Применение агрегатных функций и вложенных запросов в операторе выбора
В SQL добавлены дополнительные функции, которые позволяют вычислять обобщенные групповые значения. Для применения агрегатных функций предполагается предварительная операция группировки. В чем состоит суть операции группировки? При группировке все множество кортежей отношения разбивается на группы, в которых собираются кортежи, имеющие одинаковые значения атрибутов, которые заданы в списке группировки.
Например, сгруппируем отношение R1 по значению столбца Дисциплина. Мы получим 4 группы, для которых можем вычислить некоторые групповые значения, например количество кортежей в группе, максимальное или минимальное значение столбца Оценка.
Это делается с помощью агрегатных функций. Агрегатные функции вычисляют одиночное значение для всей группы таблицы. Список этих функций представлен в табл. 5.7.
| Функция | Результат |
|---|---|
| COUNT | Количество строк или непустых значений полей, которые выбрал запрос |
| SUM | Сумма всех выбранных значений данного поля |
| AVG | Среднеарифметическое значение всех выбранных значений данного поля |
| MIN | Наименьшее из всех выбранных значений данного поля |
| MAX | Наибольшее из всех выбранных значений данного поля |
| R1 | |||
|---|---|---|---|
| ФИО | Дисциплина | Оценка | |
| Группа 1 | Петров Ф. И. | Базы данных | 5 |
| Сидоров К. А. | Базы данных | 4 | |
| Миронов А. В. | Базы данных | 2 | |
| Степанова К. Е. | Базы данных | 2 | |
| Крылова Т. С. | Базы данных | 5 | |
| Владимиров В. А. | Базы данных | 5 | |
| Группа 2 | Сидоров К. А. | Теория информации | 4 |
| Степанова К. Е. | Теория информации | 2 | |
| Крылова Т. С. | Теория информации | 5 | |
| Миронов А. В. | Теория информации | Null | |
| Группа 3 | Трофимов П. А. | Сети и телекоммуникации | 4 |
| Иванова Е. А. | Сети и телекоммуникации | 5 | |
| Уткина Н. В. | Сети и телекоммуникации | 5 | |
| Группа 4 | Владимиров В. А. | Английский язык | 4 |
| Трофимов П. А. | Английский язык | 5 | |
| Иванова Е. А. | Английский язык | 3 | |
| Петров Ф. И. | Английский язык | 5 |
Агрегатные функции используются подобно именам полей в операторе SELECT, но с одним исключением: они берут имя поля как аргумент. С функциями SUM и AVG могут использоваться только числовые поля. С функциями COUNT, MAX и MIN могут использоваться как числовые, так и символьные поля. При использовании с символьными полями MAX и MIN будут транслировать их в эквивалент ASCII кода и обрабатывать в алфавитном порядке. Некоторые СУБД позволяют использовать вложенные агрегаты, но это является отклонением от стандарта ANSI со всеми вытекающими отсюда последствиями.
Например, можно вычислить количество студентов, сдававших экзамены по каждой дисциплине. Для этого надо выполнить запрос с группировкой по полю «Дисциплина» и вывести в качестве результата название дисциплины и количество строк в группе по данной дисциплине. Применение символа * в качестве аргумента функции COUNT означает подсчет всех строк в группе.
SELECT R1.Дисциплина, COUNT(*) FROM R1 GROUP BY R1.Дисциплина
Результат:
| Дисциплина | COUNT(*) |
|---|---|
| Базы данных | 6 |
| Теория информации | 4 |
| Сети и телекоммуникации | 3 |
| Английский язык | 4 |
Если же мы хотим сосчитать количество сдавших экзамен по какой-либо дисциплине, то нам необходимо исключить неопределенные значения из исходного отношения перед группировкой. В этом случае запрос будет выглядеть следующим образом:
SELECT R1.Дисциплина, COUNT(*) FROM R1 WHERE R1.Оценка IS NOT NULL GROUP BY R1.Дисциплина
Получим результат:
| Дисциплина | COUNT(*) |
|---|---|
| Базы данных | 6 |
| Теория информации | 3 |
| Сети и телекоммуникации | 3 |
| Английский язык | 4 |
В этом случае строка со студентом
| Миронов А. В. | Теория информации | Null |
|---|
не попадет в набор кортежей перед группировкой, поэтому количество кортежей в группе для дисциплины «Теория информации» будет на 1 меньше.
Можно применять агрегатные функции также и без операции предварительной группировки, в этом случае все отношение рассматривается как одна группа и для этой группы можно вычислить одно значение на группу.
Обратившись снова к базе данных «Сессия» (таблицы R1, R2, R3 ), найдем количество успешно сданных экзаменов:
SELECT COUNT(*) FROM R1 WHERE Оценка > 2;
Это, конечно, отличается от выбора поля, поскольку всегда возвращается одиночное значение, независимо от того, сколько строк находится в таблице. Аргументом агрегатных функций могут быть отдельные столбцы таблиц. Но для того, чтобы вычислить, например, количество различных значений некоторого столбца в группе, необходимо применить ключевое слово DISTINCT совместно с именем столбца. Вычислим количество различных оценок, полученных по каждой дисциплине:
SELECT R1.Дисциплина, COUNT(DISTINCT R1.Оценка) FROM R1 WHERE R1.Оценка IS NOT NULL GROUP BY R1.Дисциплина
Результат:
| Дисциплина | COUNT(DISTINCT R1 .Оценка) |
|---|---|
| Базы данных | 3 |
| Теория информации | 3 |
| Сети и телекоммуникации | 2 |
| Английский язык | 3 |
В результат можно включить значение поля группировки и несколько агрегатных функций, а в условиях группировки можно использовать несколько полей. При этом группы образуются по набору заданных полей группировки. Операции с агрегатными функциями могут быть применены к объединению множества исходных таблиц. Например, поставим вопрос: определить для каждой группы и каждой дисциплины количество успешно сдавших экзамен и средний балл по дисциплине.
SELECT R1.Оценка, R1.Дисциплина, COUNT(*), AVR(Оценка) FROM R1,R2 WHERE R1.ФИО = R2.ФИО AND R1.Оценка IS NOT NULL AND R1.Оценка > 2 GROUP BY R1.Оценка R1.Дисциплина
Результат:
| Дисциплина | COUNT(*) | AVR(Oцeнкa) |
|---|---|---|
| Базы данных | 6 | 3.83 |
| Теория информации | 3 | 3.67 |
| Сети и телекоммуникации | 3 | 4.66 |
| Английский язык | 4 | 4.25 |
Мы не можем использовать агрегатные функции в предложении WHERE, потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции — в терминах групп строк.
Предложение GROUP BY позволяет определять подмножество значений в особом поле в терминах другого поля и применять функцию агрегата к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT. Агрегатные функции могут применяться как в выражении вывода результатов строки SELECT, так и в выражении условия обработки сформированных групп HAVING. В этом случае каждая агрегатная функция вычисляется для каждой выделенной группы. Значения, полученные при вычислении агрегатных функций, могут быть использованы для вывода соответствующих результатов или для условия отбора групп.
Построим запрос, который выводит группы, в которых по одной дисциплине на экзаменах получено больше одной двойки:
SELECT R2.Группа FROM R1,R2 WHERE R1.ФИО = R2.ФИО AND R1.Оценка = 2 GROUP BY R2.Группа, R1.Дисциплина HAVING count(*)> 1
В дальнейшем в качестве примера будем работать не с БД «Сессия», а с БД «Банк», состоящей из одной таблицы F, в которой хранится отношение F, содержащее информацию о счетах в филиалах некоторого банка:
F = (N, ФИО, Филиал, ДатаОткрытия, ДатаЗакрытия, Остаток); Q = (Филиал, Город);
поскольку на этой базе можно ярче проиллюстрировать работу с агрегатными функциями и группировкой.
Например, предположим, что мы хотим найти суммарный остаток на счетах в филиалах. Можно сделать раздельный запрос для каждого из них, выбрав SUM(Остаток) из таблицы для каждого филиала. GROUP BY, однако, позволит поместить их все в одну команду:
SELECT Филиал, SUM(Остаток) FROM F GROUP BY Филиал;
GROUP BY применяет агрегатные функции независимо для каждой группы, определяемой с помощью значения поля Филиал. Группа состоит из строк с одинаковым значением поля Филиал, и функция SUM применяется отдельно для каждой такой группы, то есть суммарный остаток на счетах подсчитывается отдельно для каждого филиала. Значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода, как и результат работы агрегатной функции. Поэтому мы можем совместить в одном запросе агрегат и поле. Вы можете также использовать GROUP BY с несколькими полями.
Предположим, что мы хотели бы увидеть только те суммарные значения остатков на счетах, которые превышают $5000. Чтобы увидеть суммарные остатки свыше $5000, необходимо использовать предложение HAVING. Предложение HAVING определяет критерии, используемые, чтобы удалять определенные группы из вывода, точно так же как предложение WHERE делает это для индивидуальных строк.
Правильной командой будет следующая:
SELECT Филиал, SUM(Остаток) FROM F GROUP BY Филиал HAVING SUM(Остаток) > 5000;
Аргументы в предложении HAVING подчиняются тем же самым правилам, что и в предложении SELECT, где используется GROUP BY. Они должны иметь одно значение на группу вывода.
Следующая команда будет запрещена:
SELECT Филиал,SUM(Остаток) FROM F GROUP BY Филиал HAVING ДатаОткрытия = 27/12/1999;
Поле ДатаОткрытия не может быть использовано в предложении HAVING, потому что оно может иметь больше чем одно значение на группу вывода. Чтобы избежать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля, выбранные GROUP BY. Имеется правильный способ сделать вышеупомянутый запрос:
SELECT Филиал,SUM(Остаток) FROM F WHERE ДатаОткрытия = '27/12/1999' GROUP BY Филиал;
Смысл данного запроса следующий: найти сумму остатков по каждому филиалу счетов, открытых 27 декабря 1999 года.
Как и говорилось ранее, HAVING может использовать только аргументы, которые имеют одно значение на группу вывода. Практически, ссылки на агрегатные функции — наиболее общие, но и поля, выбранные с помощью GROUP BY, также допустимы. Например, мы хотим увидеть суммарные остатки на счетах филиалов в Санкт-Петербурге, Пскове и Урюпинске:
SELECT Филиал, SUM(Остаток)
FROM F,Q
WHERE F.Филиал = Q.Филиал
GROUP BY Филиал
HAVING Город IN ("Санкт-Петербург", "Псков", "Урюпинск");
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Аналогично обстоит дело с подзапросами, входящими в предикаты условия выборки раздела HAVING: если в подзапросе используется характеристика текущей группы, то она может задаваться только путем ссылки на столбцы группирования.
Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия поиска есть TRUE. В частности, если раздел HAVING присутствует в табличном выражении, не содержащем GROUP BY, то результатом его выполнения будет либо пустая таблица, либо результат выполнения предыдущих разделов табличного выражения, рассматриваемый как одна группа без столбцов группирования.
ФЕДЕРАЛЬНОЕ
АГЕНТСТВО СВЯЗИ
Ордена
Трудового Красного Знамени
федеральное
государственное бюджетное образовательное
учреждение
высшего
образования
«Московский
технический университет связи и
информатики»
Кафедра «Интеллектуальные системы в
управлении и автоматизации»
Практическое задание №10-11
по дисциплине
«Технологии баз данных»
Выполнили:
Студенты группы
БСТ1801
Францев Артём
Авезов Гуванч
Практическое задание 10-11
Итоговая работа по теме «Построение
запросов на языке SQL»
Цель работы: закрепить полученные
знания о создании БД и построении
запросов на языке SQL.
Выполнение:
Создаем базу данных согласно заданию,
моделирующую сдачу сессию в некотором
учебном заведении. БД состоит из трех
отношений: r1,r2,r3.

Ниже на рисунке представлены три
созданные и заполненные таблицы: Таблица
R1

Таблица R2

Таблица R3

-
Вывести список всех групп (без повторений),
где должны пройти экзамены.

-
Вывести список всех студентов, которым
надо сдавать экзамены с указанием
названий дисциплин, по которым должны
проводиться эти экзамены.

-
Вывести список лентяев, имеющих несколько
двоек: Пугачев Н.Н.

-
Найти студентов, пришедших на экзамен,
но не сдававших его, с указанием названия
дисциплины.

-
Вычислить количество студентов,
сдававших экзамены по каждой дисциплине.

-
Сосчитать количество студентов, сдавших
экзамен по какой-либо дисциплине.

-
Найти количество успешно сданных
экзаменов.

-
Вычислить количество различных оценок,
полученных по каждой дисциплине.

-
Определить для каждой группы и каждой
дисциплины количество успешно сдавших
экзамен и средний балл по дисциплине.

-
Вывести группы, в которых по одной
дисциплине на экзаменах получено больше
одной двойки.
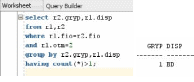
-
Вывести список тех, кто сдал все
положенные экзамены.

-
Список тех, кто должен был сдавать
экзамен по БД, но пока еще не сдавал.
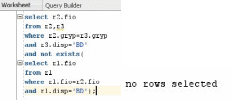
-
Найти студентов, которые сдали все
экзамены на оценку не ниже, чем «хорошо».
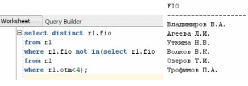
-
Создать отношение, содержащее все
оценки, полученные всеми студентами
по всем экзаменам, которые они должны
были сдавать. Если студент не сдавал
данного экзамена, то вместо оценки у
него будет стоять неопределенное
значение.
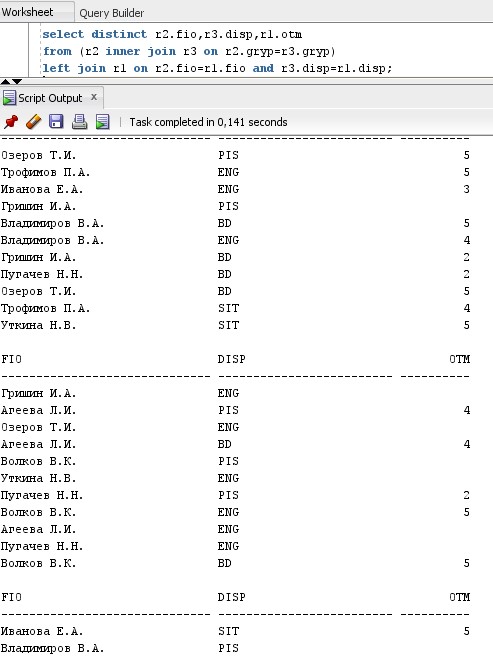
-
Исключить неуспевающих студентов из
списков.

-
Выполнить корректировку таблицы R1, с
учетом того, что Пугачев пересдал
экзамен по дисциплине «Базы данных» с
двойки сразу на четверку.


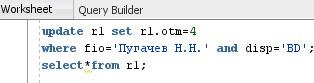

-
Промоделировать операцию перевода
групп на следующий курс.
Добавить в БД отношение R4 (содержит
перечень курсов, на которых учатся
студенты), отношение R5 (перечень студентов,
получающих стипендию с указанием
надбавки, которую они получают за
отличную учебу), отношение R6
(содержит размеры базовых стипендий на
каждый год).

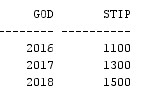
Таблица R4:

Таблица R5:

Таблица R6:
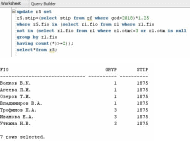
-
Внести изменения в БД, связанные с
назначением студентам стипендии.
Повышенная на 50%:

Повышенная на 25%:
Обычная:
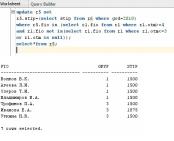
Снятие:
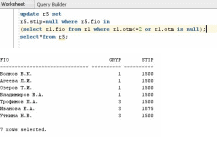
Самостоятельная работа:
-
В отношении R5 отметить студентов —
претендентов на отчисление. Считаем,
что в отношении R1 находятся окончательные
результаты сессии, и поэтому отчислению
подлежат все студенты, которые не сдали
или не сдавали два и более из положенных
экзаменов в сессию.
Для того чтобы зафиксировать этот факт,
нам потребуется добавить еще один
столбец в отношение R5, назовем его
результат сессии, и там могут быть два
допустимых значения: переведен на
следующий курс или отчислен
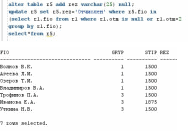
-
В отношении R5 отметить студентов,
переведенных на следующий курс.

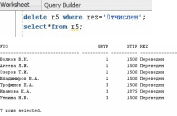
-
Провести отчисление студентов по
результатам текущей сессии. Обратите
внимание, что это уже другая операция
по сравнению с заданиями 1 и 2.
Москва 2021
Соседние файлы в предмете Технологии баз данных
- #
- #
- #
- #
- #
Применение агрегатных функций и вложенных запросов в операторе выбора
В SQL добавлены дополнительные функции, которые позволяют вычислять обобщенные групповые значения. Для применения агрегатных функций предполагается предварительная операция группировки. В чем состоит суть операции группировки? При группировке все множество кортежей отношения разбивается на группы, в которых собираются кортежи, имеющие одинаковые значения атрибутов, которые заданы в списке группировки.
Например, сгруппируем отношение R1 по значению столбца Дисциплина. Мы получим 4 группы, для которых можем вычислить некоторые групповые значения, например количество кортежей в группе, максимальное или минимальное значение столбца Оценка.
Это делается с помощью агрегатных функций. Агрегатные функции вычисляют одиночное значение для всей группы таблицы. Список этих функций представлен в таблице 5.7.
Таблица 5.7. Агрегатные функции
|
Функция |
Результат |
||
|
COUNT |
Количество строк или непустых значений полей, которые выбрал запрос |
||
|
SUM |
Сумма всех выбранных значений данного поля |
||
|
AVG |
Среднеарифметическое значение всех выбранных значений данного поля |
||
|
M1N |
Наименьшее из всех выбранных значений данного поля |
||
|
MAX |
Наибольшее из всех выоранных значений данного поля |
||
|
R1 |
|||||
|
ФИО |
Дисциплина |
Оценка |
|||
|
Группа 1 |
Петров Ф. И. |
Базы данных |
5 |
||
|
Сидоров К. А. |
Базы данных |
4 |
|||
|
Миронов А. В. |
Базы данных |
2 |
|||
|
Степанова К. Е. |
Базы данных |
2 |
|||
|
Крылова Т. С. |
Базы данных |
5 |
|||
|
Владимиров В. А. |
Базы данных |
5 |
|||
|
Группа 2 |
Сидоров К. А. |
Теория информации |
4 |
||
|
Степанова К. Е. |
Теория информации |
2 |
|||
|
Крылова Т. С. |
Теория информации |
5 |
|||
|
Миронов А. В. |
Теория информации |
Null |
|||
|
Группа 3 |
Трофимов П. А. |
Сети и телекоммуникации |
4 |
||
|
Иванова Е. А. |
Сети и телекоммуникации |
5 |
|||
|
Уткина Н. В. |
Сети и телекоммуникации |
5 |
|||
|
Группа 4 |
Владимиров В. А. |
Английский язык |
4 |
||
|
Трофимов П. А. |
Английский язык |
5 |
|||
|
Иванова Е. А. |
Английский язык |
3 |
|||
|
Петров Ф. И. |
Английский язык |
5 i |
|||
Агрегатные функции используются подобно именам полей в операторе SELECT, но с одним исключением: они берут имя поля как аргумент. С функциями SUM и AVG могут использоваться только числовые поля. С функциями COUNT, MAX и MIN могут использоваться как числовые, так и символьные поля. При использовании с символьными полями МАХ и MIN будут транслировать их в эквивалент ASCII кода и обрабатывать в алфавитном порядке. Некоторые СУБД позволяют использовать вложенные агрегаты, но это является отклонением от стандарта ANSI со всеми вытекающими отсюда последствиями.
Например, можно вычислить количество студентов, сдававших экзамены по каждой дисциплине. Для этого надо выполнить запрос с группировкой по полю «Дисциплина» и вывести в качестве результата название дисциплины и количество строк в группе по данной дисциплине. Применение символа * в качестве аргумента функции COUNT означает подсчет всех строк в группе.
SELECT R1.Дисциплина. СОUNТ(*)
FROM R1
GROUP BY R1 Дисциплина
Результат:
|
Дисциплина |
COUNT(*) |
||
|
Базы данных |
6 |
||
|
Теория информации |
4 |
||
|
Сети и телекоммуникации |
3 |
||
|
Английский язык |
4 |
||
Если же мы хотим сосчитать количество сдавших экзамен по какой-либо дисциплине, то нам необходимо исключить неопределенные значения из исходного отношения перед группировкой. В этом случае запрос будет выглядеть следующим образом:
SELECT R1.Дисциплина. COUNT(*)
FROM R1 WHERE R1.
Оценка IS NOT NULL
GROUP BY Rl.Дисциплина
Получим результат:
|
Дисциплина |
COUNT(*) |
||
|
Базы данных |
6 |
||
|
Теория информации |
3 |
||
|
Сети и телекоммуникации |
3 |
||
|
Английский язык |
4 |
||
В этом случае строка со студентом
|
Миронов А, В. |
Теория информации |
Null |
||
не попадет в набор кортежей перед группировкой, поэтому количество кортежей в группе для дисциплины «Теория информации» будет на 1 меньше.
Можно применять агрегатные функции также и без операции предварительной группировки, в этом случае все отношение рассматривается как одна группа и для этой группы можно вычислить одно значение на группу.
Обратившись снова к базе данных «Сессия» (таблицы Rl, R2, R3), найдем количество успешно сданных экзаменов:
SELECT COUNT(*)
FROM Rl
WHERE Оценка > 2:
Это, конечно, отличается от выбора поля, поскольку всегда возвращается одиночное значение, независимо от того, сколько строк находится в таблице. Аргументом агрегатных функций могут быть отдельные столбцы таблиц. Но для того, чтобы вычислить, например, количество различных значений некоторого столбца в группе, необходимо применить ключевое слово DISTINCT совместно с именем столбца. Вычислим количество различных оценок, полученных по каждой дисциплине:
SELECT Rl.Дисциплина.
COUNT(DISTINCT R1.Оценка)
FROM R1
WHERE R1.Оценка IS NOT NULL
GROUP BY Rl.Дисциплина
Результат:
|
Дисциплина |
COUNT(DISTINCT R1 .Оценка) |
||
|
Базы данных |
3 |
||
|
Теория информации |
3 |
||
|
Сети и телекоммуникации |
2 |
||
|
Английский язык |
3 |
||
В результат можно включить значение поля группировки и несколько агрегатных функций, а в условиях группировки можно использовать несколько полей. При этом группы образуются по набору заданных полей группировки. Операции с агрегатными функциями могут быть применены к объединению множества исходных таблиц. Например, поставим вопрос: определить для каждой группы и каждой дисциплины количество успешно сдавших экзамен и средний балл по дисциплине.
SELECT R2.Группа. R1.Дисциплина. COUNT(*), АVР(Оценка)
FROM R1.R2
WHERE Rl.ФИО = R2.ФИО AND
Rl.Оценка IS NOT NULL AND
Rl.Оценка > 2
GROUP BY R2.Группа. Rl.Дисциплина
Результат:
|
Дисциплина |
COUNT(*) |
АVР(Оценка) |
||
|
Базы данных |
6 |
3.83 |
||
|
Теория информации |
3 |
3.67 |
||
|
Сети и телекоммуникации |
3 |
4.66 |
||
|
Английский язык |
4 |
4.25 |
||
Мы не можем использовать агрегатные функции в предложении WHERE, потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции — в терминах групп строк.
Предложение GROUP BY позволяет определять подмножество значений в особом поле в терминах другого поля и применять функцию агрегата к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT. Агрегатные функции могут применяться как в выражении вывода результатов строки SELECT, так и в выражении условия обработки сформированных групп HAVING. В этом случае каждая агрегатная функция вычисляется для каждой выделенной группы. Значения, полученные при вычислении агрегатных функций, могут быть использованы для вывода соответствующих результатов или для условия отбора групп.
Построим запрос, который выводит группы, в которых по одной дисциплине на экзаменах получено больше одной двойки:
SELECT R2.Группа
FROM R1.R2
WHERE Rl.ФИО = R2.ФИО AND
Rl.Оценка = 2
GROUP BY R2.Группа . R1.Дисциплина
HAVING count(*)> 1
В дальнейшем в качестве примера будем работать не с БД «Сессия», а с БД «Банк», состоящей из одной таблицы F, в которой хранится отношение F, содержащее информацию о счетах в филиалах некоторого банка:
F = <N, ФИО, Филиал, ДатаОткрытия, ДатаЗакрытия, Остаток>;
Q = (Филиал, Город);
поскольку на этой базе можно ярче проиллюстрировать работу с агрегатными функциями и группировкой.
Например, предположим, что мы хотим найти суммарный остаток на счетах в филиалах. Можно сделать раздельный запрос для каждого из них, выбрав SUM(Остаток) из таблицы для каждого филиала. GROUP BY, однако, позволит поместить их все в одну команду:
SELECT Филиал, SUM
GROUP BY Филиал:
GROUP BY применяет агрегатные функции независимо для каждой группы, определяемой с помощью значения поля Филиал. Группа состоит из строк с одинаковым значением поля Филиал, и функция SUM применяется отдельно для каждой такой группы, то есть суммарный остаток на счетах подсчитывается отдельно для каждого филиала. Значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода, как и результат работы агрегатной функции. Поэтому мы можем совместить в одном запросе агрегат и поле. Вы можете также использовать GROUP BY с несколькими полями.
Предположим, что мы хотели бы увидеть только те суммарные значения остатков на счетах, которые превышают $5000. Чтобы увидеть суммарные остатки свыше $5000, необходимо использовать предложение HAVING. Предложение HAVING определяет критерии, используемые, чтобы удалять определенные группы из вывода, точно так же как предложение WHERE делает это для индивидуальных строк.
Правильной командой будет следующая:
SELECT Филиал, SUM(Остаток)
FROM F
GROUP BY Филиал
HAVING SUM(Остаток) > 5000;
Аргументы в предложении HAVING подчиняются тем же самым правилам, что и в предложении SELECT, где используется GROUP BY. Они должны иметь одно значение на группу вывода.
Следующая команда будет запрещена:
SELECT Филиал.SUM(Остаток)
FROM F GROUP BY Филиал
HAVING ДатаОткрытия = 27/12/1999;
Поле ДатаОткрытия не может быть использовано в предложении HAVING, потому что оно может иметь больше чем одно значение на группу вывода. Чтобы избежать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля, выбранные GROUP BY. Имеется правильный способ сделать вышеупомянутый запрос:
SELECT Филиал,SUM(Остаток)
FROM F
WHERE ДатаОткрытия = ’27/12/1999′
GROUP BY Филиал;
Смысл данного запроса следующий: найти сумму остатков по каждому филиалу счетов, открытых 27 декабря 1999 года.
Как и говорилось ранее, HAVING может использовать только аргументы, которые имеют одно значение на группу вывода. Практически, ссылки на агрегатные функции — наиболее общие, но и поля, выбранные с помощью GROUP BY, также допустимы. Например, мы хотим увидеть суммарные остатки на счетах филиалов в Санкт-Петербурге, Пскове и Урюпинске:
SELECT Филиал.SUМ(Остаток)
FROM F.Q
WHERE F.Филиал = Q.Филиал
GROUP BY Филиал
HAVING Филиал IN («Санкт-Петербург». «Псков». «Урюпинск»);
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Аналогично обстоит дело с подзапросами, входящими в предикаты условия выборки раздела HAVING: если в подзапросе используется характеристика текущей группы, то она может задаваться только путем ссылки на столбцы группирования.
Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия поиска есть TRUE. В частности, если раздел HAVING присутствует в табличном выражении, не содержащем GROUP BY, то результатом его выполнения будет либо пустая таблица, либо результат выполнения предыдущих разделов табличного выражения, рассматриваемый как одна группа без столбцов группирования.
Задача под номером /*6*/
/*1*/
CREATE TABLE STIP
(
IDD INT,
FIO VARCHAR2(200),
SUMMA INTEGER,
DATA_STIP DATE);
SELECT * FROM STIP;
CREATE TABLE PROVERKA
(
Dd INT ,
FIO VARCHAR2(200),
DISP VARCHAR2(200),
OCENKA VARCHAR2(200) CHECK (OCENKA IN (‘ОТЛИЧНО’,’ХОРОШО’,’УДОВЛЕТ’,’НУДОВЛ’)),
DATA_OCENKA DATE);
SELECT * FROM PROVERKA;
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11111,’Иванов Иван Иванович’,’Базы Данных’,’ОТЛИЧНО’,’10.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11112,’Сидоров Иван Гаврилович’,’Базы Данных’,’ХОРОШО’,’10.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11113,’Сидоров Иван Гаврилович’,’ТПР’,’ОТЛИЧНО’,’14.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11114,’Петров Алексей Иванович’,’Моделирование систем’,’УДОВЛЕТ’,’18.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11115,’Иванов Иван Иванович’,’ТПР’,’ОТЛИЧНО’,’10.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11116,’Иванов Иван Иванович’,’Моделирование систем’,’ХОРОШО’,’10.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11117,’Петров Алексей Иванович’,’ТПР’,’ОТЛИЧНО’,’14.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11118,’Петров Алексей Иванович’,’Базы Данных’,’ОТЛИЧНО’,’18.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11119,’Сидоров Иван Гаврилович’,’Моделирование систем’,’ОТЛИЧНО’,’14.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11120,’Иванов Иван Иванович’,’Философия’,’ОТЛИЧНО’,’10.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11121,’Алиев Иван Иванович’,’Моделирование систем’,’ХОРОШО’,’10.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11122,’Мальцев Алексей Иванович’,’ТПР’,’ОТЛИЧНО’,’14.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11123,’Мальцев Алексей Иванович’,’Базы Данных’,’ОТЛИЧНО’,’18.01.12′);
INSERT INTO PROVERKA(Dd,FIO,DISP,OCENKA,DATA_OCENKA) VALUES (11124,’Мальцев Алексей Иванович’,’Моделирование систем’,’ОТЛИЧНО’,’14.01.12′);
/*2*/
INSERT INTO STIP(FIO)
SELECT DISTINCT FIO
FROM PROVERKA;
/* Расчёт суммы стипендиии за каждую оценку, почти каждую
SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Сидоров Иван Гаврилович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’;
SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Сидоров Иван Гаврилович’ AND PROVERKA.OCENKA=’ХОРОШО’;
SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Петров Алексей Иванович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’;
SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Петров Алексей Иванович’ AND PROVERKA.OCENKA=’ХОРОШО’;
SELECT 300*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Петров Алексей Иванович’ AND PROVERKA.OCENKA=’УДОВЛЕТ’;
SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Иванов Иван Иванович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’;
SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Иванов Иван Иванович’ AND PROVERKA.OCENKA=’ХОРОШО’;
*/
/*3*/
UPDATE STIP
SET SUMMA=(SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Сидоров Иван Гаврилович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’)+(SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Сидоров Иван Гаврилович’ AND PROVERKA.OCENKA=’ХОРОШО’)+(SELECT 300*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Сидоров Иван Гаврилович’ AND PROVERKA.OCENKA=’УДОВЛЕТ’)
WHERE STIP.FIO=’Сидоров Иван Гаврилович’;
UPDATE STIP
SET SUMMA=(SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Петров Алексей Иванович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’)+(SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Петров Алексей Иванович’ AND PROVERKA.OCENKA=’ХОРОШО’)+(SELECT 300*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Петров Алексей Иванович’ AND PROVERKA.OCENKA=’УДОВЛЕТ’)
WHERE STIP.FIO=’Петров Алексей Иванович’;
UPDATE STIP
SET SUMMA=(SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Иванов Иван Иванович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’)+(SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Иванов Иван Иванович’ AND PROVERKA.OCENKA=’ХОРОШО’)+(SELECT 300*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Иванов Иван Иванович’ AND PROVERKA.OCENKA=’УДОВЛЕТ’)
WHERE STIP.FIO=’Иванов Иван Иванович’;
UPDATE STIP
SET SUMMA=(SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Мальцев Алексей Иванович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’)+(SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Мальцев Алексей Иванович’ AND PROVERKA.OCENKA=’ХОРОШО’)+(SELECT 300*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Мальцев Алексей Иванович’ AND PROVERKA.OCENKA=’УДОВЛЕТ’)
WHERE STIP.FIO=’Мальцев Алексей Иванович’;
UPDATE STIP
SET SUMMA=(SELECT 1250*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Алиев Иван Иванович’ AND PROVERKA.OCENKA=’ОТЛИЧНО’)+(SELECT 800*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Алиев Иван Иванович’ AND PROVERKA.OCENKA=’ХОРОШО’)+(SELECT 300*COUNT(PROVERKA.OCENKA)
FROM PROVERKA
WHERE PROVERKA.FIO=’Алиев Иван Иванович’ AND PROVERKA.OCENKA=’УДОВЛЕТ’)
WHERE STIP.FIO=’Алиев Иван Иванович’;
/*4*/
ALTER TABLE STIP ADD PRIMECH VARCHAR2(200);
/*5*/
SELECT FIO,COUNT(PROVERKA.DISP) AS СКОЛЬКО
FROM PROVERKA
GROUP BY FIO
HAVING PROVERKA.FIO=’Иванов Иван Иванович’;
SELECT FIO,COUNT(PROVERKA.DISP) AS СКОЛЬКО
FROM PROVERKA
GROUP BY FIO
HAVING PROVERKA.FIO=’Петров Алексей Иванович’;
SELECT FIO,COUNT(PROVERKA.DISP) AS СКОЛЬКО
FROM PROVERKA
GROUP BY FIO
HAVING PROVERKA.FIO=’Сидоров Иван Гаврилович’;
SELECT FIO,COUNT(PROVERKA.DISP) AS СКОЛЬКО
FROM PROVERKA
GROUP BY FIO
HAVING PROVERKA.FIO=’Мальцев Алексей Иванович’;
SELECT FIO,COUNT(PROVERKA.DISP) AS СКОЛЬКО
FROM PROVERKA
GROUP BY FIO
HAVING PROVERKA.FIO=’Алиев Иван Иванович’;
SELECT FIO,COUNT(PROVERKA.DISP) AS СКОЛЬКО
FROM PROVERKA
GROUP BY FIO;
/*6*/
SELECT * FROM STIP;
SELECT * FROM PROVERKA;
UPDATE STIP
SET PRIMECH=’ПЕРЕСЧИТАТЬ СТИПЕНДИЮ’
WHERE STIP.FIO = (SELECT DISTINCT FIO FROM PROVERKA WHERE (SELECT COUNT(DISTINCT DISP) FROM PROVERKA) IN (SELECT COUNT(PROVERKA.DISP)FROM PROVERKA GROUP BY FIO));
/*7.1*/
UPDATE STIP
SET SUMMA=SUMMA*0.02+SUMMA
WHERE PRIMECH=’ПЕРЕСЧИТАТЬ СТИПЕНДИЮ’;
UPDATE STIP
SET DATA_STIP=SYSDATE
WHERE PRIMECH=’ПЕРЕСЧИТАТЬ СТИПЕНДИЮ’;
/*7.2*/
Особенности функции COUNT
Агрегатные функции.
Итоговые запросы на чтение
Итоговые запросы на чтение позволяют получить промежуточные или окончательные итоги (статистическую информацию) по содержащимся в базе данных значениям. Итоговые запросы необходимо использовать, когда требуемой информации в базе данных в явной виде нет, и ее необходимо вычислить.
Для подведения итогов по информации, содержащейся в базе данных, в SQL предусмотрены агрегатные (статистические) функции.
Агрегатами называют группы строк, следовательно, агрегатными функциями называют функции, аргументами которых являются группы строк.
Агрегаты могут представлять собой все строки таблицы или группы строк, созданные предложением GROUP BY (будет рассмотрено в п.13.7.2).
Агрегатная функция получает в качестве аргумента выражение, содержащее, по крайней мере, один столбец таблицы, а в качестве результата возвращает одно значение. Таким образом, агрегатные функции позволяют выполнять операции над значениями сразу целого столбца таблицы или нескольких таблиц.
В SQL имеется пять стандартных агрегатных функций: SUM, AVG, MIN, MAX, COUNT.
SUM( ) вычисляет сумму всех значений в выражении;
AVG( ) вычисляет среднее всех значений в выражении;
MIN( ) находит наименьшее среди всех значений в выражении;
MAX( ) находит наибольшее среди всех значений в выражении;
COUNT( ) подсчитывает количество значений в выражении.
В качестве выражения чаще всего выступает имя столбца таблицы.
Функция COUNT(*) подсчитывает количество строк (т.е. учитывает и NULL).
Функция COUNT(DISTINCT ) подсчитывает количество разных значений в выражении.
Примечание 1.В Microsoft Access конструкция COUNT(DISTINCT ) не работает. Данная проблема решается применением вложенного запроса в предложении FROM.
Ограничения на использование агрегатных функций:
— агрегатные функции нельзя использовать в предложении WHERE (оно работает для одной строки, а не для агрегата);
— агрегатные функции нельзя вкладывать друг в друга (при необходимости можно использовать вложенные запросы);
— в предложении SELECT нельзя одновременно использоваться агрегатные функции и обычные имена столбцов (если только по этим столбцам не указана группировка GROUP BY)
Примечание 2.В предложении SELECT возвращаемым столбцам, в которых используются агрегатные функции, рекомендуется присваивать псевдонимы.
Пример 29. Вычислить суммарную стоимость всех вызовов.
Пример 30. Вычислить средний возраст для контактов.
Пример 31. Вычислить минимальную и максимальную длительность исходящих вызовов.
SELECT MIN(DLIT), MAX(DLIT)
FROM VYZOVY V, TIPY_VYZ T
WHERE (V.TIP_ID=T.ID) AND (T.NAZV=’Исходящий’)
Пример 32. Вывести дату и время самого первого вызова.
Пример 33. Вычислить количество контактов старше 30 лет.
Пример 34. Вычислить количество мелодий, уже назначенных для какого-либо контакта.
Глава. 6 ОБОБЩЕНИЕ ДАННЫХ С ПОМОЩЬЮ АГРЕГАТНЫХ ФУНКЦИЙ
ЧТО ТАКОЕ АГРЕГАТНЫЕ ФУНКЦИИ?
Запросы могут производить обобщённое групповое значение полей точно так же, как и значение одного поля. Это делается с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы.
Вот список этих функций:
COUNT выдаёт количество строк или не-NULL значений полей, которые выбрал запрос. SUM выдаёт арифметическую сумму всех выбранных значений данного поля. AVG выдаёт усреднение всех выбранных значений данного поля. MAX выдаёт наибольшее из всех выбранных значений данного поля. MIN выдаёт наименьшее из всех выбранных значений данного поля.
КАК ИСПОЛЬЗОВАТЬ АГРЕГАТНЫЕ ФУНКЦИИ?
Агрегатные функции используются, подобно именам полей в предложении SELECT-запроса, но с одним исключением: они берут имена полей как аргументы.
Только числовые поля могут использоваться с SUM и AVG.
С функциями COUNT, MAX и MIN могут использоваться и числовые, и символьные поля.
При использовании с символьными полями, MAX и MIN будут транслировать их в эквивалент ASCII, который должен сообщать, что MIN будет означать первое, а MAX последнее значение в алфавитном порядке (алфавитное упорядочивание обсуждается более подробно в Главе 4).
Чтобы найти SUM всех наших покупок в таблице Заказов, мы можем ввести следующий запрос, с выводом на Рисунке 6.1:
Это, конечно, отличается от выбора поля, при котором возвращается одиночное значение, независимо от того, сколько строк находится в таблице. Из-за этого агрегатные функции и поля не могут выбираться одновременно, если не будет использовано предложение GROUP BY (описанное далее).
Нахождение усреднённой суммы — похожая операция (вывод следующего запроса показан на Рисунке 6.2):
СПЕЦИАЛЬНЫЙ АТРИБУТ COUNT
Функция COUNT несколько отличается от всех остальных. Она считает число значений в данном столбце или число строк в таблице. Когда она считает значения столбца, она используется с DISTINCT, чтобы производить счёт чисел различных значений в данном поле. Мы могли бы использовать её, например, чтобы сосчитать количество продавцов, описанных в настоящее время в таблице Заказов (вывод показан на Рисунке 6.3):
ИСПОЛЬЗОВАНИЕ DISTINCT
Обратите внимание в вышеупомянутом примере, что DISTINCT, сопровождаемый именем поля, с которым он применяется, помещён в круглые скобки, но не сразу после SELECT, как раньше. Такого использования DISTINCT с COUNT, применяемого к индивидуальным столбцам, требует стандарт ANSI, но большое количество программ не предъявляют такого требования.
Вы можете выполнять несколько подсчётов (COUNT) в полях с помощью DISTINCT в одиночном запросе, что, как мы видели в Главе 3, не выполнялось, когда вы выбирали строки с помощью DISTINCT.
DISTINCT может использоваться таким образом с любой агрегатной функцией, но наиболее часто он используется с COUNT. С MAX и MIN это просто не будет иметь никакого эффекта, а SUM и AVG вы обычно применяете для включения повторяемых значений, так как они эффективнее общих и средних значений всех столбцов.
ИСПОЛЬЗОВАНИЕ COUNT СО СТРОКАМИ, А НЕ ЗНАЧЕНИЯМИ
Чтобы подсчитать общее число строк в таблице, используйте функцию COUNT со звёздочкой вместо имени поля, как в следующем примере, вывод из которого показан на Рисунке 6.4:
COUNT со звёздочкой включает и NULL, и дубликаты; по этой причине DISTINCT не может быть использован. DISTINCT может производить более высокие числа, чем COUNT особого поля, который удаляет все
строки, имеющие избыточные или NULL-данные в этом поле. DISTINCT неприменим c COUNT (*), потому что он не имеет никакого действия в хорошо разработанной и поддерживаемой БД. В такой БД не должно быть ни таких строк, которые являлись бы полностью пустыми, ни дубликатов (первые не содержат никаких данных, а последние полностью избыточны). Если всё-таки имеются полностью пустые или избыточные строки, вы, вероятно, не захотите, чтобы COUNT скрыл от вас эту информацию.
ВКЛЮЧЕНИЕ ДУБЛИКАТОВ В АГРЕГАТНЫЕ ФУНКЦИИ
Агрегатные функции могут также (в большинстве реализаций) использовать аргумент ALL, который помещается перед именем поля, подобно DISTINCT, но означает противоположное: включать дубликаты. ANSI технически не позволяет этого для COUNT, но многие реализации ослабляют это ограничение.
Различия между ALL и * при использовании с COUNT:
- ALL использует имя поля как аргумент.
- ALL не может подсчитать NULL-значения.
Пока * является единственным аргументом который включает NULL-значения, и только он используется с COUNT; функции, кроме COUNT, игнорируют NULL-значения в любом случае.
Следующая команда подсчитает (COUNT) число не-NULL-значений в поле rating в таблице Заказчиков (включая повторения):
АГРЕГАТЫ, ПОСТРОЕННЫЕ НА СКАЛЯРНОМ ВЫРАЖЕНИИ
До этого вы использовали агрегатные функции с одиночными полями как аргументами. Вы можете также использовать агрегатные функции с аргументами, которые состоят из скалярных выражений, включающих одно или более полей. (Если вы это делаете, DISTINCT не разрешается.)
Предположим, что таблица Заказов имеет ещё один столбец, который хранит предыдущий неуплаченный баланс (поле blnc) для каждого заказчика. Вы должны найти этот текущий баланс добавлением суммы приобретений к предыдущему балансу.
Вы можете найти наибольший неуплаченный баланс следующим образом:
Для каждой строки таблицы этот запрос будет складывать blnc и amt для данного заказчика и выбирать самое большое значение, которое он найдёт. Конечно, пока заказчики могут иметь несколько заказов, их неуплаченный баланс оценивается отдельно для каждого заказа. Возможно, заказ с более поздней датой будет иметь самый большой неуплаченный баланс. Иначе старый баланс должен быть выбран, как в запросе выше.
Фактически имеется большое количество ситуаций в SQL, где можно использовать скалярные выражения с полями или вместо полей, как вы увидите в Главе 7.
ПРЕДЛОЖЕНИЕ GROUP BY
Предложение GROUP BY позволяет вам определять подмножество значений в особом поле в терминах другого поля и применять агрегатную функцию к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT.
Например, предположим, что вы хотите найти наибольшую сумму продажи, полученную каждым продавцом. Вы можете сделать раздельный запрос для каждого из них, выбрав MAX (amt) из таблицы Заказов для каждого значения поля snum. GROUP BY, однако, позволит вам поместить всё в одну команду:
Вывод для этого запроса показан на Рисунке 6.5.
GROUP BY применяет агрегатные функции, независимо от серий групп, которые определяются с помощью значения поля в целом. В этом случае каждая группа состоит из всех строк с тем же самым значением поля snum, и MAX функция применяется отдельно для каждой такой группы. Это значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода так же, как это делает агрегатная функция. Результатом является совместимость, которая позволяет агрегатам и полям объединяться таким образом.
Вы можете также использовать GROUP BY с несколькими полями. Совершенствуя вышеупомянутый пример, предположим, что вы хотите увидеть наибольшую сумму продаж, получаемую каждым продавцом каждый день. Чтобы сделать это, вы должны сгруппировать таблицу Заказов по датам продавцов и применить функцию MAX к каждой такой группе:
Вывод для этого запроса показан на Рисунке 6.6.
Конечно же, пустые группы в дни, когда текущий продавец не имел заказов, не будут показаны в выводе.
ПРЕДЛОЖЕНИЕ HAVING
Предположим, что в предыдущем примере вы хотели бы увидеть только максимальную сумму приобретений, значение которой выше $3000.00. Вы не сможете использовать агрегатную функцию в предложении WHERE (если вы не используете подзапрос, описанный позже), потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции оцениваются в терминах групп строк. Это означает, что вы не сможете сделать что-нибудь подобно следующему:
Это будет отклонением от строгой интерпретации ANSI. Чтобы увидеть максимальную стоимость приобретений свыше $3000.00, вы можете использовать предложение HAVING.
Предложение HAVING определяет критерии, используемые, чтобы удалять определенные группы из вывода, точно так же, как предложение WHERE делает это для отдельных строк.
Правильной командой будет следующая:
Вывод для этого запроса показан на Рисунке 6. 7.
Аргументы в предложении HAVING следуют тем же самым правилам, что и в предложении SELECT, состоящем из команд, использующих GROUP BY. Они должны иметь одно значение на группу вывода.
Следующая команда будет запрещена:
Поле оdate не может быть вызвано предложением HAVING, потому что оно может иметь (и действительно имеет) больше чем одно значение на группу вывода. Чтобы избегать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля, выбранные GROUP BY. Имеется правильный способ сделать вышеупомянутый запрос (вывод показан на Рисунке 6.8):
Поскольку поля odate нет, не может быть и выбранных полей, и значение этих данных меньше, чем в некоторых других примерах. Вывод должен, вероятно, включать что-нибудь такое, что говорит: «это — самые большие заказы на 3 октября». В Главе 7 мы покажем, как вставлять текст в ваш вывод.
Как говорилось ранее, HAVING может использовать только аргументы, которые имеют одно значение на группу вывода. Практически ссылки на агрегатные функции — наиболее общие, но и поля, выбранные с помощью GROUP BY, также допустимы. Например, мы хотим увидеть наибольшие заказы для Serres и Rifkin:
Вывод для этого запроса показан на Рисунке 6.9.
НЕ ДЕЛАЙТЕ ВЛОЖЕННЫХ АГРЕГАТОВ
В строгой интерпретации ANSI SQL вы не можете использовать агрегат агрегата. Предположим, что вы хотите выяснить, в какой день имелась наибольшая сумма продаж. Если вы попробуете сделать так,
то ваша команда будет, вероятно, отклонена. (Некоторые реализации не предписывают этого ограничения, что выгодно, потому что вложенные агрегаты могут быть очень полезны, даже если они и несколько проблематичны.) В вышеупомянутой команде, например, SUM должен применяться к каждой группе поля odate, а MAX — ко всем группам, производящим одиночное значение для всех групп. Однако предложение GROUP BY подразумевает, что должна иметься одна строка вывода для каждой группы поля odate.
РЕЗЮМЕ
Теперь вы используете запросы несколько по-иному. Способность получать, а не просто размещать значения, очень мощна. Это означает, что вы не обязательно должны следить за определённой информацией, если вы можете сформулировать запрос так, чтобы её получить. Запрос будет давать вам поминутные результаты, в то время как таблица общего или среднего значений будет хороша только некоторое время после её модификации. Это не должно наводить на мысль, что агрегатные функции могут полностью вытеснить потребность в отслеживании информации, такой, например, как эта.
Вы можете применять эти агрегаты для групп значений, определённых предложением GROUP BY. Эти группы имеют значение поля в целом и могут постоянно находиться внутри других групп, которые имеют значение поля в целом. В то же время, предикаты ещё используются, чтобы определять, какие строки агрегатной функции применяются.
Объединенные вместе, эти особенности делают возможным производить агрегаты, основанные на чётко определённых подмножествах значений в поле. Затем вы можете определять другое условие для исключения определенных результатов групп с предложением HAVING.
Теперь, когда вы стали знатоком того, как запрос производит значения, мы покажем вам, в Главе 7, чт́о вы можете делать со значениями, которые он производит.
Применение агрегатных функций и вложенных запросов в операторе выбора
Дата добавления: 2013-12-23 ; просмотров: 3574 ; Нарушение авторских прав
В SQL добавлены дополнительные функции, которые позволяют вычислять обобщенные групповые значения. Для применения агрегатных функций предполагается предварительная операция группировки. В чем состоит суть операции группировки? При группировке все множество кортежей отношения разбивается на группы, в которых собираются кортежи, имеющие одинаковые значения атрибутов, которые заданы в списке группировки.
Например, сгруппируем отношение R1 по значению столбца Дисциплина. Мы получим 4 группы, для которых можем вычислить некоторые групповые значения, например количество кортежей в группе, максимальное или минимальное значение столбца Оценка.
Это делается с помощью агрегатных функций. Агрегатные функции вычисляют одиночное значение для всей группы таблицы. Список этих функций представлен в табл. 5.7.
Таблица 5.7. Агрегатные функции
Агрегатные функции используются подобно именам полей в операторе SELECT, но с одним исключением: они берут имя поля как аргумент. С функциями SUM и AVG могут использоваться только числовые поля. С функциями COUNT, MAX и MIN могут использоваться как числовые, так и символьные поля. При использовании с символьными полями MAX и MIN будут транслировать их в эквивалент ASCII кода и обрабатывать в алфавитном порядке. Некоторые СУБД позволяют использовать вложенные агрегаты, но это является отклонением от стандарта ANSI со всеми вытекающими отсюда последствиями.
Например, можно вычислить количество студентов, сдававших экзамены по каждой дисциплине. Для этого надо выполнить запрос с группировкой по полю «Дисциплина» и вывести в качестве результата название дисциплины и количество строк в группе по данной дисциплине. Применение символа * в качестве аргумента функции COUNT означает подсчет всех строк в группе.
SELECT R1.Дисциплина, COUNT(*)
GROUP BY R1.Дисциплина
Если же мы хотим сосчитать количество сдавших экзамен по какой-либо дисциплине, то нам необходимо исключить неопределенные значения из исходного отношения перед группировкой. В этом случае запрос будет выглядеть следующим образом:
SELECT R1.Дисциплина, COUNT(*)
WHERE R1.Оценка IS NOT NULL
GROUP BY R1.Дисциплина
В этом случае строка со студентом
не попадет в набор кортежей перед группировкой, поэтому количество кортежей в группе для дисциплины «Теория информации» будет на 1 меньше.
Можно применять агрегатные функции также и без операции предварительной группировки, в этом случае все отношение рассматривается как одна группа и для этой группы можно вычислить одно значение на группу.
Обратившись снова к базе данных «Сессия» (таблицы R1, R2, R3), найдем количество успешно сданных экзаменов:
WHERE Оценка > 2;
Это, конечно, отличается от выбора поля, поскольку всегда возвращается одиночное значение, независимо от того, сколько строк находится в таблице. Аргументом агрегатных функций могут быть отдельные столбцы таблиц. Но для того, чтобы вычислить, например, количество различных значений некоторого столбца в группе, необходимо применить ключевое слово DISTINCT совместно с именем столбца. Вычислим количество различных оценок, полученных по каждой дисциплине:
SELECT R1.Дисциплина, COUNT(DISTINCT R1.Оценка)
WHERE R1.Оценка IS NOT NULL
GROUP BY R1.Дисциплина
В результат можно включить значение поля группировки и несколько агрегатных функций, а в условиях группировки можно использовать несколько полей. При этом группы образуются по набору заданных полей группировки. Операции с агрегатными функциями могут быть применены к объединению множества исходных таблиц. Например, поставим вопрос: определить для каждой группы и каждой дисциплины количество успешно сдавших экзамен и средний балл по дисциплине.
SELECT R1.Оценка, R1.Дисциплина, COUNT(*), AVR(Оценка)
WHERE R1.ФИО = R2.ФИО AND
R1.Оценка IS NOT NULL AND
GROUP BY R1.Оценка R1.Дисциплина
Мы не можем использовать агрегатные функции в предложении WHERE, потому что предикаты оцениваются в терминах одиночной строки, а агрегатные функции — в терминах групп строк.
Предложение GROUP BY позволяет определять подмножество значений в особом поле в терминах другого поля и применять функцию агрегата к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT. Агрегатные функции могут применяться как в выражении вывода результатов строки SELECT, так и в выражении условия обработки сформированных групп HAVING. В этом случае каждая агрегатная функция вычисляется для каждой выделенной группы. Значения, полученные при вычислении агрегатных функций, могут быть использованы для вывода соответствующих результатов или для условия отбора групп.
Построим запрос, который выводит группы, в которых по одной дисциплине на экзаменах получено больше одной двойки:
WHERE R1.ФИО = R2.ФИО AND
GROUP BY R2.Оценка , R1.Дисциплина
В дальнейшем в качестве примера будем работать не с БД «Сессия», а с БД «Банк», состоящей из одной таблицы F, в которой хранится отношение F, содержащее информацию о счетах в филиалах некоторого банка:
F = (N, ФИО, Филиал, ДатаОткрытия, ДатаЗакрытия, Остаток);
Q = (Филиал, Город);
поскольку на этой базе можно ярче проиллюстрировать работу с агрегатными функциями и группировкой.
Например, предположим, что мы хотим найти суммарный остаток на счетах в филиалах. Можно сделать раздельный запрос для каждого из них, выбрав SUM(Остаток) из таблицы для каждого филиала. GROUP BY, однако, позволит поместить их все в одну команду:
SELECT Филиал, SUM(Остаток)
GROUP BY Филиал;
GROUP BY применяет агрегатные функции независимо для каждой группы, определяемой с помощью значения поля Филиал. Группа состоит из строк с одинаковым значением поля Филиал, и функция SUM применяется отдельно для каждой такой группы, то есть суммарный остаток на счетах подсчитывается отдельно для каждого филиала. Значение поля, к которому применяется GROUP BY, имеет, по определению, только одно значение на группу вывода, как и результат работы агрегатной функции. Поэтому мы можем совместить в одном запросе агрегат и поле. Вы можете также использовать GROUP BY с несколькими полями.
Предположим, что мы хотели бы увидеть только те суммарные значения остатков на счетах, которые превышают $5000. Чтобы увидеть суммарные остатки свыше $5000, необходимо использовать предложение HAVING. Предложение HAVING определяет критерии, используемые, чтобы удалять определенные группы из вывода, точно так же как предложение WHERE делает это для индивидуальных строк.
Правильной командой будет следующая:
SELECT Филиал, SUM(Остаток)
GROUP BY Филиал
HAVING SUM(Остаток) > 5000;
Аргументы в предложении HAVING подчиняются тем же самым правилам, что и в предложении SELECT, где используется GROUP BY. Они должны иметь одно значение на группу вывода.
Следующая команда будет запрещена:
GROUP BY Филиал
HAVING ДатаОткрытия = 27/12/1999;
Поле ДатаОткрытия не может быть использовано в предложении HAVING, потому что оно может иметь больше чем одно значение на группу вывода. Чтобы избежать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля, выбранные GROUP BY. Имеется правильный способ сделать вышеупомянутый запрос:
SELECT Филиал,SUM(Остаток) FROM F
WHERE ДатаОткрытия = ’27/12/1999′ GROUP BY Филиал;
Смысл данного запроса следующий: найти сумму остатков по каждому филиалу счетов, открытых 27 декабря 1999 года.
Как и говорилось ранее, HAVING может использовать только аргументы, которые имеют одно значение на группу вывода. Практически, ссылки на агрегатные функции — наиболее общие, но и поля, выбранные с помощью GROUP BY, также допустимы. Например, мы хотим увидеть суммарные остатки на счетах филиалов в Санкт-Петербурге, Пскове и Урюпинске:
SELECT Филиал, SUM(Остаток)
WHERE F.Филиал = Q.Филиал
GROUP BY Филиал
HAVING Город IN («Санкт-Петербург», «Псков», «Урюпинск»);
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Аналогично обстоит дело с подзапросами, входящими в предикаты условия выборки раздела HAVING: если в подзапросе используется характеристика текущей группы, то она может задаваться только путем ссылки на столбцы группирования.
Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия поиска есть TRUE. В частности, если раздел HAVING присутствует в табличном выражении, не содержащем GROUP BY, то результатом его выполнения будет либо пустая таблица, либо результат выполнения предыдущих разделов табличного выражения, рассматриваемый как одна группа без столбцов группирования.
При написании шаблон заключается в двойные кавычки.
Like «А*» – в поле Фамилия все фамилии, начинающиеся на А.
Like «*/1/99» – в поле Дата – все записи за январь 1999г.
Like «[ABC]*» – в поле Имя – любое имя, начинающееся с указанных букв.
Access агрегатные функции в запросах
Функция– это ранее определенная последовательность действий (программа). В Access можно использовать функции двух видов: стандартные, входящие в состав Access или VBA (140 функций) и пользовательские, которые пользователь пишет сам на языке VBA. Все функции сгруппированы по категориям:
1. Функции даты и времени. Предназначены для управления значениями типа Дата и Время.
Date() – возвращает текущее системное время и дату;
Day() – возвращает целое число от 1 до 31 – день месяца;
Month() – месяц от 1 до 12 значения даты;
Weekday() – возвращает день недели (целое число, воскресенье соответствует 1);
Year() – возвращает год (целое число).
2. Функции преобразования типов данных. Позволяют назначить наиболее подходящий тип данных:
str() – возвращает число в виде строки;
Val() – возвращает число из строки;
Format() – возвращает строку в формате, определенном пользователем.
3. Математические и тригонометрические функции. Выполняют вычисления над числовыми значениями.
Abs() – возвращает абсолютное значение числа;
Sqr() –вычисляет квадратный корень числа;
Fix() – возвращает целую часть числа;
Int() – возвращает первое целое число, меньшее аргумента.
4. Текстовые (строковые) функции. Выполняют операции над текстовыми значениями.
Asc() – возвращает числовой код символа;
Chr() – возвращает символ по числовому коду;
Instr() – возвращает номер позиции знака в тексте;
Left() – возвращает указанное число знаков текста слева;
Right() – возвращает указанное число знаков справа;
Mid() – возвращает указанное число знаков, начиная с указанной позиции.
5. Финансовые функции. Эти функции аналогичны имеющимся финансовым функциям в Excel.
6. Статистические функции. Выполняют групповые операции над набором данных, который содержится в поле формы, отчета или запроса.
В Access предусмотрено 9 статистических функций:
Sum — сумма значений некоторого поля для группы;
Avg — среднее значение некоторого поля для группы;
Max, Min — максимальное или минимальное значение поля для группы;
Count — число значений поля в группе (пустые значения поля не учитываются);
StDev — среднеквадратическое отклонение от среднего;
Var — дисперсия значений поля в группе;
First, Last — значение поля из первой или последней записи.
Логические функции
IIF(условие, значение_если_истина, значение_если_ложь). Запросы могут производить обобщенное групповое значение полей точно также как и значение одного пол. Это делает с помощью агрегатных функций. Агрегатные функции производят одиночное значение для всей группы таблицы. Имеется список этих функций: поля.
Запросы QBE на выборку.
Запросы на выборку не изменяют содержимое базы данных, служат только для отображения данных, отвечающих заданным условиям. Запросы на выборку могут быть следующих видов:
— простой запрос на выборку;
— запрос с параметром;
— запрос с итогами;
— запрос с вычисляемым полем.
Простой запрос на выборку предназначен для извлечения данных из одной или нескольких таблиц и отображения их в режиме таблицы.
Бланк простого запроса содержит шесть строк:
— вывод на экран (указывает, будет ли поле присутствовать в динамическом наборе данных);
— условие отбора (содержит первое условие, ограничивающее набор данных);
— или (содержит другие условия ограничения данных).
— Разработка простого запроса выполняется в несколько этапов:
— выбор полей (добавление полей в запрос);
— установление критериев отбора;
— задание порядка расположения записей (сортировка).
Перекрестный запрос вычисляет сумму, среднее значение, число элементов и значения других статистических функций, группируя данные и выводя их в компактном виде, напоминающем сводную электронную таблицу.
Перекрестный запрос создается с помощью соответствующего мастера или в конструкторе запросов. В бланке запроса указывается, значения каких полей будут использоваться в вычислениях или в качестве заголовков строк и столбцов.
Перекрестный запрос – это специальный тип группового запроса. Строка Групповая операция обязательно должна быть включена.В запросе обязательно должны быть установлены как минимум три параметра – поле заголовка строк, поле заголовка столбцов и поле для выбора значений. Поля, используемые в качестве строк и столбцов, должны содержать функцию Группировка в строке Групповая операция. Для создания запроса необходимо выполнить следующие действия:
— создать новый запрос для таблицы (таблиц), включив в макет нужные поля;
— выполнить команду ЗАПРОС/Перекрестный;
— в строке Перекрестная таблица указать, какое поле используется в качестве заголовков строк, какое – в качестве заголовков столбцов и какое — для выполнения вычислений в соответствии с выбранной групповой операцией;
— в строке Групповая операция поля значений необходимо выбрать итоговую функцию.
Запрос с параметром — это запрос, при выполнении которого в диалоговом окне пользователю выдается приглашение ввести данные, например условие для возвращения записей или значение, которое должно содержаться в поле. Можно создать запрос, в результате которого выводится приглашение на ввод нескольких данных, например, двух дат. В результате будут возвращены все записи, находящиеся между указанными двумя датами.
Запросы с параметрами удобно использовать в качестве основы для создания форм и отчетов. Например, на основе запроса с параметрами можно создать месячный отчет о доходах. При выводе данного отчета, на экране появится приглашение ввести месяц, доходы которого интересуют пользователя. После ввода месяца на экране будет представлен требуемый отчет.
Чтобы создать запрос с параметром, необходимо в строку Условия отбора для заданного поля ввести текст приглашения для ввода данного, заключив его в прямоугольные скобки. Можно задать параметры для нескольких полей или для одного поля определить несколько параметров для отбора, используя запись условия в несколько строк совместно с логической операцией «ИЛИ».
Если в запрос вводится несколько параметров, то порядок их ввода через диалоговое окно определяется порядком расположения полей с параметром в бланке запроса.
Запрос с итогами позволяют производить выборку данных одновременно с их группировкой и вычислением групповых итогов с использованием различных статистических функций.
Для выполнения групповой операции необходимо в режиме конструктора включить в таблицу описания запроса строку Групповая операция и указать в том поле, то поле, по которому должна быть группировка, а в тех полях, по которым должно вестись вычисление заменить слово «группировка» на требуемую статистическую функцию.
Результат запроса с использованием групповых операций содержит по одной записи (строке) для каждой группы, исходные строки групп отсутствуют.
В запросах с итогами можно выполнять следующие операции:
1. Групповые операции над всеми записями. Для этого в полях указываются итоговые функции. Результат запроса представляет собой одну запись, заголовки столбцов соответствуют названию функции и имени поля.
2. Групповые операции для некоторых групп записей. Функция Группировка указывается для полей, по которым будут группироваться данные. В полях, по которым будут выполняться вычисления, должны быть выбраны соответствующие вычислениям функции.
3. Группировку записей, которые соответствуют условию отбора. Для этого необходимо указать условие отбора для поля, где выбрана функция Группировка.
4. Вывод только тех результатов, которые удовлетворяют условию отбора. Для этого условие отбора задается для тех полей, по которым в строке Групповая операция выбрана итоговая функция (например, вывести те группы, средний балл студентов которых больше 4,5).
Запросы QBE — действия.
Выполнение запроса — действия приводит к изменению содержимого базы данных. При выполнении таких запросов следует быть осторожным, так как необдуманное применение этих запросов может привести к необратимой утрате информации в базе данных. Поэтому Access автоматически помечает в окне базы данных запросы — действия символом «!».
При создании запроса Access по умолчанию создает запрос на выборку. При необходимости с помощью команд конструктора запросов можно указать другой тип запроса.
Существует 4 типа запросов на изменение:
— запрос на добавление;
— запрос на обновление;
— запрос на удаление;
— запрос на создание таблицы.
Запрос на добавление позволяет добавлять записи в указанную таблицу, не только текущей базы данных, но и любой другой базы данных. Структура записи таблицы-запроса необязательно должна совпадать со структурой таблицы, в которую будут добавляться записи. Например, в записи запроса может быть меньше полей, если на поля принимающей таблице не наложено требование обязательности их заполнения. Допускается несоответствие типов полей, если возможно преобразование типа данных одного поля в тип данных другого поля.
Для создания запроса необходимо выполнить следующие действия:
— создать запрос на выборку и отладить его (добавить таблицы, значения полей которых будут использоваться для добавления записей);
— отменить свойство Вывод на экран для полей запроса;
— выполнить команду ЗАПРОС/Добавление – для преобразования в запрос на добавление. При этом в бланке запроса появляется строка Добавление. Далее необходимо включить в бланк запроса поля, данные которых будут добавляться в принимающую таблицу. Можно ввести также условия отбора записей для добавления.
— указать имя таблицы, куда будут добавляться записи;
— выполнить команду ЗАПРОС/Запуск.
Если принимающая таблица содержит ключевое поле, то и добавляемые записи должны иметь такое же ключевое поле (по условиям целостности БД).
Технология создания других типов запросов — действий аналогична.
Запрос на обновление позволяет изменить группу записей, отобранную на основе критериев отбора. В запросе на обновление можно указать одно или несколько полей, сделав нужные установки в строке Обновление. Для обновляемого поля в строку Обновление надо ввести значение или выражение, определяющее новое значение. После выполнения открывается диалоговое окно с сообщением о числе обновленных записей.
Запрос на удаление позволяет удалять записи из одной или нескольких таблиц одновременно. Запрос на удаление удаляет записи таблицы, удовлетворяющие критериям отбора, целиком, поэтому если требуется удалить значения отдельных полей записи, следует создать запрос на обновление. В процессе выполнения этого запроса Access отображает данные, которые будут удалены. Для того, чтобы иметь возможность просматривать все поля удаляемых записей, следует перетащить мышью из первой строки списка полей таблицы, записи которой требуется удалить, символ «*» в первую строку бланка запроса, в первый свободный столбец. При этом в этом столбце в строке Поле появится имя таблицы, а в строке с именем Удаление — значение Из.
Запрос на создание таблицы осуществляет создание новой таблицы на основе динамического набора данных. В новой таблице сохраняются имена, типы данных и размеры полей, какими они были в базовых таблицах запроса. Другие свойства полей не наследуются.
Агрегатные функции SQL — SUM, MIN, MAX, AVG, COUNT
Будем учиться подводить итоги. Нет, это ещё не итоги изучения SQL, а итоги значений столбцов таблиц базы данных. Агрегатные функции SQL действуют в отношении значений столбца с целью получения единого результирующего значения. Наиболее часто применяются агрегатные функции SQL SUM, MIN, MAX, AVG и COUNT. Следует различать два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных функций без группировки.
Функция SQL SUM
Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только к столбцам, значениями которых являются числа. Запросы SQL для получения результирующей суммы начинаются так:
После этого выражения следует FROM (ИМЯ_ТАБЛИЦЫ), а далее с помощью конструкции WHERE может быть задано условие. Кроме того, перед именем столбца может быть указано DISTINCT, и это означает, что учитываться будут только уникальные значения. По умолчанию же учитываются все значения (для этого можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке .
Сначала работать будем с базой данных фирмы — Company1. Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными — в файле по этой ссылке .
Пример 1. Есть база данных фирмы с данными о её подразделениях и сотрудниках. Таблица Staff помимо всего имеет столбец с данными о заработной плате сотрудников. Выборка из таблицы имеет следующий вид (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):

Для получения суммы размеров всех заработных плат используем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
Этот запрос вернёт значение 287664,63.
А теперь упражнение для самостоятельного решения. В упражнениях уже начинаем усложнять задания, приближая их к тем, что встречаются на практике.
Пример 2. Вывести сумму комиссионных, получаемых всеми сотрудниками с должностью Clerk.
Функция SQL MIN
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3. База данных и таблица — те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения. В этом и некоторых других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о подразделениях фирмы:

Пример 4. К таблице Staff добавляется таблица Org, содержащая данные о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе, расположенном в Бостоне.
Функция SQL MAX
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда требуется определить максимальное значение среди всех значений столбца.
Пример 5. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения.
Пример 6. Вновь работаем с двумя таблицами — Staff и Org. Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе, относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц).
Функция SQL AVG
Указанное в отношении синтаксиса для предыдущих описанных функций верно и в отношении функции SQL AVG. Эта функция возвращает среднее значение среди всех значений столбца.
Пример 7. База данных и таблица — те же, что и в предыдущих примерах.
Пусть требуется узнать средний трудовой стаж сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
Результатом будет значение 6,33
В следующем упражнении для самостоятельного решения помимо агрегатной функции требуется использовать также предикат BETWEEN.
Пример 8. Работаем с одной таблицей — Staff. Вывести среднюю зарплату сотрудников со стажем от 4 до 6 лет.
Функция SQL COUNT
Функция SQL COUNT возвращает количество записей таблицы базы данных. Если в запросе указать SELECT COUNT(ИМЯ_СТОЛБЦА) . то результатом будет количество записей без учёта тех записей, в которых значением столбца является NULL (неопределённое). Если использовать в качестве аргумента звёздочку и начать запрос SELECT COUNT(*) . то результатом будет количество всех записей (строк) таблицы.
Пример 9. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать число всех сотрудников, которые получают комиссионные. Число сотрудников, у которых значения столбца Comm — не NULL, вернёт следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
Результатом будет значение 11.
Пример 10. База данных и таблица — те же, что и в предыдущих примерах.
Если требуется узнать общее количество записей в таблице, то применяем запрос со звёздочкой в качестве аргумента функции COUNT (на MS SQL Server — с предваряющей конструкцией USE company1;):
Результатом будет значение 17.
В следующем упражнении для самостоятельного решения потребуется использовать подзапрос.
Пример 11. Работаем с одной таблицей — Staff. Вывести число сотрудников в отделе планирования (Plains).
Агрегатные функции вместе с SQL GROUP BY (группировкой)
Теперь рассмотрим применение агрегатных функций вместе с оператором SQL GROUP BY. Оператор SQL GROUP BY служит для группировки результирующих значений по столбцам таблицы базы данных. На сайте есть урок, посвящённый отдельно этому оператору.
Работать будем с базой данных «Портал объявлений 1». Скрипт для создания этой базы данных, её таблицы и заполения таблицы данных — в файле по этой ссылке .
Пример 12. Итак, есть база данных портала объявлений. В ней есть таблица Ads, содержащая данные об объявлениях, поданных за неделю. Столбец Category содержит данные о больших категориях объявлений (например, Недвижимость), а столбец Parts — о более мелких частях, входящих в категории (например, части Квартиры и Дачи являются частями категории Недвижимость). Столбец Units содержит данные о количестве поданных объявлений, а столбец Money — о денежных суммах, вырученных за подачу объявлений.

Агрегатные функции в SQL


- Агрегатные функции используются подобно именам полей в операторе SELECT, но с одним исключением: они берут имя поля как аргумент. С функциями SUM и AVG могут использоваться только числовые поля. С функциями COUNT, MAX и MIN могут использоваться как числовые, так и символьные поля. При использовании с символьными полями MAX и MIN будут транслировать их в эквивалент ASCII кода и обрабатывать в алфавитном порядке. Некоторые СУБД позволяют использовать вложенные агрегаты, но это является отклонением от стандарта ANSI со всеми вытекающими отсюда последствиями.
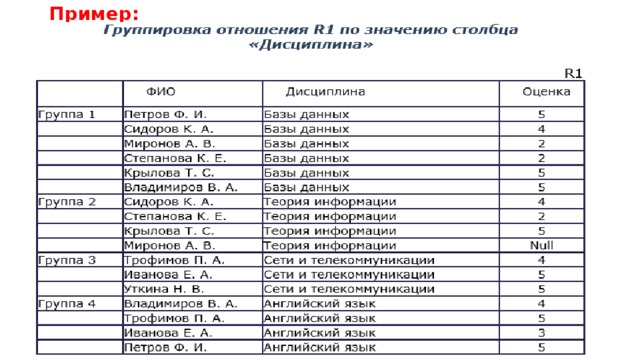
Пример:
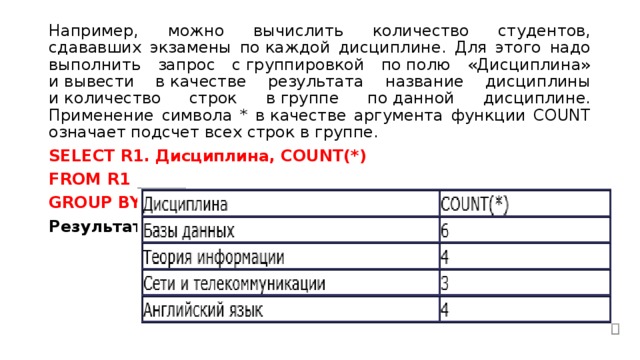
Например, можно вычислить количество студентов, сдававших экзамены по каждой дисциплине. Для этого надо выполнить запрос с группировкой по полю «Дисциплина» и вывести в качестве результата название дисциплины и количество строк в группе по данной дисциплине. Применение символа * в качестве аргумента функции COUNT означает подсчет всех строк в группе.
SELECT R1. Дисциплина, COUNT(*)
FROM R1
GROUP BY R1.Дисциплина;
Результат:

Если требуется сосчитать количество сдавших экзамен по какой-либо дисциплине, то необходимо исключить неопределенные значения из исходного отношения перед группировкой. В этом случае запрос будет выглядеть следующим образом:
SELECT R1.Дисциплина, COUNT (*)
FROM R1
WHERE R1. Оценка IS NOT NULL
GROUP BY R1.Дисциплина;
Результат:

не попадет в набор кортежей перед группировкой, поэтому количество кортежей в группе для дисциплины «Теория информации» будет на 1 меньше.
Аналогичный результат можно получить, если записать запрос следующим способом:
SELECT R1. Дисциплина, COUNT(R1. Оценка)
FROM R1
GROUP BY R1. Дисциплина;
Функция COUNT (ИМЯ АТРИБУТА) считает количество определенных значений в группе, в отличие от функции COUNT(*), которая считает количество строк в группе. Действительно, в группе с дисциплиной «Теория информации» будет 4 строки, но только 3 определенных значения атрибута «Оценка».

Правила обработки значений NULL в агрегатных функциях
Если какие-либо значения в столбце равны NULL при вычислении результата функции они исключаются.
Если все значения в столбце равны NULL , то Max Min Sum Avg = NULL , count = 0 (ноль).
Если таблица пуста, count(*) = 0 .
Можно применять агрегатные функции также и без операции предварительной группировки, в этом случае все отношение рассматривается как одна группа и для этой группы можно вычислить одно значение на группу.
Правила интерпретации агрегатных функций
Агрегатные функции могут быть включены в список вывода и тогда они применяются ко всей таблице.
SELECT MAX (Оценка) from R1 даст максимальную оценку на сессии;
SELECT SUM (Оценка) from R1 даст сумму всех оценок на сеcси;
SELECT AVG(Оценка) from R1 даст среднюю оценку по всей сессии.
 2; Результат: » width=»640″
2; Результат: » width=»640″
Обратившись снова к базе данных «Сессия» (таблицы R1), найдем количество успешно сданных экзаменов:
SELECT COUNT(*) As Сдано _ экзаменов
FROM R1
WHERE Оценка 2;
Результат:
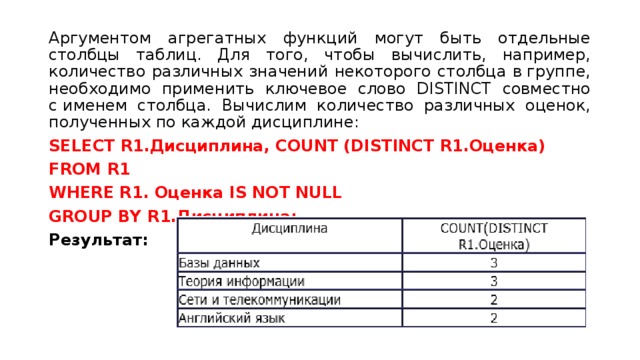
Аргументом агрегатных функций могут быть отдельные столбцы таблиц. Для того, чтобы вычислить, например, количество различных значений некоторого столбца в группе, необходимо применить ключевое слово DISTINCT совместно с именем столбца. Вычислим количество различных оценок, полученных по каждой дисциплине:
SELECT R1.Дисциплина, COUNT (DISTINCT R1.Оценка)
FROM R1
WHERE R1. Оценка IS NOT NULL
GROUP BY R1.Дисциплина;
Результат:

Тот же самый результат получается, если исключить явное условие в части WHERE, в этом случае запрос будет им следующий вид:
SELECT R1. Дисциплина, COUNT(DISTINCT R1. Оценка)
FROM R1
GROUP BY R1. Дисциплина;
Функция COUNT (DISTINCT R1.Оценка) считает только определенные различные значения.
Для того чтобы и в этом случае был получен нужный результат, необходимо сделать предварительное преобразование типа данных столбца «Оценка», приведя его к действительному типу, тогда и результат вычисления среднего не будет целым числом. В этом случае запрос будет выглядеть следующим образом:
 2 Group by R2. Группа, R1. Дисциплина; Здесь функция CAST() выполняет преобразование столбца «Оценка» к действительному типу данных. » width=»640″
2 Group by R2. Группа, R1. Дисциплина; Здесь функция CAST() выполняет преобразование столбца «Оценка» к действительному типу данных. » width=»640″
Select R2.Группа, R1.Дисциплина,Count(*) as Всего, AVG(cast(Оценка as decimal(3,1))) as Средний_балл
From R1,R2
where R1. ФИО = R2. ФИО and R1. оценка is not null
and R1. Оценка 2
Group by R2. Группа, R1. Дисциплина;
Здесь функция CAST() выполняет преобразование столбца «Оценка» к действительному типу данных.

Нельзя использовать агрегатные функции в предложении WHERE, потому что условия в этом разделе оцениваются в терминах одиночной строки, а агрегатные функции — в терминах групп строк.
Предложение GROUP BY позволяет определять подмножество значений в особом поле в терминах другого поля и применять функцию агрегата к подмножеству. Это дает возможность объединять поля и агрегатные функции в едином предложении SELECT. Агрегатные функции могут применяться как в выражении вывода результатов строки SELECT, так и в выражении условия обработки сформированных групп HAVING. В этом случае каждая агрегатная функция вычисляется для каждой выделенной группы. Значения, полученные при вычислении агрегатных функций, могут быть использованы для вывода соответствующих результатов или для условия отбора групп.
Построим запрос, который выводит группы, в которых по одной дисциплине на экзаменах получено больше одной двойки:
 1; Результат: » width=»640″
1; Результат: » width=»640″
SELECT R2. Группа
FROM R1,R2
WHERE R1. ФИО = R2. ФИО AND
R1.Оценка = 2
GROUP BY R2.Группа, R1.Дисциплина
HAVING count(*) 1;
Результат:

Пример: имеем БД «Банк», состоящую из одной таблицы F, в которой хранится отношение F, содержащее информацию о счетах в филиалах некоторого банка:
F = ;
Q = ;
Найти суммарный остаток на счетах в филиалах. Можно сделать раздельный запрос для каждого из них, выбрав SUM (Остаток) из таблицы для каждого филиала, но операция группировки GROUP BY, позволит поместить их все в одну команду:
SELECT Филиал , SUM( Остаток )
FROM F
GROUP BY Филиал;
GROUP BY применяет агрегатные функции независимо для каждой группы, определяемой с помощью значения поля Филиал. Группа состоит из строк с одинаковым значением поля Филиал, и функция SUM применяется отдельно для каждой такой группы, т. е. суммарный остаток на счетах подсчитывается отдельно для каждого филиала. Значение поля, к которому применяется GROUP BY , имеет по определению только одно значение на группу вывода, как и результат работы агрегатной функции.
 5 000; Аргументы в предложении HAVING подчиняются тем же самым правилам, что и в предложении SELECT , где используется GROUP BY . Они должны иметь одно значение на группу вывода. » width=»640″
5 000; Аргументы в предложении HAVING подчиняются тем же самым правилам, что и в предложении SELECT , где используется GROUP BY . Они должны иметь одно значение на группу вывода. » width=»640″
Предположим, что выбрать только те филиалы, суммарные значения остатков на счетах которых превышают $5 000, а также суммарные остатки для выбранных филиалов. Чтобы вывести в результат филиалы, суммарные остатки в которых свыше $5 000, необходимо использовать предложение HAVING. Предложение HAVING определяет критерии, используемые, чтобы удалять определенные группы из вывода, точно так же, как предложение WHERE делает это для индивидуальных строк.
Правильной командой будет следующая:
SELECT Филиал, SUM(Остаток)
FROM F
GROUP BY Филиал
HAVING SUM ( Остаток ) 5 000;
Аргументы в предложении HAVING подчиняются тем же самым правилам, что и в предложении SELECT , где используется GROUP BY . Они должны иметь одно значение на группу вывода.

Следующая команда будет запрещена:
SELECT Филиал,SUM(Остаток)
FROM F
GROUP BY Филиал
HAVING ДатаОткрытия = 27/12/2004 ;
Поле ДатаОткрытия не может быть использовано в предложении HAVING , потому что оно может иметь больше, чем одно значение на группу вывода. Чтобы избежать такой ситуации, предложение HAVING должно ссылаться только на агрегаты и поля, выбранные GROUP BY . Имеется правильный способ сделать вышеупомянутый запрос:
SELECT Филиал,SUM(Остаток)
FROM F
WHERE ДатаОткрытия = ’27/12/2004’
GROUP BY Филиал;

Смысл данного запроса следующий: найти сумму остатков по каждому филиалу счетов, открытых 27 декабря 2004 года.
Как говорилось ранее, HAVING может использовать только аргументы, которые имеют одно значение на группу вывода. Практически ссылки на агрегатные функции — наиболее общие, но и поля, выбранные с помощью GROUP BY, также допустимы. Например, мы хотим увидеть суммарные остатки на счетах филиалов в Санкт-Петербурге, Пскове и Урюпинске:
SELECT Филиал, SUM(Остаток)
FROM F,Q
WHERE F. Филиал = Q. Филиал
GROUP BY Филиал
HAVING Филиал IN (‘Санкт-Петербург’, ‘Псков’, ‘Урюпинск’);
100 000; Если суммарный остаток более чем $100 000, то мы его увидим в результирующем отношении, в противном случае мы получим пустое отношение. » width=»640″
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия отбора в части HAVING есть TRUE. В частности, если раздел HAVING присутствует в запросе, не содержащем GROUP BY, то результатом его выполнения будет либо пустая таблица, либо результат выполнения предыдущих разделов табличного выражения, рассматриваемый как одна группа без столбцов группирования. Рассмотрим пример. Допустим, мы хотим вывести общую сумму остатков по всем филиалам, но только в том случае, если она более $100 000. В этом случае наш запрос не будет содержать операции группировки, но будет содержать раздел HAVING и будет выглядеть следующим образом:
SELECT SUM( Остаток )
FROM F
HAVING SUM( Остаток ) 100 000;
Если суммарный остаток более чем $100 000, то мы его увидим в результирующем отношении, в противном случае мы получим пустое отношение.

При использовании агрегатных функций необходимо помнить, что в результирующем наборе могут присутствовать только значения полей группировки и возможно значения агрегатных функций. Не допустимо группировать по одним значениям, а выводить другие значения. Это будет синтаксической ошибкой.