языка SQL.
- Приведите общий синтаксис SQL-оператора для удаления записи.
- Что является целью каждого этапа жизненного цикла БД?
- Приведите общий синтаксис SQL-оператора для создания таблицы.
- Для чего используются ключевое слово WHERE?
- Каким образом прикладные программы взаимодействуют с БД?
- Охарактеризуйте реляционную модель данных.
- Что называется сущностью и экземпляром сущности?
- Приведите общий синтаксис SQL-оператора для модификации записи.
- По каким признакам классифицируются БД?
- Какие типы данных поддерживаются СУБД Access?
- Как отсортировать данные по возрастанию (убыванию)?
- Каковы функции СУБД?
- Какие символы применяются в нотации БНФ? Что они обозначают?
- Какой режим представления данных обеспечивает максимальную гибкость для просмотра и ввода данных?
- Что называется связью между сущностями?
- Как произвести выборку данных из нескольких связанных таблиц?
- Что такое простой ключ и составной ключ?
- Какие компоненты входят в состав банка данных?
- Чем банк данных отличается от базы данных?
- Сколько реляционных операций образуют реляционную алгебру? Кем определена?
- Для чего используются ключевые слова ALL и DISTINCT?
- В чем состоит основное достоинство SQL?
- Чем отличается реляционная модель данных от предшествующих ей моделей?
- В каких случаях удаление столбца невозможно?
- Какие операции и функции можно выполнять над данными в SQL?
- Приведите общий синтаксис SQL-оператора для удаления столбца.
- Какие функции для работы со строками в SQL вам известны?
- Перечислите виды связей между объектами? Охарактеризуйте их.
- В чем особенность физического уровня?
- Приведите общий синтаксис SQL-оператора для модификации столбца.
- Назовите этапы развития БД.
- Что такое агрегатные функции? Какие функции входят в эту группу?
- Какие операции допустимы в логических выражениях условия?
- Как организуется физическое размещение данных в БД иерархического типа?
- Охарактеризуйте сетевую модель данных.
- Какие требования предъявляются к СУБД?
- Приведите общий синтаксис SQL-оператора SELECT.
- Для чего используется ключевое слово HAVING?
- Что называется, базой данных и каково ее место в ИС?
- Какие действия можно выполнять, работая с формой?
- Для чего используется ключевое слово FROM?
- Из каких слов состоит оператор SQL?
По теме: методические разработки, презентации и конспекты
- Мне нравится
Вопросы к экзамену
по дисциплине «Базы данных«
Специальность — прикладная информатика
2021-2022 уч. год
- (6) Базы данных. СУБД. Классификация.
- (23) Типология БД. Документальные БД. Фактографические БД.
- (24) Типология БД. Гипертекстовые и мультимедийные БД. Объектно-ориентированные БД.
- (25) Типология БД. Распределенные БД. Коммерческие БД.
- (11) Иерархическая и сетевая модели данных.
- (12) Элементы реляционной модели данных.
- (13) Реляционные БД. Ограничения целостности.
- (7) Реляционные БД. Индексирование таблиц. Связывание таблиц.
- (15) Постреляционная и многомерная модель данных.
- (4) Реляционная алгебра (объединение, пересечение, вычитание, произведение, выборка).
- (9) Реляционная алгебра (проекция, деление, соединение).
- (5) Реляционное исчисление. Язык SQL.
- (2) Проблемы проектирования реляционных БД.
- (1) Нормальные формы: 1НФ, 2НФ, 3НФ.
- (14) Нормальные формы: НФБК, 4НФ, 5НФ.
- (3) Принципы построения БД. Метод «Сущность-связь».
- (8) Пример разработки ER-модели.
- (16) Системы управления БД следующего поколения.
- (10) XML. XML-серверы.
- (26) Стилевые таблицы XSL.
- (17) Жизненный цикл БД. Модели жизненного цикла ПО.
- (27) Модели структурного проектирования. Метод структурного анализа и проектирования.
- (18) Проблема создания и сжатия больших информационных массивов, информационных хранилищ и складов данных. Сжатие без потерь в реляционных СУБД.
- (28) Основы фракталов. Фрактальная математика. Фрактальные методы в архивации.
- (19) Технология оперативной обработки транзакции (ОLТР-технология). Информационные хранилища. ОLАР-технология. Управление складами данных.
- (29) Защита информации в MS Access.
- (20) Хранилища данных.
- (32) Хранение отношений.
- (31) Кэширование данных.
- (21) Организация индексов. В-деревья.
- (22) Управление транзакциями. Сериализация транзакций.
- (30) Триггеры и хранимые процедуры.
Преподаватель, к.ф.-м.н.,доцент А.В. Ермоленко